If you read my blog for some time, you could see that I’m a bit addicted to that subject. But I saw quite a few cases when people started to have performance issues and very suboptimal plans with non-clustered indexes after they partitioned the tables. I’ve already blogged about that problem in general here as well as demonstrated one of the workarounds for one particular case. Today I want to show how to make that workaround a little bit more clean and clear as well as generalize that approach a little bit.
Before we begin, please take a few minutes to read and refresh my previous post. It defines the problem and explains why we have the issue with the index. You also need the script to recreate the data.
First, I’d like to show another method how we can achieve the similar goal. Similarly to the previous example we would like to force index seek on each individual partition using $Partition function and merge the results. But instead of union data from multiple CTEs we can use sys.partition_range_values view. Main idea is to find how many partitions do we have there and then use cross apply with filter on $Partition function. Something like that (click on the image to open it in the different window):



As you can see, the plan looks quite different than before but at the end it achieves the same results with the method with multiple CTEs. And it has the benefit – technically with that approach you don’t need to be limited by number of partitions or, better say, large number of partitions don’t generate very large select statement. On the other hand, there is the potential problem with statistics
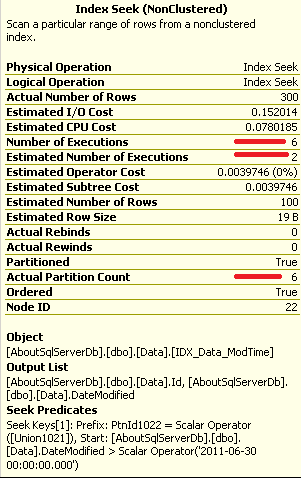
As you can see, SQL Server expected to execute index seek just 2 times but we have 6 partitions here. Well, even if sysobjvalues table has column level statistics on value column, it would not help us much here. We can, of course, try to help SQL by removing join with sys.partition_functions; but still.. It could be incorrect.
If we know that we have static and small number of partitions we can do something like that – just use numbers:



Of course, even if number of partitions is large, there is always dynamic SQL if you want to use it. You can construct numbers in the Boundaries CTE with that.
That $Partition function is the great way to force index seek within the each partitions. And I would like to show you another example that can be beneficial in the case when table is partitioned by “values”, not by “intervals”. E.g. when every partition boundary specifies actual and single value and the # of distinct partition values is the same with the boundaries. Sounds a bit confusing? Let’s see the example. Assuming you’re collecting the data by postal/zip codes (some transactions in the areas) and partition transaction table by postal code. Something like below:

As you can see, table has aligned non-clustered index on TranAmount. Now, let’s say we would like to find max transaction amount per postal code. On the physical level we would like to get Max TranAmount per partition. Below are 2 select statements – first is the classic approach. Second one is using $Partition function.

Now let’s look at the plans. First select just scans entire index – 2.2M rows needs to be processed

Second select introduces separate top 1 “scan” on each partition.

And you can compare Statistics IO here.

Again, $Partition function works great – just be very careful with that implementation. You need to make sure that SQL Server is unable to generate a good plan before you do any tricks. Otherwise you can end up in the worse situation than with the standard method. And of course, it’s nightmare to support. Or, perhaps, you want to call it job security 🙂
Source code is available for download
This use of cross apply over $partition is db programming at its finest, well done.
Thank you, Jean!