One of very interesting phenomenon we have not discussed earlier when we covered lock types and isolation levels is duplicate readings. As we already know, read committed isolation level protects us from reading of modified and uncommitted data but the scope of protection is “this row/right now”. So what happens if row updates during the time when query is executed.
Let’s take a look. First, as usual, let’s create the table and populate it with 100,000 rows:

As you can see, even if we don’t have any unique constraints, that table has unique ID and Value columns (equal to each other) with values from 1 to 100,000. We can even run SQL query and see that there is no duplications.

Now let’s start another session and lock one row:

As you can see, we don’t commit transaction, so exclusive (X) lock is in play. Now let’s start another session, create temporary table and simply copy data from our main table there. When we run this statement in read committed mode, it would be blocked because there it tries to acquire shared (S) lock on the row that held (X) lock from the previous session.

Now let’s come back to the previous session and update another row (value column this time) and commit transaction.
![]()
As you can see, first (X) lock has been released and our blocked session resumes and finishes copying the data. And now, let’s see what we have in this table –

Surprise! We have 1 extra row – the one the first session updated. This row appears twice – with old and new values in Values column. In order to understand what happened, let’s take a look at the execution plan for insert/select statement.
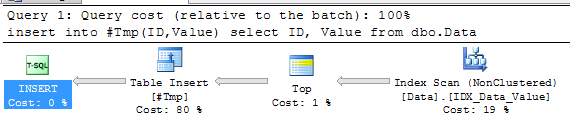
As you can see, plan uses index scan. Let’s think what happened – select read first 999 rows (with ID from 1 to 999) and was blocked by (X) lock from the different transaction. Next, that transaction updated Value column for the row with ID = 1. Because Value is the index key, that index row has been moved in the index. As result, when select resumes, it read this row (with ID = 1) second time during remaining part of the index scan. Fun?
With read uncommitted another factor could come in play – sometime SQL Server can decide to use allocation scan. There are a lot of factors that can lead to that decision – but if it happens and if you’re lucky enough to have page split during query execution, you can easily have rows to be read/processed more than once.
Fortunately neither of those cases happen quite often. I’d say I saw duplicate readings in production systems maybe 2-3 times during my career. But it could give you a lot of grey hairs – think what if #Temp table had primary key on ID and you would get primary key violation on the data that guaranteed to be unique? If you want to be protected from that you have to use optimistic isolation levels. I (promise another time) is going to blog about them next time 🙂
Source code is available for download