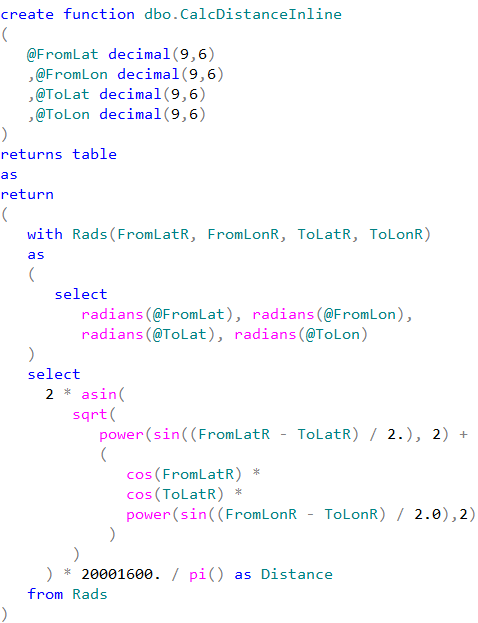
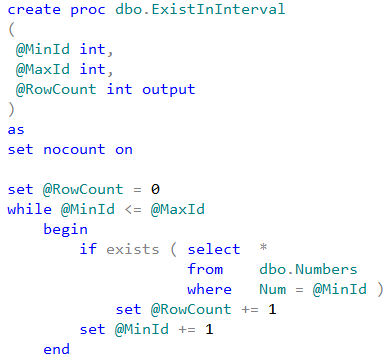
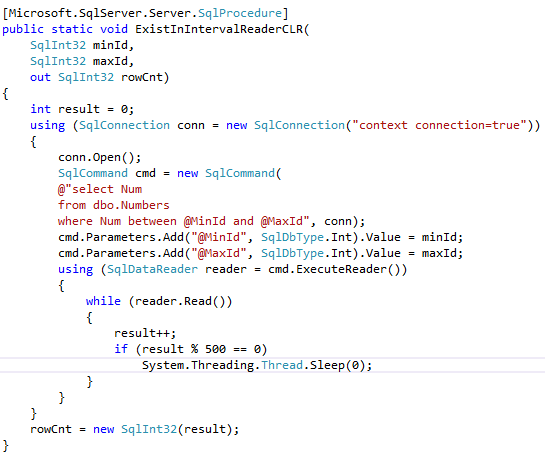
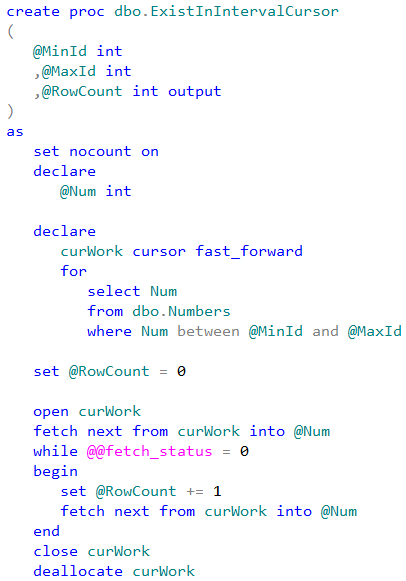
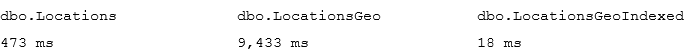As strange as it sounds, I have never considered transaction management to be the topic that requires explanation. However, it seems that some aspects of it are confusing and may benefit from the separate, long overdue, blog post.
Transaction Types
There are three types of transactions in SQL Server – explicit, autocommitted and implicit.
Explicit transactions are explicitly controlled by the code. You can start them by using BEGIN TRAN statement. They will remain active until you explicitly call COMMIT or ROLLBACK in the code.
In case, when there are no active transactions present, SQL Server would use autocommitted transactions – starting transactions and committing them for each statement it executes. Autocommitted transactions work on per-statement rather than per-module level. For example, when a stored procedure consists of five statements; SQL Server would have five autocommitted transactions executed. Moreover, if this procedure failed in the middle of execution, SQL Server would not roll back previously committed autocommitted transactions. This behavior may lead to logical data inconsistency in the system.
For the logic that includes multiple data modification statements, autocommitted transactions are less efficient than explicit transactions due to the logging overhead they introduce. In this mode, every statement would generate transaction log records for implicit BEGIN TRAN and COMMIT operations, which leads to the large amount of transaction log activity and degrade performance of the system.
There is another potential performance hit caused by excessive number of autocommitted transactions. As you know, SQL Server implements Write-Ahead Logging to support transaction durability hardening log records on-disk synchronously with data modifications. Internally, however, SQL Server batches log write operations and caches log records in memory in small 60KB structures called log buffers. COMMIT log record forces SQL Server to flush log buffers to disk introducing synchronous I/O operation.
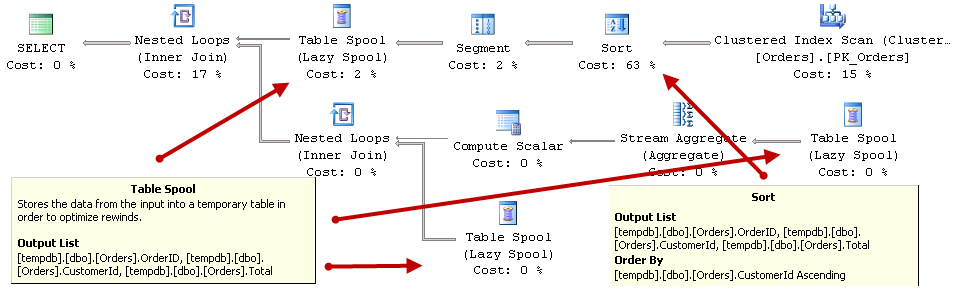
Figure 1 illustrates this condition. INSERT_1, UPDATE_1 and DELETE_1 operations run in autocommitted transactions generating additional log records and forcing log buffer to flush on each COMMIT. Alternatively, INSERT_2, UPDATE_2 and DELETE_2 operations run in implicit transaction, which leads to more efficient logging.
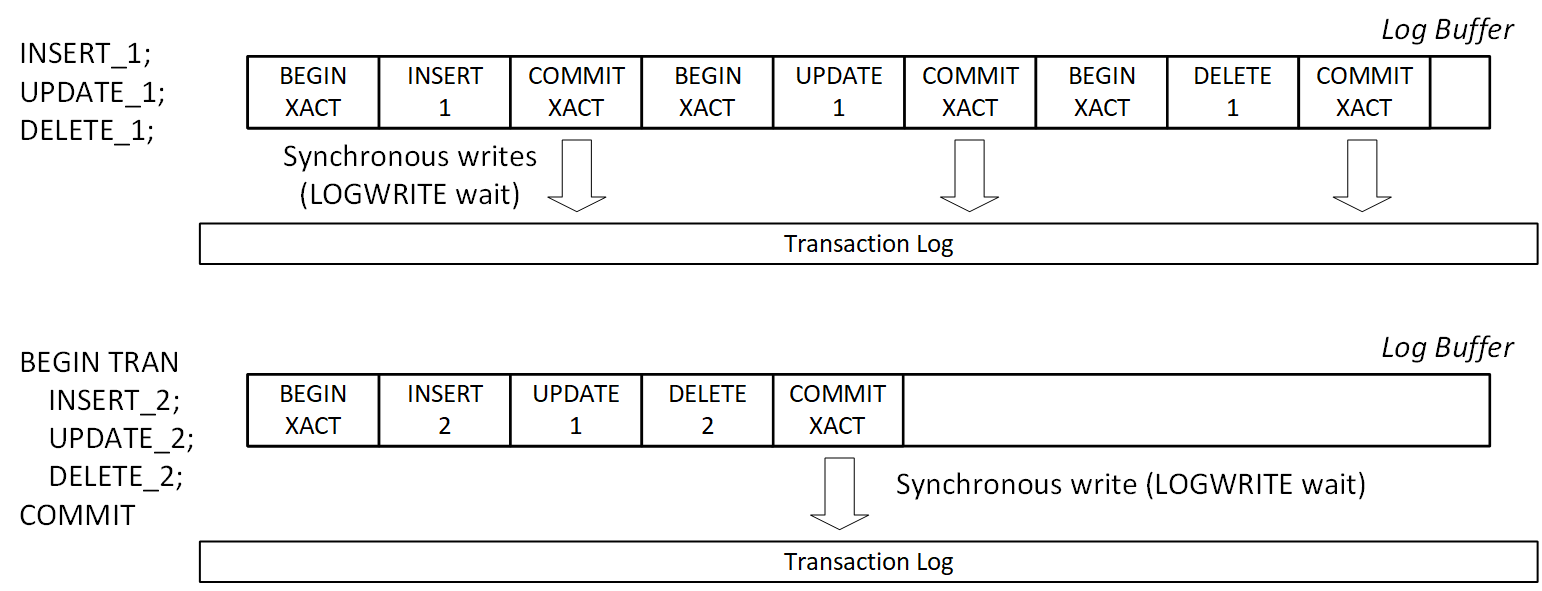
01. Transaction Logging with Autocommitted and Explicit Transactions
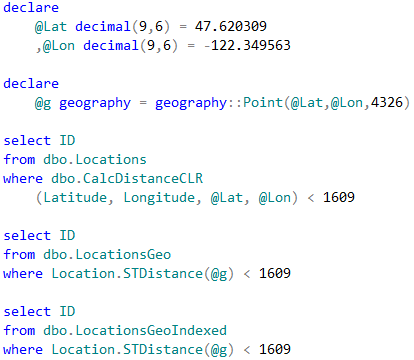
You can run the code below to see this overhead in action. It performs INSERT/UPDATE/DELETE sequence 10,000 times in the loop in autocommitted and explicit transactions respectively, measuring execution time and transaction log throughput with sys.dm_io_virtual_file_stats view.
create table dbo.TranOverhead
(
Id int not null,
Col char(50) null,
constraint PK_TranOverhead
primary key clustered(Id)
);
-- Autocommitted transactions
declare
@Id int = 1,
@StartTime datetime = getDate(),
@num_of_writes bigint,
@num_of_bytes_written bigint
select @num_of_writes = num_of_writes, @num_of_bytes_written = num_of_bytes_written
from sys.dm_io_virtual_file_stats(db_id(),2);
while @Id < 10000
begin
insert into dbo.TranOverhead(Id, Col) values(@Id, 'A');
update dbo.TranOverhead set Col = 'B' where Id = @Id;
delete from dbo.TranOverhead where Id = @Id;
set @Id += 1;
end;
select
datediff(millisecond, @StartTime, getDate()) as [Exec Time ms: Autocommitted Tran]
,s.num_of_writes - @num_of_writes as [Number of writes]
,(s.num_of_bytes_written - @num_of_bytes_written) / 1024 as [Bytes written (KB)]
from
sys.dm_io_virtual_file_stats(db_id(),2) s;
go
-- Explicit Tran
declare
@Id int = 1,
@StartTime datetime = getDate(),
@num_of_writes bigint,
@num_of_bytes_written bigint
select @num_of_writes = num_of_writes, @num_of_bytes_written = num_of_bytes_written
from sys.dm_io_virtual_file_stats(db_id(),2);
while @Id < 10000
begin
begin tran
insert into dbo.TranOverhead(Id, Col) values(@Id, 'A');
update dbo.TranOverhead set Col = 'B' where Id = @Id;
delete from dbo.TranOverhead where Id = @Id;
commit
set @Id += 1;
end;
select
datediff(millisecond, @StartTime, getDate()) as [Exec Time ms: Explicit Tran]
,s.num_of_writes - @num_of_writes as [Number of writes]
,(s.num_of_bytes_written - @num_of_bytes_written) / 1024 as [Bytes written (KB)]
from
sys.dm_io_virtual_file_stats(db_id(),2) s;
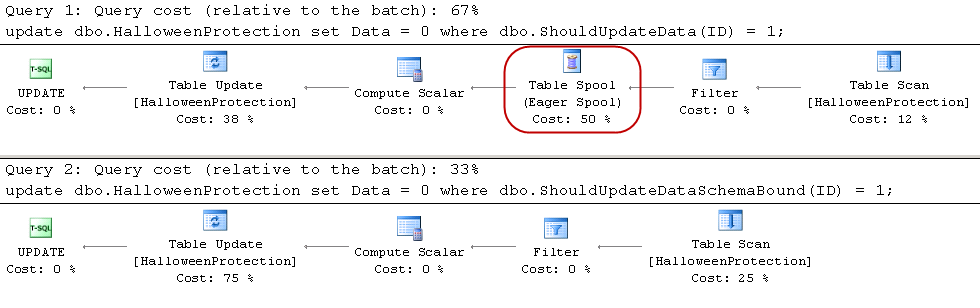
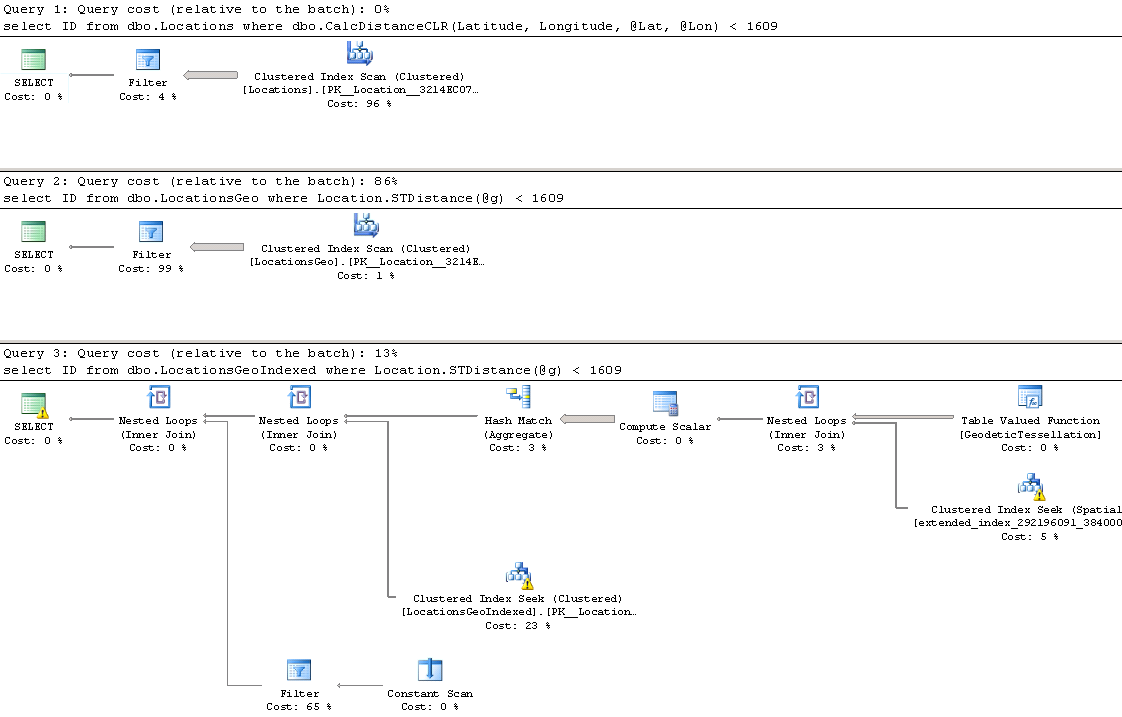
In my environment and this test, explicit transactions are about two times faster and generated three less log activity than autocommitted ones as shown in Figure 2.

02. Explicit and Autocommitted Transaction Performance
As the side note, SQL Server 2014 and above allows you to improve transaction log throughput by using delayed durability. In this mode, SQL Server does not flush log buffers when COMMIT log records are generated. This reduces the number of disk writes at cost of potential small data loss in case of disaster.
SQL Server also supports implicit transactions, which you can enable with SET IMPLICIT_TRANSACTION ON statement. When this option is enabled, SQL Server starts the new transaction when there is no active explicit transactions present. This transaction stays active until you explicitly issue COMMIT or ROLLBACK statement.
Implicit transactions may make transaction management more complicated and they are rarely used in production. However, there is the caveat – SET ANSI_DEFAULT ON option also automatically enables implicit transactions. This behavior may lead to unexpected concurrency issues in the system.
Error Handling
The error handling in SQL Server is the tricky subject especially with transactions involved. SQL Server would handle exceptions differently depending on error severity, active transaction context and several other factors.
Let’s look how exceptions affect control flow during execution. Listing below creates two tables- dbo.Customers and dbo.Orders – and populates them with the data. Note the existence of foreign key constraint defined in dbo.Orders table.
create table dbo.Customers
(
CustomerId int not null,
constraint PK_Customers
primary key(CustomerId)
);
create table dbo.Orders
(
OrderId int not null,
CustomerId int not null,
constraint FK_Orders_Customerss
foreign key(CustomerId)
references dbo.Customers(CustomerId)
);
go
create proc dbo.ResetData
as
begin
begin tran
delete from dbo.Orders;
delete from dbo.Customers;
insert into dbo.Customers(CustomerId) values(1),(2),(3);
insert into dbo.Orders(OrderId, CustomerId) values(2,2);
commit
end;
exec dbo.ResetData;
Let’s run three DELETE statements in one batch as shown below. The second statement will trigger a foreign key violation error. @@ERROR system variable provides the error number for the last T-SQL statement executed (0 means no errors).
delete from dbo.Customers where CustomerId = 1; -- Success
select @@ERROR as [@@ERROR: CustomerId = 1];
delete from dbo.Customers where CustomerId = 2; -- FK Violation
select @@ERROR as [@@ERROR: CustomerId = 2];
delete from dbo.Customers where CustomerId = 3; -- Success
select @@ERROR as [@@ERROR: CustomerId = 3];
go
select * from dbo.Customers;
Figure 3 illustrates the output of the code. As you can see, SQL Server continues execution after non-critical foreign key violation error deleting a row with CustomerId=3 afterwards.
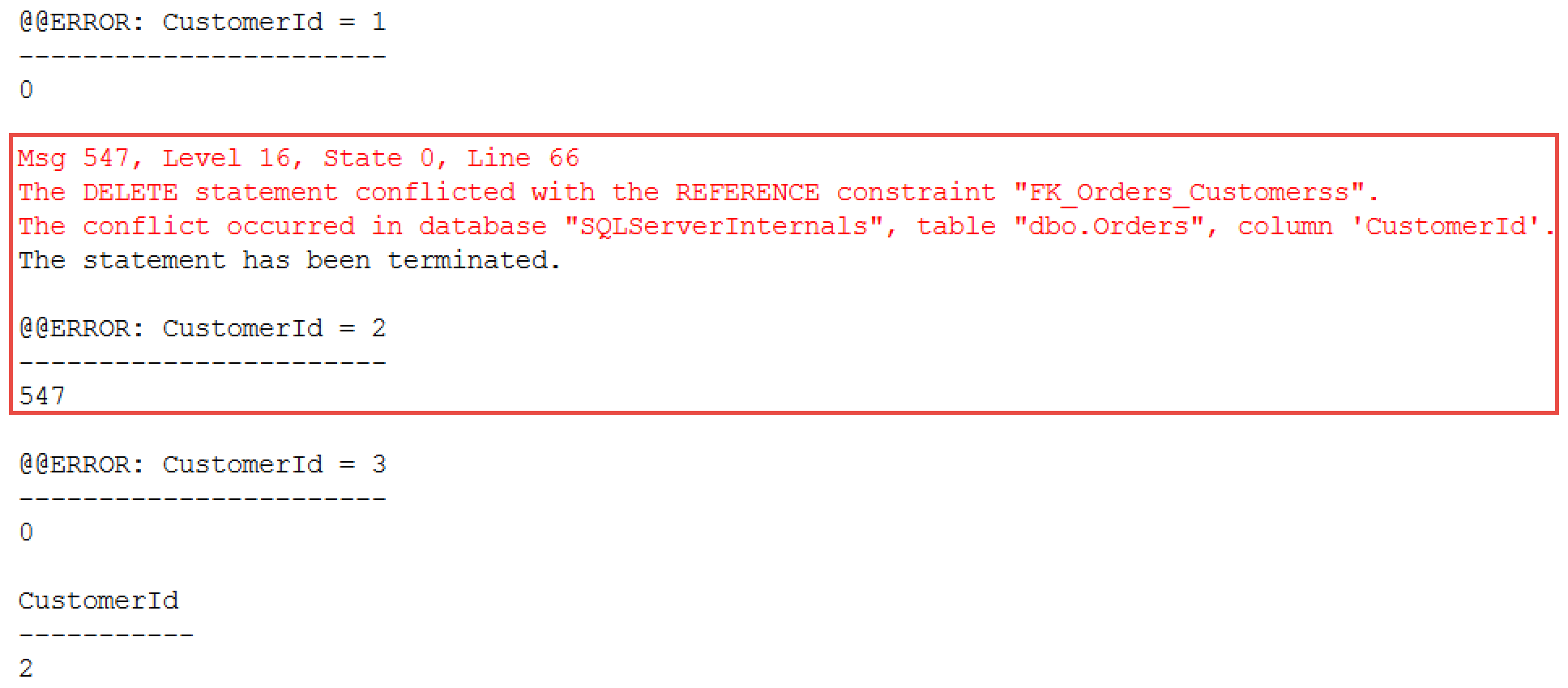
03. Running Three Autocommitted Transactions in a Batch
The situation would change when you use TRY..CATCH block as shown below.
exec dbo.ResetData;
go
begin try
delete from dbo.Customers where CustomerId = 1; -- Success
delete from dbo.Customers where CustomerId = 2; -- FK Violation
delete from dbo.Customers where CustomerId = 3; -- Not executed
end try
begin catch
select
ERROR_NUMBER() as [Error Number]
,ERROR_LINE() as [Error Line]
,ERROR_MESSAGE() as [Error Message];
end catch
go
select * from dbo.Customers;
As you can see in Figure 4, the error was caught in the CATCH block and the third deletion statement has not been executed.
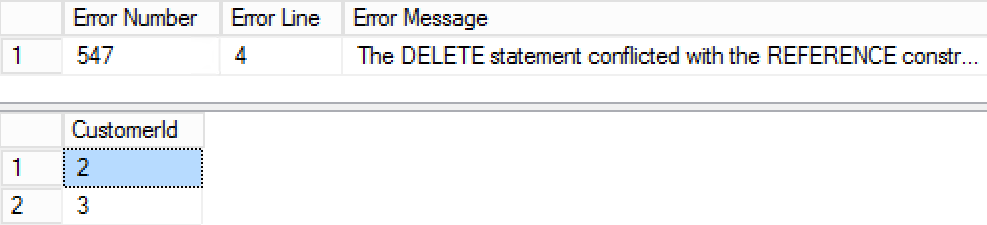
04. Running Three Autocommitted Transactions in TRY..CATCH block
Remember that non-critical exceptions do not automatically rollback explicit or implicit transactions regardless if TRY..CATCH block is present. You still need to commit or rollback transaction after the error.
Depending on severity of the error, transaction in which error occurred may be committable or become uncommittable and doomed. SQL Server would not allow you to commit uncommittable transactions and you must roll it back to complete it.
The XACT_STATE() function allows you to analyze the state of transaction and it returns one of three values:
- 0 indicates that there is no active transactions present.
- 1 indicates that there is an active and committable transaction present. You can perform any actions and data modifications committing transactions afterwards.
- -1 indicates that there is an active uncommittable transaction present. You cannot commit such transaction.
There is very important SET option- XACT_ABORT– which allows you to control error-handling behavior in the code. When this option is set to ON, SQL Server treats every run-time error as severe, making transaction uncommittable. This prevents you from accidentally committing transactions when some data modifications failed with non-critical errors.
When XACT_ABORT is enabled, any error would terminate the batch when TRY..CATCH block is not present. For example, if you run the code from the second code sample above again using SET XACT_ABORT ON, the third DELETE statement would not be executed and only the row with CustomerId=1 will be deleted. Moreover, SQL Server would automatically rollback doomed uncommitted transaction after the batch completes.
The code below shows this behavior. The stored procedure dbo.GenerateError sets XACT_ABORT to ON and generates an error within the active transaction. @@TRANCOUNT variable returns the nested level of transaction (more on it later) and non-zero value indicate that transaction is active.
create proc dbo.GenerateError
as
begin
set xact_abort on
begin tran
delete from dbo.Customers where CustomerId = 2; -- Error
select 'This statement will never be executed';
end
go
exec dbo.GenerateError;
select 'This statement will never be executed';
go
-- Another batch
select XACT_STATE() as [XACT_STATE()], @@TRANCOUNT as [@@TRANCOUNT];
go
Figure 5 illustrates the output of the code. As you can see, batch execution has been terminated and transaction has been automatically rolled back at the end of the batch.

505. XACT_ABORT behavior (no TRY..CATCH block)
TRY..CATCH block, however, will allow you to capture the error even with XACT_ABORT set to ON.
begin try
exec dbo.GenerateError;
select 'This statement will never be executed';
end try
begin catch
select
ERROR_NUMBER() as [Error Number]
,ERROR_PROCEDURE() as [Procedure]
,ERROR_LINE() as [Error Line]
,ERROR_MESSAGE() as [Error Message];
select
XACT_STATE() as [XACT_STATE()]
,@@TRANCOUNT as [@@TRANCOUNT];
if @@TRANCOUNT > 0
rollback;
end catch
As you can see in Figure 6, exception has been trapped in the CATCH block with transaction still remain active there.

06. XACT_ABORT Behavior (with TRY..CATCH block)
Consistent error handling and transaction management strategies are extremely important and allow to avoid data consistency errors and improve data quality in the system. I would recommend the following approach as the best practice:
- Always use explicit transactions in the code during data modifications. This would guarantee data consistency in transactions that consists of multiple operations. It is also more efficient comparing to individual autocommitted transactions.
- Set XACT_ABORT to ON before data modifications. This would guarantee “all-or-nothing” behavior of the transaction preventing SQL Server from ignoring non-severe errors and committing partially completed transactions.
- Use proper error handling with TRY..CATCH blocks and explicitly rollback transactions in case of exceptions. This helps to avoid unforeseen side effects in case of the errors.
The choice between client-side and server-side transaction management depends on application architecture. Client-side management is required when data modifications are done in the application code, for example changes are generated by ORM frameworks. On the other hand, stored procedure-based data access tier may benefit from server-side transaction management.
The code below provides the example of the stored procedure that implements server-side transaction management.
create proc dbo.PerformDataModifications
as
begin
set xact_abort on
begin try
begin tran
/* Perform required data modifications */
commit
end try
begin catch
if @@TRANCOUNT > 0 -- Transaction is active
rollback;
/* Addional error-handling code */
throw; -- Re-throw error. Alternatively, SP may return the error code
end catch;
end;
Nested Transactions
SQL Server technically supports nested transactions; however, they are primarily intended to simplify transaction management during nested stored procedure calls. In practice, it means that the code needs to explicitly commit all nested transactions and the number of COMMIT calls should match the number of BEGIN TRAN calls. The ROLLBACK statement, however, rolls back entire transaction regardless of the current nested level.
The code below demonstrates this behavior. As I already mentioned, system variable @@TRANCOUNT returns the nested level of the transaction.
select @@TRANCOUNT as [Original @@TRANCOUNT];
begin tran
select @@TRANCOUNT as [@@TRANCOUNT after the first BEGIN TRAN];
begin tran
select @@TRANCOUNT as [@@TRANCOUNT after the second BEGIN TRAN];
commit
select @@TRANCOUNT as [@@TRANCOUNT after nested COMMIT];
begin tran
select @@TRANCOUNT as [@@TRANCOUNT after the third BEGIN TRAN];
rollback
select @@TRANCOUNT as [@@TRANCOUNT after ROLLBACK];
rollback; -- This ROLLBACK generates the error
You can see the output of the code in Figure 7 below.
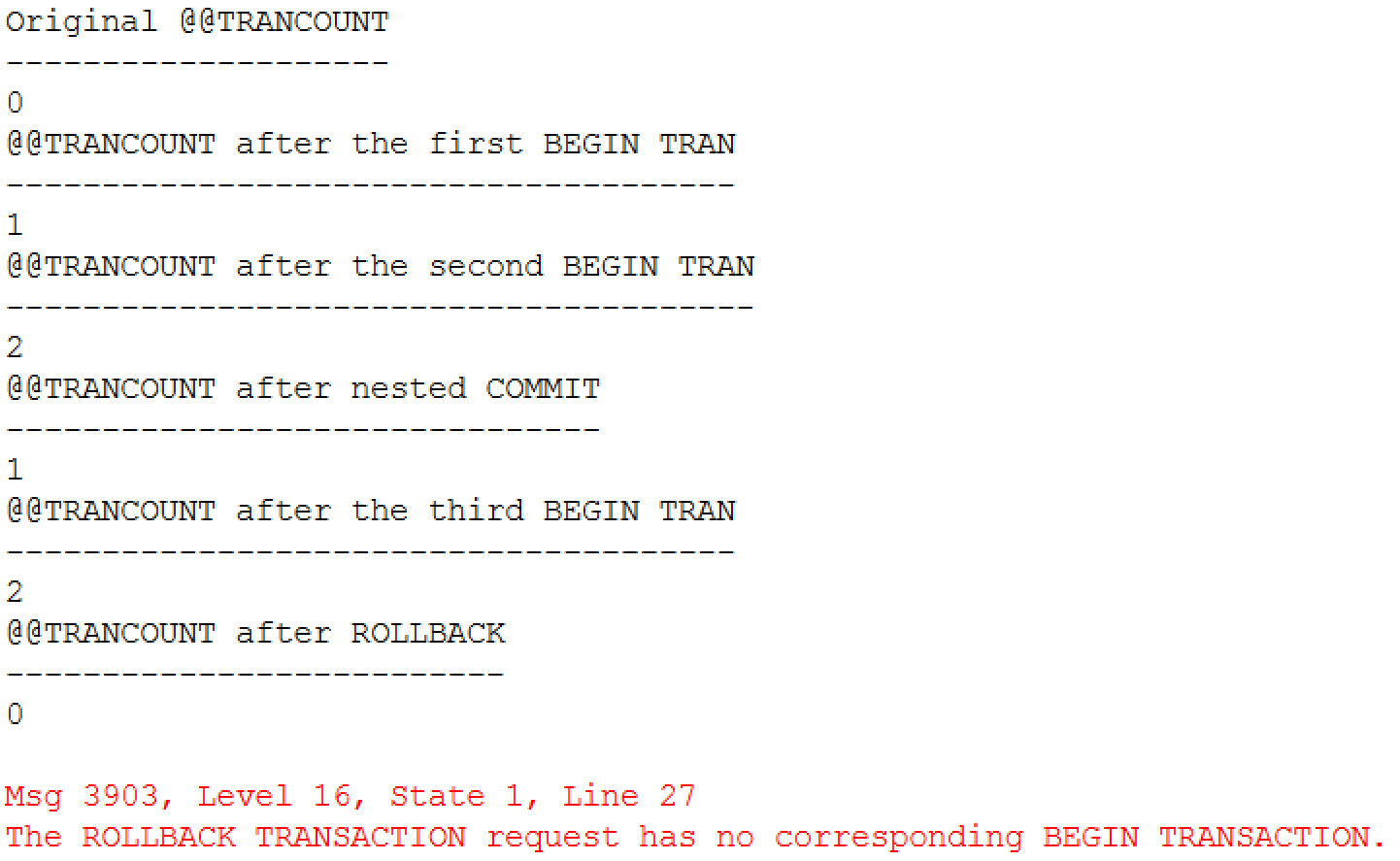
07. Nested Transactions
You can save the state of transaction and create a savepoint by using SAVE TRANSACTION statement. This will allow you to partially rollback a transaction returning to the most recent savepoint. The transaction will remain active and needs to be completed with explicit COMMIT or ROLLBACK statement later.
It is worth noting that uncommittable transactions with XACT_STATE() = -1 cannot be rolled back to savepoint. In practice, it means that you cannot rollback to savepoint after an error if XACT_ABORT is set to ON.
The code below illustrates savepoints in action. The stored procedure creates the savepoint when it runs in active transaction and rolls back to this savepoint in case of committable error.
create proc dbo.TryDeleteCustomer
(
@CustomerId int
)
as
begin
-- Setting XACT_ABORT to OFF for rollback to savepoint to work
set xact_abort off
declare
@ActiveTran bit
-- Check if SP is calling in context of active transaction
set @ActiveTran = IIF(@@TranCount > 0, 1, 0);
if @ActiveTran = 0
begin tran;
else
save transaction TryDeleteCustomer;
begin try
delete dbo.Customers where CustomerId = @CustomerId;
if @ActiveTran = 0
commit;
return 0;
end try
begin catch
if @ActiveTran = 0 or XACT_STATE() = -1
begin
-- Rollback entire transaction
rollback tran;
return -1;
end
else begin
-- Rollback to savepoint
rollback tran TryDeleteCustomer;
return 1;
end
end catch;
end;
go
-- Test
declare
@ReturnCode int
exec dbo.ResetData;
begin tran
exec @ReturnCode = TryDeleteCustomer @CustomerId = 1;
select
1 as [CustomerId]
,@ReturnCode as [@ReturnCode]
,XACT_STATE() as [XACT_STATE()];
if @ReturnCode >= 0
begin
exec @ReturnCode = TryDeleteCustomer @CustomerId = 2;
select
2 as [CustomerId]
,@ReturnCode as [@ReturnCode]
,XACT_STATE() as [XACT_STATE()];
end
if @ReturnCode >= 0
commit;
else
if @@TRANCOUNT > 0
rollback;
go
select * from dbo.Customers;
The test triggered foreign key violation during the second dbo.TryDeleteCustomer call. This is non-critical error and, therefore, the code is able to commit after it as shown in Figure 8.

08. Transaction Has Been Committed After Rollback to Savepoint
It is worth noting that this example is shown for demonstration purposes only. From efficiency standpoint, it would be better to validate referential integrity and existence of the orders before deletion occurred rather than catching exception and rolling back to savepoint in case of an error.
I hope that those examples provided you the good overview of transaction management and error handling strategies in the system. If you want to dive deeper, I would strongly recommend you to read the great article by Erland Sommarskog, which provides you much more details on the subject.
Source code is available for download.
Table of Context