One of the questions I have often been asked during various SQL Server events is what exactly Table Spool operator does in execution plan. I would try to answer it today.
Spool operators, in the nutshell, are internal in-memory or on-disk caches/temporary tables. SQL Server often uses spools for performance reasons to cache results of complex subexpressions that needs to be used multiple times during query execution.
Let’s look at the example and create the table, which stores some sales information as shown below:
create table dbo.Orders ( OrderID int not null, CustomerId int not null, Total money not null, constraint PK_Orders primary key clustered(OrderID) ); ;with N1(C) as (select 0 union all select 0) -- 2 rows ,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows ,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows ,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows ,Nums(Num) as (select row_number() over (order by (select null)) from N4) insert into dbo.Orders(OrderId, CustomerId, Total) select Num, Num % 10 + 1, Num from Nums;
Now let’s run the query that returns the list of orders with the information about total amount of sales on per-customer basis.
select OrderId, CustomerID, Total ,Sum(Total) over(partition by CustomerID) as [Total Customer Sales] from dbo.Orders
As you see, in the execution plan below, SQL Server scans the table, sorts the data based on CustomerID order and uses Table Spool operator to cache the results. It allows SQL Server to access the cached data and avoid expensive sorting operation later.
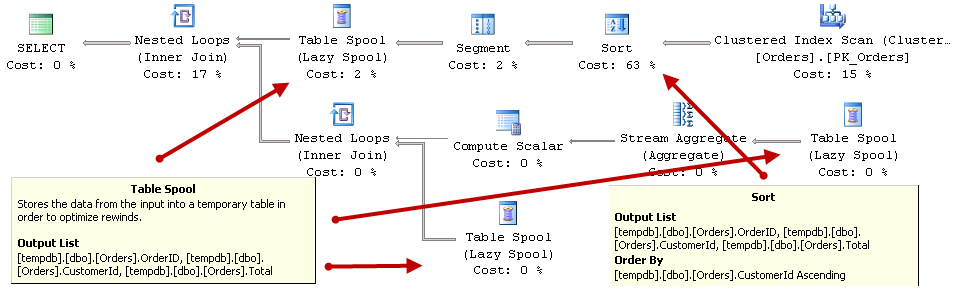
01. Execution Plan with Spool operators
Even though Table Spool operator is shown in the execution plan multiple times, it is essential the same spool/cache. SQL Server builds it the first time and using its data later.
Technically speaking, there are two different logical spool operators – Eager Spool and Lazy Spool. The only difference between them are how data is populated. With Eager Spool, SQL Server fetches all rows as soon as spool is called. With Lazy Spool, SQL Server fetches rows on demand – when they are needed.
SQL Server also uses spools for Halloween Protection when modifying the data. Halloween Protection helps to avoid situations when data modifications affect what data need to be updated. The classic example of such situation is shown below. Without Halloween Protection, insert statement would fall into infinitive loop, reading rows it has been inserting.
create table dbo.HalloweenProtection ( Id int not null identity(1,1), Data int not null ); insert into dbo.HalloweenProtection(Data) select Data from dbo.HalloweenProtection;
As you can see in the execution plan of insert statement, SQL Server uses Table Spool operator to cache the data from table as of before insert starts to avoid infinitive loop during execution.

02. Halloween Protection and Table Spools.
Halloween Protection has very interesting side-effect when we are talking about multi-statement user-defined functions (both, scalars and table-valued). Using multi-statement functions is bad practice by itself, however creating them without SCHEMABINDING option is even worse. That option forces SQL Server to analyze if user-defined function performs data access and avoid extra Halloween Protection-related Spool operators in the execution plan.
Let’s see the example and create two user-defined functions and using them in where clause of update statements.
create function dbo.ShouldUpdateData(@Id int) returns bit as begin return (1) end go create function dbo.ShouldUpdateDataSchemaBound(@Id int) returns bit with schemabinding as begin return (1) end go update dbo.HalloweenProtection set Data = 0 where dbo.ShouldUpdateData(ID) = 1; update dbo.HalloweenProtection set Data = 0 where dbo.ShouldUpdateDataSchemaBound(ID) = 1;
Neither of functions access the data and therefore can introduce Halloween effect. However, SQL Server does not know that in case of non-schema bound function and add Spool operator to execution plan as shown below.
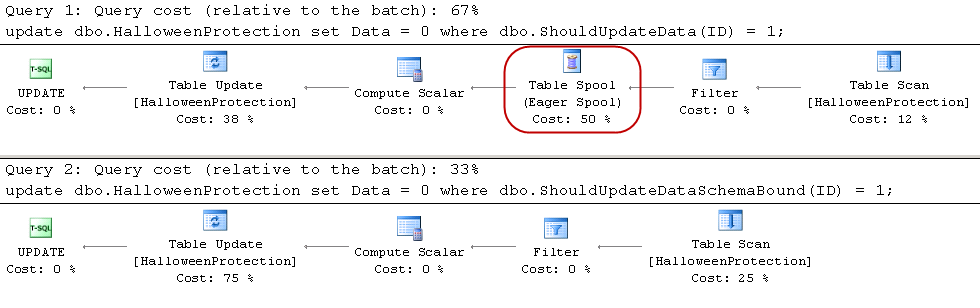
03. Execution Plans for user-defined functions
Bottom line – you should always make functions schema-bound when you create them.
Spool temporary tables are usually referenced as worktables in I/O statistics for the queries. You should analyze table spool-related reads during query performance tuning. While spools can improve performance of the queries, there is the overhead introduced by unnecessary spools. You can often remove them by creating appropriate indexes on the tables.
Pingback: (SFTW) SQL Server Links 10/01/14 • John Sansom