Last time we saw how row size affects performance during the scan operations. I hope you have not altered columns in your tables already. Please don’t blame me if you did – most likely it made the situation even worse. So let’s talk about table alteration today.
There are 3 types of the alterations:
1. Metadata only. This type of alteration can be done based on metadata only. For example, it happens when you add new nullable column, increase the size of variable-width column, change not null column to nullable, etc
2. Metadata change with data check. For example if you need to change nullable column to not null, SQL Server needs to check that there are no rows with null values for this column and after it update the metadata. Decrease of variable-width column is another example – SQL Server needs to check that there are no values larger than the new size
3. Every row needs to be rebuild. Example is: adding new not null column, some data type changes and so on.
Unfortunately one thing is not commonly known – alteration of the table never (repeat) never decreases the row size. When you drop the column, SQL Server removes column from the metadata but does not reclaim/rebuild the row. When you change column type from int to tinyint, for example, actual storage size remains intact – SQL Server just checks domain value on insert/update stages. When you increase the size of the field (for example change int to bigint), SQL Server creates another bigint column and keep old int column space intact.
Let’s see that in details. Let’s create the table:
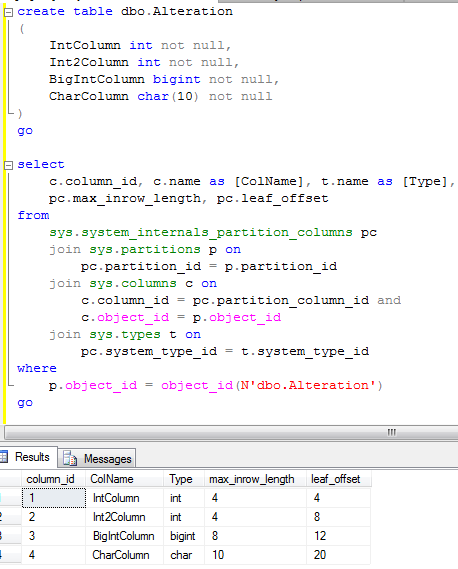
First, let’s drop Int2Column
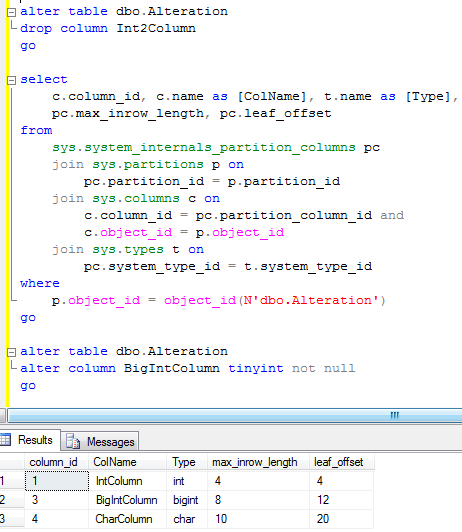
As you can see, column definition is gone although all offsets remain the same. 4 bytes simply wasted.
Next, let’s alter Bigint data type to tinyint
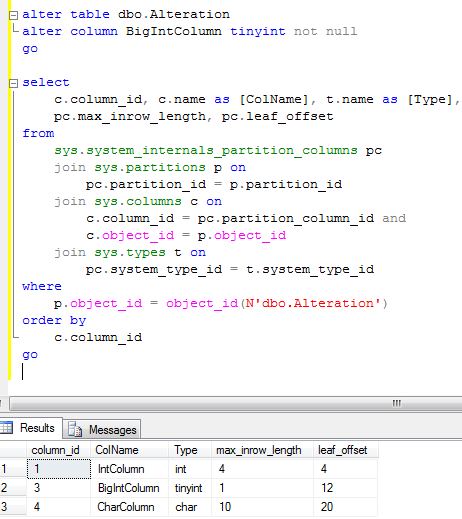
As you can see, column now accepts only 1 byte (max_inrow_length) although still uses 8 bytes in offsets. So another 7 bytes are wasted.
And finally let’s alter IntColumn from int to bigint.
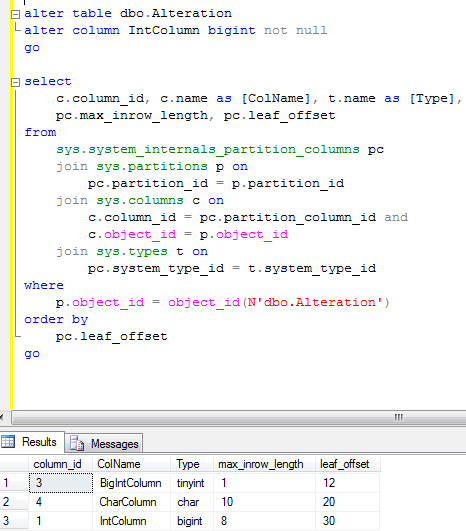
As you can see, even if IntColumn column_id still equal 1, SQL Server “moves” column to the end of the row – new offset is 30. As you can see now, data row has 15 bytes wasted (4 – 11, 13 – 19).
How to “fix” that? Well, you need to rebuild clustered index. SQL Server will reclaim all space and rebuild the rows when you do that. With Heap tables you’re out of luck. Only workaround is build temporary clustered index (which rebuilds the table) and drop it after that.
The biggest problem with that – clustered index rebuild is time consuming operation which locks the table. If you have huge transaction table – it would be nearly impossible to accomplish. So be careful when you design the table structure
Hi
suppose there is some rows in Alteration.
how can i rebuild clustered index without missing rows?
please guide me in code.
Thanks in advance. Morteza
Morteza, I’m sorry I don’t understand your question. What you mean by “missing rows”?
You can rebuild the clustered index with:
alter index on rebuild
Keep in mind this is time consuming operation on the large table that requires table lock (that makes table inaccessible)
Hi
thank you ,I looked for alter index on rebuild.
I mean, Do rows have been deleted after rebuild or no? but i khow now.