Some time ago we have discussed the several techniques that can help reducing the database size. I have received quite a few responses on that post and several people asked if I could provide more details and examples. Today I will try to follow up on one of the methods, such as reducing the size of LOB data (in particular XML) in the database.
As you know, SQL Server stores the data in regular B-Tree indexes in three different sets of the data pages called allocation units. The main data row structure and fixed-length data are stored in IN-ROW data pages. Variable-length data greater than 8,000 bytes in size is stored in LOB (large object) pages. Such data includes (max) columns, XML, CLR UDT and a few other data types. Finally, variable-length data, which does not exceed 8,000 bytes, is stored either in IN-ROW data pages when it fits into the page, or in ROW-OVERFLOW data pages. You can read more about it in the previous post and here.
Enterprise Edition of SQL Server allows you to reduce the size of the data by implementing data compression. However, data compression is applied to IN-ROW data only and it does not compress ROW-OVERFLOW and LOB data. Any large objects that do not fit into IN-ROW data pages remain uncompressed.
Unfortunately, there is very little we can do to reduce the size of the LOB data. SQL Server does not provide any build-in functional to address it. The only remaining option is compressing it manually – either on the client or with CLR routines. Obviously, compression and decompression adds overhead and, from SQL Server load standpoint, it is preferable to do it on the client side. However, in the large number of cases, you will need to access compressed data from T-SQL, and CLR integration is the only choice. Ideal implementation in that case would combine compression and decompression code in both tiers and use CLR only when it is necessary.
Fortunately, .Net implementation of the compression code is very simple and can be done with DeflateStream or GZipStream classes. Below you can see the code of CLR functions that perform compression and decompression. You can also download entire project with the link at the end of the post.
/// <summary>
/// Compressing the data
/// </summary>
[Microsoft.SqlServer.Server.SqlFunction(IsDeterministic = true, IsPrecise = true,
DataAccess = DataAccessKind.None)]
public static SqlBytes BinaryCompress(SqlBytes input)
{
if (input.IsNull)
return SqlBytes.Null;
using (MemoryStream result = new MemoryStream())
{
using (DeflateStream deflateStream =
new DeflateStream(result, CompressionMode.Compress, true))
{
deflateStream.Write(input.Buffer, 0, input.Buffer.Length);
deflateStream.Flush();
deflateStream.Close();
}
return new SqlBytes(result.ToArray());
}
}
/// <summary>
/// Decompressing the data
/// </summary>
[Microsoft.SqlServer.Server.SqlFunction(IsDeterministic = true, IsPrecise = true,
DataAccess = DataAccessKind.None)]
public static SqlBytes BinaryDecompress(SqlBytes input)
{
if (input.IsNull)
return SqlBytes.Null;
int batchSize = 32768;
byte[] buf = new byte[batchSize];
using (MemoryStream result = new MemoryStream())
{
using (DeflateStream deflateStream =
new DeflateStream(input.Stream, CompressionMode.Decompress, true))
{
int bytesRead;
while ((bytesRead = deflateStream.Read(buf, 0, batchSize)) > 0)
result.Write(buf, 0, bytesRead);
}
return new SqlBytes(result.ToArray());
}
}
You can define the functions in the database with the following code (you either need to get byte sequence of the compiled assembly from the demo script or compile CLR project).
create assembly LOBCompress authorization dbo from /*..*/ go create function dbo.BinaryCompress(@input varbinary (max)) returns varbinary (max) as external name [LOBCompress].[Compress].[BinaryCompress]; go create function dbo.BinaryDecompress(@input varbinary (max)) returns varbinary (max) as external name [LOBCompress].[Compress].[BinaryDecompress]; go
Now let’s see the process in action, create the test table and populate it with some data.
create table dbo.DataWithXML
(
ID int not null,
Data xml not null,
constraint PK_DataWithXML
primary key clustered(ID)
)
go
declare
@X xml
select @X =
(
select *
from master.sys.objects
for xml raw, root('Data')
)
;with n1(c) as (select 0 union all select 0) -- 2 rows
,n2(c) as (select 0 from n1 as t1 cross join n1 as t2) -- 4 rows
,n3(c) as (select 0 from n2 as t1 cross join n2 as t2) -- 16 rows
,n4(c) as (select 0 from n3 as t1 cross join n3 as t2) -- 256 rows
,n5(c) as (select 0 from n4 as t1 cross join n3 as t2) -- 4,096 rows
,ids(id) as (select row_number() over (order by (select null)) from n5)
insert into dbo.DataWithXML(ID,Data)
select id, @X
from Ids;
update dbo.DataWithXML
set Data.modify('replace value of (/Data/row/@object_id)[1]
with sql:column("ID")');
Let’s examine the size of the table and average size of XML there using the following queries:
select
index_id, partition_number, alloc_unit_type_desc
,index_level
,page_count
,page_count * 8 / 1024 as [Size MB]
from
sys.dm_db_index_physical_stats
(
db_id() /*Database */
,object_id(N'dbo.DataWithXML') /* Table (Object_ID) */
,1 /* Index ID */
,null /* Partition ID – NULL – all partitions */
,'detailed' /* Mode */
)
go
select avg(datalength(Data)) as [Avg XML Size]
from dbo.DataWithXML;
As you can see in Figure 1, LOB allocation units are using 96MB of space to store the data. The average size of the XML data is 20,897 bytes per row. It is also worth mentioning that actual storage size for XML is 3 data pages per row, which is 24,576 bytes.
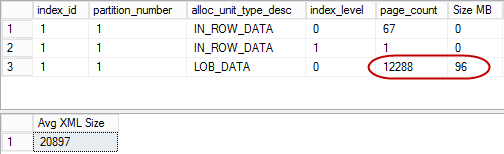
1. Uncompressed data: Storage space and XML Size
Let’s see what we can achieve by using compression. The code below creates another table and copies the data there, compressing it on the fly. As you see, the data is stored in varbinary(max) column.
create table dbo.DataWithCompressedXML
(
ID int not null,
Data varbinary(max) not null,
constraint PK_DataWithCompressedXML
primary key clustered(ID)
)
go
insert into dbo.DataWithCompressedXML(ID,Data)
select ID, dbo.BinaryCompress(convert(varbinary(max),Data))
from dbo.DataWithXML
Let’s check the size of the data in compressed table:
select avg(datalength(Data)) as [Uncompressed]
from dbo.DataWithXML;
select avg(datalength(Data)) as [Compressed]
from dbo.DataWithCompressedXML
go
select
index_id, partition_number, alloc_unit_type_desc
,index_level
,page_count
,page_count * 8 / 1024 as [Size MB]
from
sys.dm_db_index_physical_stats
(
db_id() /*Database */
,object_id(N'dbo.DataWithCompressedXML') /* Table (Object_ID) */
,1 /* Index ID */
,null /* Partition ID – NULL – all partitions */
,'detailed' /* Mode */
)
As you can see in Figure 2, we were able to reduce the size of the table from 96 to 10MB decreasing the size of the XML in every row from 20,897 to 2,674 bytes.

2. Compressed data: Storage size and compressed XML size
It is also worth noting that in our case, the size of compressed data is less than 8,000 bytes and SQL Server was able to accommodate all the data using IN-ROW allocation units. Even though the new table is almost 10 times smaller than the old one, it has significantly more IN-ROW data pages in the index. This could introduce some performance side effects in some cases. For example, when system has poorly optimized queries that perform clustered index scans. Again, it could become the issue only if compressed data is less than 8,000 bytes. Otherwise, SQL Server will still store it using the LOB data pages.
Obviously, this implementation requires schema and code changes. We can mitigate it a little bit by abstracting it with the views as it is shown below.
create view dbo.vDataWithXML(ID, Data)
as
select ID, convert(xml,dbo.BinaryDecompress(Data))
from dbo.DataWithCompressedXML
We can even create INSTEAD OF trigger (yuck!) on the view to minimize the changes if absolutely needed.
Speaking of the overhead, compressing and decompressing are CPU intensive and there is the performance penalty of calling CLR functions. It is not that noticeable when you need to decompress the single or very few rows; however, it could be very significant on the large data sets. For example, when you need to decompress and shred XML and use some of its elements in a where clause of the query. The code below shows such an example.
set statistics time on
select count(*)
from dbo.DataWithXML
where Data.value('(/Data/row/@object_id)[1]','int') = 3;
select count(*)
from dbo.vDataWithXML
where Data.value('(/Data/row/@object_id)[1]','int') = 3;
set statistics time off
The second SQL that accesses the compressed table has to decompress XML for every row in the table. The execution times of the statements on my laptop are 116ms and 6,899ms respectively. As you see, the compression definitely comes at cost.
One of the ways to reduce such an overhead, is storing XML elements that are used in the queries in the separate table columns. Unfortunately, by-the-book approach with persisted calculated columns would not always works. It is possible to create and persist such a column using user-defined functions; however, SQL Server would ignore it in some cases. The code below shows the example that creates calculated column that contains the attribute we are using in our queries.
create function dbo.fnGetCompressedObjectId(@Compressed varbinary(max))
returns int
with schemabinding
as
begin
return (convert(xml,dbo.BinaryDecompress(@Compressed))
.value('(/Data/row/@object_id)[1]','int'))
end
go
alter table dbo.DataWithCompressedXML
add
ObjId as dbo.fnGetCompressedObjectId(Data)
persisted
go
-- It is a good practice to rebuild index after alteration
alter index PK_DataWithCompressedXML
on dbo.DataWithCompressedXML rebuild
go
alter view dbo.vDataWithXML(ID, Data, ObjId)
as
select ID, convert(xml,dbo.BinaryDecompress(Data)), ObjId
from dbo.DataWithCompressedXML
go
Unfortunately, if you ran the following query: select count(*) from dbo.vDataWithXML where ObjId = 3, you’d notice that SQL Server recalculates the value of the calculated column even though it is persisted and functions are defined as deterministic and precise. This is just the limitation of the Query Optimizer. Figure 3 shows that ObjId is recalculated.

3. Execution plan of the query
There is still the possibility of using persisted calculated columns. For example, you can define CLR function, which decompress and parse XML and return ObjID as the integer. Something like that:
.Net CLR:
[Microsoft.SqlServer.Server.SqlFunction(IsDeterministic = true, IsPrecise = true,
DataAccess = DataAccessKind.None)]
public static SqlInt32 GetObjId(SqlBytes input)
{
if (input.IsNull)
return SqlInt32.Null;
/* Parsing XML with XmlReader and return ObjId attribute */
}
SQL:
create function dbo.GetObjId(@input varbinary (max))
returns int
as external name [LOBCompress].[Compress].[GetObjId]
go
alter table dbo.DataWithCompressedXML drop column ObjId
go
alter table dbo.DataWithCompressedXML
add
ObjId as dbo.GetObjId(Data)
persisted
go
alter index PK_DataWithCompressedXML
on dbo.DataWithCompressedXML rebuild
go
Now, if you run the previous query: select count(*) from dbo.vDataWithXML where ObjId = 3, it would work just fine and does not recalculate the column value. Figure 4 shows the execution plan in this case.

4. Execution plan that utilizes calculated column
It is worth mentioning that execution time of this query on my laptop is just 3 milliseconds comparing to 116 milliseconds of the query against dbo.DataWithXML table. The query is significantly faster because it does not need to shred XML to obtain ObjID value.
Obviously, creating separate CLR methods for each calculated column can lead to some coding overhead. You can consider using regular columns instead and populate them in the code or even in the triggers. Each approach has the own set of benefits and downsides based on the use-cases implemented in the system.
Compressing LOB data in the database could help you to significantly reduce the database size in the large number of cases. However, it adds an overhead of compressing and decompressing data. In some cases, such overhead would be easily offset by the smaller data size, less I/O and buffer pool usage but in any case, you should be careful and take all other factors into the consideration.
Source code is available for download.
I did something similar once back when clr integration was first available in SQL 2005. Worked great, as long as you didn’t try it in 32-bit SQL servers (this was several years ago). Something about the available memory for the CLR being constrained.