We all already know that in most part of the cases deadlocks happen due non-optimized queries. Today I’d like to show another pattern that could lead to the deadlocks. It’s not something that happens very often but it’s worth to mention.
Let’s think about the following scenario. Assuming you have the system that collects some data from the users. Assuming the data has a few parts that can be processed and saved independently from each other. Also let’s assume that there is some processing involved – let’s say there is a raw data part and something system needs to calculate based on that.
One of the approaches to architect the system is separating those updates and processing to the different threads/sessions. It could make sense in some cases – data is independent, threads and sessions would update different columns so even if they start updating the row simultaneously, in the worst case one session would be blocked for some time. Nothing terribly wrong as long as there are no multiple updates of the same row involved. Let’s take a look.
First, let’s create the table and populate it with some data:

Now let’s run the first session, open transaction and do the update of RawData1 column. Also, let’s check the plan. This update statement used non-clustered index seek/key lookup – keep this in mind, it would be important later.

Now let’s run the second session that updates different column on the same row. Obviously this session is blocked – first session holds (X) lock on the row.

Now let’s come back to the first session and try to update another column on the same row. This is the same session that holds (X) row so it should not be the problem.

But.. We have the deadlock.

Why? Let’s take a look at deadlock graph (click to open the new window)
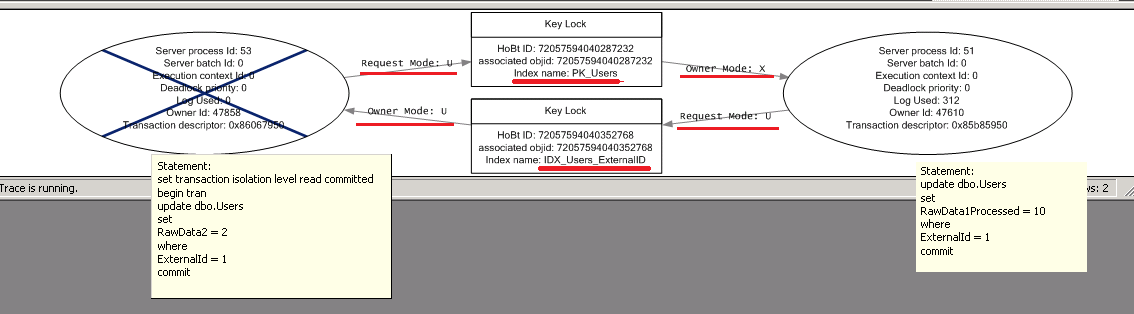
So on the right we have the first session. This session holds the (X) lock on the clustered index row (PK_Users). When we ran the session 2 statement, that session obtained (U) lock on non-clustered index row (IDX_Users_ExternalID), requested (U) lock on the clustered index and was blocked because of the first session (X) lock. Now, when we ran the second update statement from the first session, it tries to request the (U) lock on the non-clustered index and obviously was blocked because the second session still holds (U) lock there. Classic deadlock.
As you can see, it happened because SQL Server uses non-clustered index seek/key lookup as the plan. Without non-clustered index seek everything would work just fine.
This is quite interesting scenario and you can argue that it does not happen often in the real life. Well, yes and no. If we think about 2 update statements in the row – yes – usually we don’t write code that way. But think about stored procedures. If the processing can be done/called from a few different places, you can decide to put the update to the stored procedure. And here you go.
But most importantly – there are the triggers. What if you have AFTER UPDATE trigger and want to update some columns from there. Something like that:

Now let’s run update statement in the first session.

And in the second session.

Deadlock again. You can notice that I used ExternalId and as result non-clustered index seek/key lookup plan there. It does not make a lot of sense in this scenario – I could use UserId there and avoid the problem. So if you have to update original row from the trigger – be careful and write the query in the way that introduces clustered index seek.
Source code is available for download