Regardless how good and flexible the system is, it’s practically impossible to design it in the way that satisfies all customers. Don’t take me wrong – if you have internal development team that works on internal system, you could be fine. But as long as you start to sell the solution or, even better, design the hosting solution for the multiple customers – you are stuck. There is always some customization involved.
One of the very common examples of customization is custom attributes customer wants to store. For example, let’s think about shopping cart system and Article table there. If you put some time trying to define Article attributes you can end up with quite extensive set. Size, Weight, Dimension, Color.. So far so good. But one day sales department close the deal with auto part store and now you have to deal with cylinders, trim types, engine, battery amp-hours and other funny stuff. Next day the company closes the deal with grocery store and you have to deal with nutrition information.
Unfortunately there are no perfect ways to solve the problem. I’m going to show a few obvious and no-so-obvious design patterns that you can use and outline scenarios when those patterns are useful. There will be 3 posts on the suject:
- Today we will talk about storing attributes in the separate columns and about storing them in XML
- We will talk about Name/Value table – there are 2 approaches – very very bad and very very interesting
- We will do some performance testing and storage analysis for those approaches.
But first, let’s define the set of criteria we are going to use evaluating the patterns:
- Multiple schema support. Can this solution be used in hosted environments where you have multiple different “custom fields” schema? For example, customer-specific attributes in the system that stores data from the multiple customers (remember auto parts shop and grocery store)
- Expandability. Does solution offer unlimited expandability in terms of numbers and types of the attributes?
- Online schema change. E.g. can schema be modified online with active users in the system?
- Storage cost. How much storage solution requires?
- Attribute access cost
- Search-friendliness. How easy is to search for specific value in the attributes scope
- Sorting/Paging friendliness. How easy is to sort by specific attribute and display specific page based on row number
- Upfront knowledge of the data schema. What client needs to know about attributes while selecting data.
And before we begin, as the disclaimer. I’m going to show a few patterns but by any means there are other solutions available. Every system is unique and you need to keep your own requirements in mind while choosing the design. Not the best pattern in general could be the best one for specific system and specific requirements.
Pattern 1: One column per attribute
This is probably one of the most common pattern you can find especially in the old systems. There are 3 most common ways how it’s get implemented. In first one, you predefine the set of the custom columns of different types up front and customer is limited by that predefined subset. Something like that (let’s call it 1.a):

Alternatively, there are the systems that dynamically alter the table when customer needs to create the new attribute. Something like that (let’s call it 1.b):

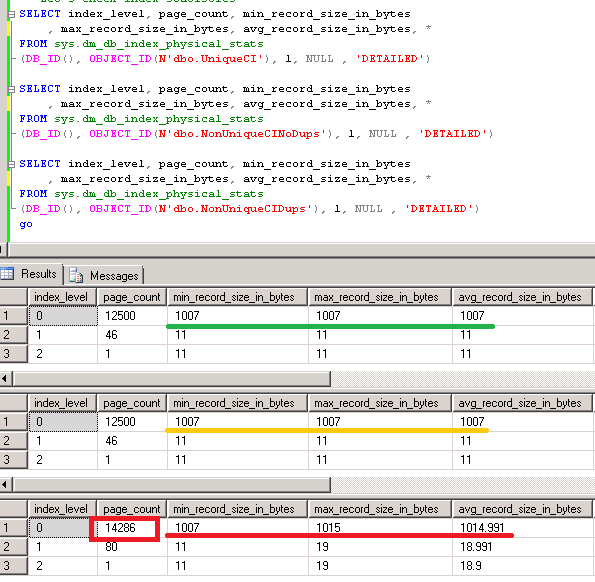
As you can see, I mentioned that rebuilding of clustered index is the good idea. It reduces the index fragmentation due increase of the row size. And if you drop the attribute, you’d need to reclaim the space.
Third variation (let’s call it 1.c) is very similar to 1.b with exception that it stores custom attributes in the separate table:

Let’s evaluate them:
- Multiple schema support. It would work with the multiple schema if/when you have predefined set of the attributes (1.a) from above. Of course, in that case all customers will have the limitation on maximum number of attributes per type but it could be acceptable in some systems. In case if you dynamically alter the table only one schema could be supported. Of course, you can do some tricks with that – for example keep multiple tables (one per customer) or reuse the attribute columns created by other customers but either of those approaches would introduce a lot of complexity and management overhead. It’s simply not worth it.
- Expandability. 1.a obviously is not expandable. At least automatically. 1.b and 1.c offer practically unlimited expandability (subject of SQL Server limitations on max row size and max number of columns).
- Online schema change. 1.a does not require any physical schema changes. 1.b and 1.c require SCH-M lock acquired on the table during table alteration (which is basically exclusive table access) as well as user should have appropriate rights to execute the ALTER TABLE statement.
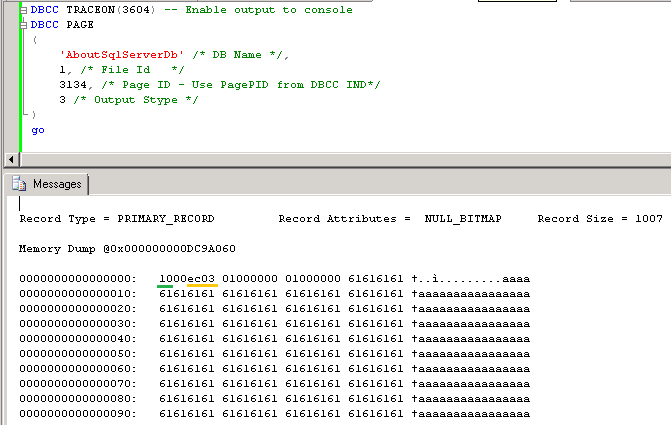
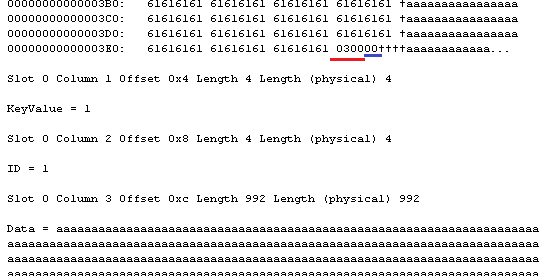
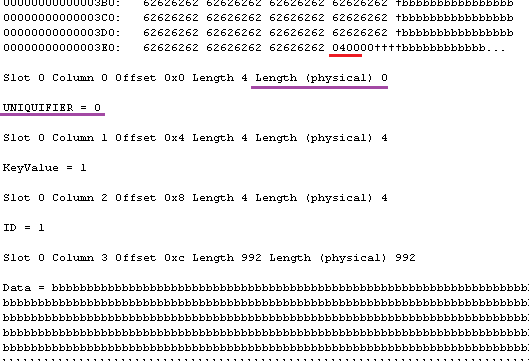
- Storage cost. 1.a – it increases the size of the row in Articles table by the size of all fixed-width data types used by attributes plus at least 2 bytes per variable width attribute regardless if attributes are used or not (see it in more details). This could be OK as long as the table is not transactional (does not store a lot of data) and we are not going crazy with total number of attributes we predefined, but still – it needs to be considered. Row size matters. 1.b and 1.c are much more efficient in that regard – attributes are created only when needed.
- Attribute access cost. 1.a and 1.b – no overhead at all. Attribute is in the regular column in the row. 1.c – there is the extra join between the tables
- Search-friendliness. Generally this would introduce the search clause like: where (CustomText1 = @P1) or (CustomText2 = @P1) .. Usually those patterns lead to clustered index scans unless there are predicates selective enough to utilize non clustered index. So this is more or less the question if system even need to allow search like that without any additional filters on other columns. One other thing to keep in mind – you need to be careful dealing with various data types and possible conversion errors.
- Sorting/Paging friendliness. That pattern is extremely friendly for sorting and paging as long as there are some primary filters that limit number of rows to sort/page. Otherwise attribute either needs to be indexed or scan would be involved.
- Upfront knowledge about the data schema generally is not required. While select * is not the best practice, it would work perfectly when you need to grab entire row with the attributes.
The biggest benefits of that design are simplicity and low access cost. I would consider it for the system that require single data schema (box product) or when multiple data schema would work with limited number of attributes (1.a). While it can cover a lot of systems, in general it’s not flexible enough. I would also be very careful with that pattern in case if we need to add attributes to transactional tables with millions or billions of rows. You don’t want to alter those tables on the fly nor have storage overhead introduced by predefined attributes.
One other possible option is to use SPARSE columns with 1.a and 1.b. SPARSE columns are ordinary columns that optimized for the storage of NULL values. That will technically allow you to predefine bigger set of the attributes than with regular columns without increasing the size of the row. Could be very useful in some cases. Same time you need to keep in mind that not null SPARSE column takes more space than regular column. Another important thing that tables with SPARSE columns cannot be compressed which is another very good way to save on the storage space.
And the last note about the indexing. If you need to support search and/or sort on every attribute you need to either limit the number of rows to process or index every (or most commonly used) attributes. While large number of indexes is not very good thing in general, in some system it’s perfectly OK (especially with filtered indexes that do not index NULL values), as long as you don’t have millions of rows in the table nor very heavy update activity. Again, this is from “It depends” category.
Pattern 2. Attributes in XML
Well, that’s self-explanatory :). Something like that:

Let’s dive into the details.
- Multiple schema support. Not a problem at all. You can store whatever you want. As long as it’s the valid XML
- Expandability. The same. Not a problem at all. Just keep the valid XML and you’re golden
- Online schema change. Easy. There is no schema on the metadata level. Well, you can, of course, define XML Schema and it will help with performance but again, consider pros and cons of this step.
- Storage cost. And now we started to talk about negative aspects. It uses good amount of space. XML is basically LOB – SQL Server does not store it in plan text – there are some minor compression involved but still. It uses a lot of space. And if we need to index XML column, it would require even more space
- Attribute access cost. Heh, and this is another big one. That’s great that SQL Server has build-in XML support. But performance is far from ideal. We will do some performance testing in Part 3 of our discussion but trust me – shredding XML in SQL Server is slow and CPU intensive.
- Search-friendliness. Well, you need to shred it before the search – it’s very slow. XML Indexes would help but it’s still slower than regular columns and introduce huge storage overhead.
- Sorting/Paging friendly. Same as above. You need to shred data first.
- Upfront knowledge about data schema. All data stored in 1 column. So client does not need to jump through any hoops to access the data. But of course, it needs to know how to parse it.
Bottom line – storing custom attributes in XML is the perfect solution in terms of flexibility. Unfortunately it’s very storage-hungry and most importantly very slow in terms of performance. That solution is the best if the main goal is simple attribute storage and displaying/editing very small amount of rows on the client. For example Article detail page on the web site. Although if you need to shred, sort, filter the large number of rows – you’ll have performance issues even with XML Indexes.
Next time we will talk about Name/Value table that deserves the separate post.