We already know what are the most important lock types and how transaction isolation levels affect locking behavior. Enough theory – today I’d like to show you simple example why blocking typically occurs in the system.
First, let’s create the table and populate it with the data.
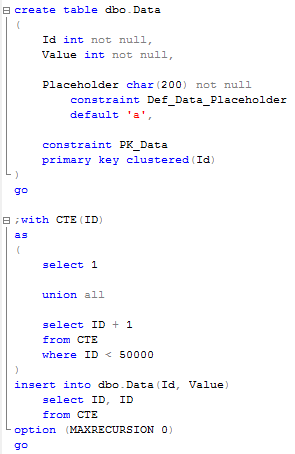
As you can see, this table has 50,000 rows now and 1 clustered index on ID column. Now let’s start another session and run update statement that acquires the lock (update row with ID = Value = 40000). I’m using read committed isolation level but that behavior occurs in any pessimistic isolation level (read uncommitted, read committed, repeatable read and serializable).
Next, let’s take a look at the list of the locks in the system with sys.dm_tran_locks DMV. I don’t have any other activity in the system but in your case, you can filter results by request_session_id if needed.


So we can see 3 active locks: exclusive lock on key (row) level and 2 intent-exclusive locks on the page and table levels.
Now let’s open another session and run select with filter on ID column in the read committed isolation level (you’ll experience the same behavior in repeatable read and serializable isolation levels). This select executes just fine with clustered index seek in the plan.


Now let’s change select and replace filter on ID column with filter on Value column. This select should return the same 1 row but it you run it, it would be blocked.
![]()
If we query sys.dm_tran_locks again, we can see that the second session is waiting to acquire shared lock.

Let’s terminate the select and take a look at estimated execution plan.

As you can see, the plan changes to clustered index scan. We know that this select returns only 1 row from the table but in order to process the request, SQL Server has to read every row from the table. When it tries to read updated row that held exclusive lock, the process would be blocked (S lock is incompatible with X/IX locks). That’s it – blocking occurs not because multiple sessions are trying to update the same data, but because of non-optimized query that needs to process/acquire lock on the data it does not really need.
Now let’s try to run the same select in read uncommitted mode.

As you can see – select runs just fine even with scan. As I already mentioned, in read uncommitted mode, readers don’t acquire shared locks. But let’s run update statement.
![]()
It would be blocked. If you take a look at the lock list, you’ll see that there is the wait on update lock (SQL Server acquires update locks when searches for the data for update)

And this is the typical source of confusions – read uncommitted mode does not eliminate blocking – shared locks are not acquired, but update and exclusive locks are still in the game. So if you downgraded transaction isolation level to read uncommitted, you would not completely solve the blocking issues. In addition to that, you would introduce the bunch of consistency issues. The right way to achieve the goal is to illuminate the source of the problem – non-optimized queries.
Next time we will talk how to detect such queries.
Source code is available here
USE AdventureWorks2014
GO
BEGIN TRAN
UPDATE [Sales].[SalesOrderDetail] SET OrderQty = 100 WHERE SalesOrderID = 43659 and SalesOrderDetailID = 1
SELECT resource_type, request_mode, resource_description FROM sys.dm_tran_locks
WHERE resource_type ‘DATABASE’
–ROLLBACK
— New Session
update [Sales].[SalesOrderDetail] set OrderQty = 120 where SalesOrderID = 43660 — commit
update [Sales].[SalesOrderDetail] set OrderQty = 120 where SalesOrderID = 43659 and SalesOrderDetailID = 2 — (2 to 12) wait why ?
Hi Ali,
I do not have a copy of AdventureWorks2014 with me but here is what I am guessing. The first session places (X) lock on the row with SalesOrderId=43659 and SalesOrderDetailID=1. The second session is trying to update another row for the same SalesOrderID. It is entirely possible that it is trying to evaluate if the first row with (X) lock held needs to be updated and hit (U)/(X) incompatibility. You need to look at execution plan of the second query – is it the index seek with both columns as the predicates or is it range scan? Also, check what other locks first session helds and what second session is trying to acquire.
Sincerely,
Dmitri
I have a couple of questions:
1. Why does when we updated with where clause on Value column request status is “WAIT” for the resource type PAGE and not KEY (However, in the next update statement we can see “WAIT” for KEY resource type though the filter is still on the Value column). I am confused between these two things.
2. In the second example with a select statement with filter on Value column, we can see two rows for session_id = 53, resource_Type = Page but one with request_status GRANT and other with Wait.
Hi Deepak,
SQL Server may “optimize” locking and don’t go to row level. In the first case (SELECT WHERE VALUE=?), SQL Server knows that it will need to scan all rows in the table and obtain (S) locks on each row from the page and release row locks right after rows were read. It decided to use page-level (S) lock instead to avoid row-lock overhead. You can control it with ALLOW_PAGE_LOCK index option or ROWLOCKS hint.
When we update the data SQL Server does not want to lock the page because it does not know how many rows on the page will be updated and moreover, locks need to be held until end of transaction. So it uses row-locks rather than lock entire page with full lock. Again, row lock management is less important than concurrency here.
As for second question – I suspect it is another page (need to look at resource_descriptor). Not sure why it was not released immediately in this scenario.
Hope it explains the situation.
Dmitri