Two week ago we discussed 2 “optimistic” transaction isolation levels – Snapshot and Read Committed Snapshot. We already saw how those isolation levels can provide us transaction and statement level consistency reducing blocking issues same time. Sounds too good to be true..
So does it make sense to switch to optimistic isolation levels? Well, the answer is typical – “it depends”. There are a few things you need to keep in mind before you make the decision. Let’s talk about them from both – DBA and Database Developer standpoints.
First of all, as we already know, optimistic isolation levels use tempdb for the version store. When you modified the row, one or more old versions of the row is stored in tempdb. This leads to the higher tempdb load as well as to the larger tempdb size. Would it be the issue for your system? Again, it depends. As the bare minimum you should reserve enough space for tempdb and closely monitor the load. There are a few performance counters under <SqlInstance>:Transactions section that related to the version store – they will show you version store size, generation and cleanup rates and a few other parameters. Those are very useful and I recommend to add them to your baseline.
Second thing you need to keep in mind is that SQL Server needs to store additional 14 bytes pointer to the version store in the. It’s not only increasing the row size, it also can introduce page splits. Let’s take a look. Let’s use the same database from the last blog post – you can download it from the last post.
Let’s rebuild the index (with default FILLFACTOR=100) and look at the index statistics (click on the image to open it in the different window). As you can see, it has 0% fragmentation. Row size is 215 bytes.


Now let’s run transaction in snapshot isolation level and update Value column. This is integer (fixed width column) so this update by itself should not increase row size. If you look at the index statistics now, you can see that there were heavy page splits and row size increased by 14 bytes. Those 14 bytes is the pointer to the version store.


The bottom line – if you use optimistic isolation level, don’t use 100% fillfactor for the indexes.
Speaking of development challenges – well, it’s become a little bit more interesting. First potential program is referential integrity based on triggers. Let’s take a look. Let’s create 2 tables – MasterData and DetailData and after insert trigger on DetailData. In this trigger let’s check that master data exists and rollback transaction in case of referential integrity violation. Let’s test that:

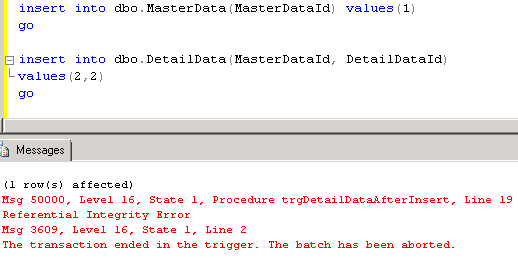
Now let’s move to more complex scenario and 2 sessions. First, let’s start transaction in the 1st session and check if we have MasterData row.

Let’s keep transaction open and in the second session let’s delete master data row. As you see everything is just fine.

Next, lets come back to the first session and insert detail row that references the master row – as you can see there is no errors but referential integrity has been compromised.

It happens because inside the trigger we still are in the context of the old transaction where we reference old version of MasterData row from the version store. This could be easily fixed in the trigger by using (READCOMMITTED) query hint but of course you should remember it and modify the code. It worth to mention that regular referential integrity based on foreign keys uses read committed isolation level by default.

Another issue is the update of the same row. Let’s take a look. first let’s reset Master and Detail table data. Now let’s start transaction in the first session and query the data

Next, let’s update data row in another transaction from another session

And now let’s try to update the same row from the first session and commit the transaction.
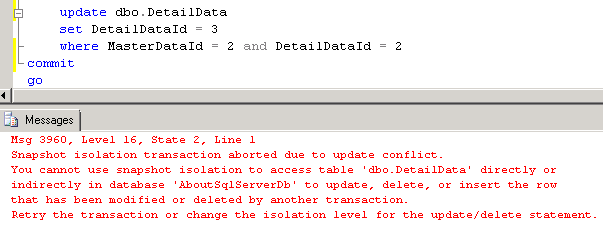
As you can see, behavior is completely different from the regular pessimistic isolation levels – it raises the exception. So obviously the client application needs to catch those errors and either notify users or implement some sort of retry logic to handle it.
And finally let’s look at the different update behavior in snapshot isolation mode. Let’s start the transaction assuming we have 2 rows in the table

Next, in another session let’s run update that changes DetailDataId to 2 for the first row.

Now in the first session let’s do the opposite action and check results

As you see, because of the row versioning it simply swaps the values. It would be completely different with regular pessimistic isolation levels when one session would be blocked and next update either 0 or 2 rows (depend on what session acquires the lock first). The bottom line – if you move your application to snapshot isolation level, you need to test how it would behave in environment with the multiple users. Otherwise you’d have a few nice side effects.
So to summarize – optimistic isolation levels are great but you have to keep a few things in mind:
- Extra tempdb load
- Possible page splits/fragmentations due bigger row size
- Referential integrity based on triggers does not work unless read committed hint is used
- There are different behaviors for updates when multiple sessions update the same rows and when scan is involved.
Source Code is available for download
Nice, very nice indeed. Thanks for deeply thinking about things such as this and publicly sharing it.
Good writing is working hard and covering edge issues.
Daniel
Pingback: Locking in Microsoft SQL Server-What isolation level should I choose? – Site Title