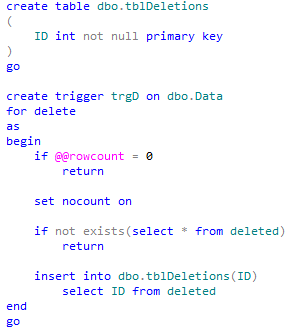
Today I’d like us to discuss how we can implement analog of Critical Section (or Mutex) in T-SQL. One of the tasks when it could be beneficial is when we need to prevent the multiple sessions from reading the data simultaneously. As the example let’s think about the system which collects some data and does some kind of post processing after data is inserted.
One of the typical implementation in such architecture would be having the farm of the application servers that do the post processing. We usually need to have more than one server in such scenario for scalability and redundancy reasons. The key problem here is how to prevent the different servers from reading and processing the same data simultaneously. There are a few ways how we can do it. One approach would be using central management server that loads and distributes the data across processing servers. While it could help with the scalability we will need to do something to make that server redundant. Alternatively we can use some sort of distributed cache solution. We could load the data there and every server grabs and processes the data from the cache. That approach could be scalable and work great although distributed cache is not the easy thing to implement. There are the few (expensive) solutions on the market though if you don’t mind to spend money.
There are of course, other possibilities but perhaps the easiest approach from the coding standpoint would be implementing application servers in the stateless manner and do the serialization while reading the data in T-SQL.
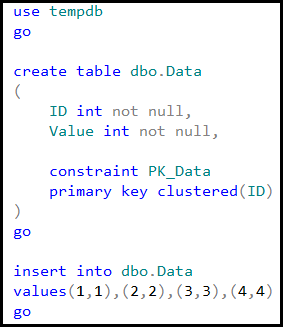
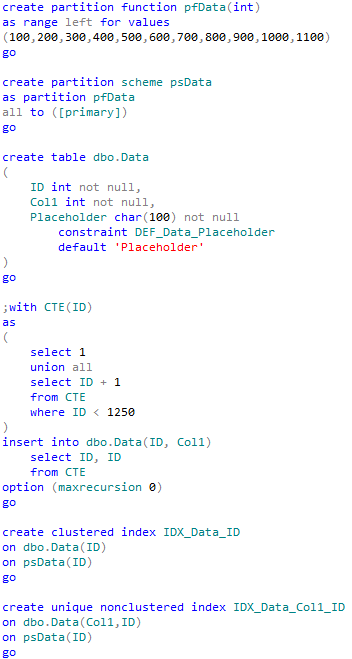
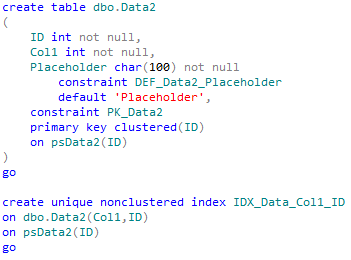
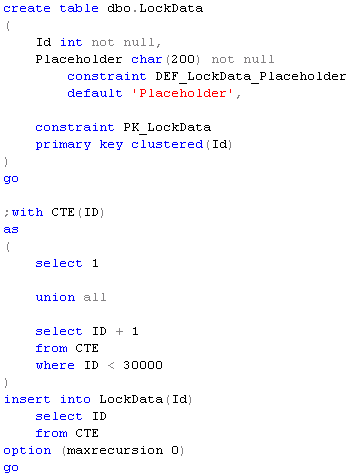
Let’s create the table we can use in our exercises and populate it with some data.

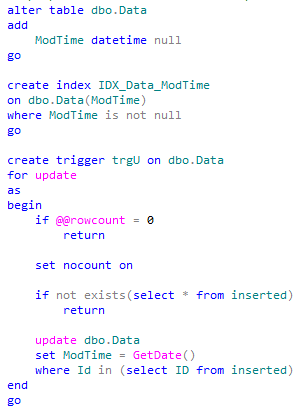
A couple things here. First of all, we need to handle the situations when application server crashes and make sure that data would be loaded again after some time by another app server. This is a reason why we are using ReadForProcessing datetime column rather than the simple Boolean flag.
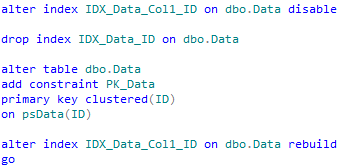
I’d also assume that system wants to read data in FIFO (first in, first out) order as much as possible and after processing is done the data would be moved into another table and deleted from the original RawData table. This is the reason why there is no indexes but clustered primary key. If we need to keep the data in the same table we can do it with additional Boolean flag, for example Processed bit column, although we will need to have another index. Perhaps:
create nonclustered index IDX_RawData_ReadForProcessing
on dbo.RawData(ReadForProcessing)
include(Processed)
where Processed = 0
In addition to the index we also need to assign default value to ReadForProcessing column to avoid ISNULL predicate in the where clause to make it SARGable. We can use some value from the past. 2001-01-01 would work just fine.
In either case, after we read the data for the processing we need to update ReadyForProcessing column with the current (UTC) time. The code itself could look like that:

DataPacket CTE is using ordered clustered index scan. It would stop scanning immediately after read 10 rows (TOP condition). Again, we are assuming that data is moved to another table after the processing so it would be efficient. We are updating the timestamp same time when we read it and saving the package for the client in the temporary table @Result using output clause
The problem here is the race condition when two or more sessions are starting to read and update the data simultaneously. Our update statement would obtain shared (S) locks during select in CTE and after that use update (U) and exclusive (X) locks on the data to be updated.
Obviously different sessions would not be able to update the same rows simultaneously – one session will hold exclusive (X) lock on the row while other sessions would be blocked waiting for shared (S) or update (U) lock. In the first case (shared (S) lock), it’s not a problem – the blocked session will read new (updated) value of ReadForProcessing column as soon as the first session releases the exclusive (X) lock. But in the second case the second session will update (and read) the row the second time. Simplified version of the process is shown below.
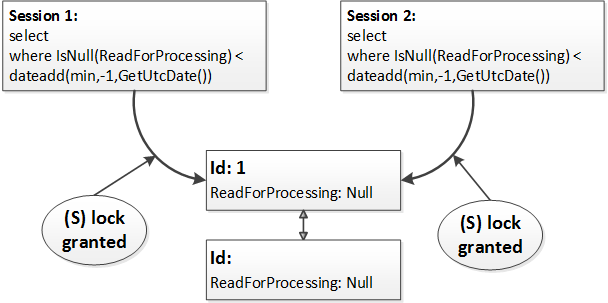
At the first step both sessions read the row acquiring and releasing shared (S) locks. Both sessions evaluate the predicate (isnull(ReadForProcessing,’2001-01-01′) < dateadd(minute,-1,GetUtcDate())) and decided to update the row. At this point one of the sessions acquires update(U) and then exclusive (X) lock while other session is blocked.
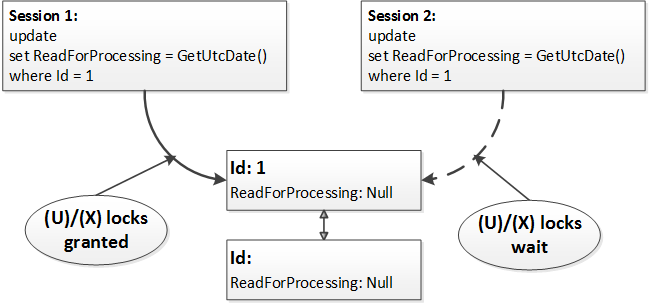
After the first session releases the exclusive (X) lock, the second session updates the same row.

How can we avoid that? We can create another resource and acquire exclusive lock on that resource before update statement from within the transaction. As we remember, exclusive (X) locks held till the end of transaction, so we will use it as the serialization point. Let’s take a look how it works by creating another table as the lock resource. Now, if we start transaction, we can obtain exclusive table lock. Again, exclusive (X) locks held till the end of transaction, so other sessions would be blocked trying to acquire the lock on the table. As result, execution of our update statement would be serialized.
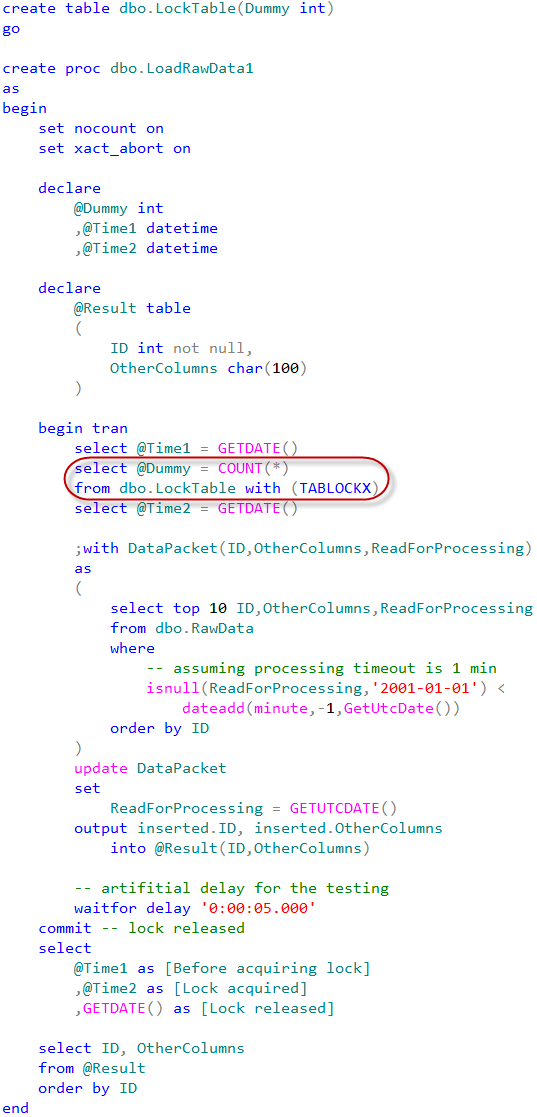
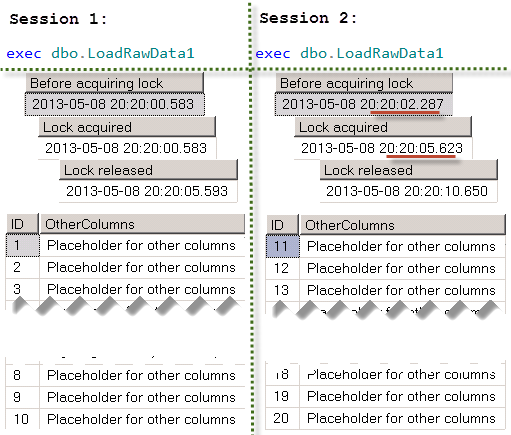
We can test that approach by running this SP from the multiple sessions simultaneously. There is the artificial delay which we are using during the testing just to make sure that we have enough time to run SP in the different session.
While that approach works, there is another, better way to accomplish the same task. We can use application locks. Basically, application locks are just the “named” locks we can issue. We can use them instead of locking table.

That would lead to the same results.
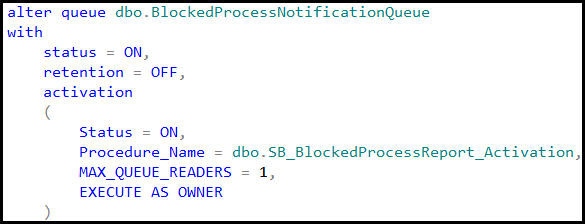
Application locks are also very useful when we need to implement some code that alters the database schema (for example alter partition function) in the systems that are running under load all the time (24×7). Our DDL statements can issue shared application locks while DDL statements acquire exclusive application locks. This would help to avoid deadlocks related to the lock partitioning. You can see the post about lock partitioning with more details about the problem and implementation.
Although, if we talk about specific task of serialization of the reading process, we don’t need critical section at all. We can use the locking hints instead.
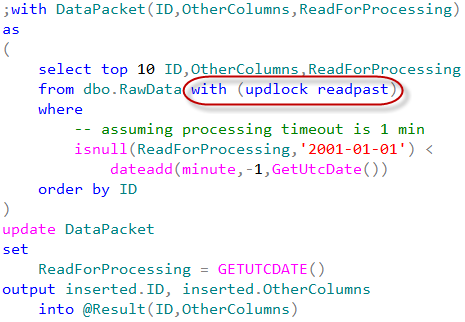
As you can see, there are two locking hints in the select statement. UPDLOCK hint forces SQL Server using update (U) locks rather than shared (S) ones. Update locks are incompatible with each other so multiple sessions would not be able to read the same row. Another hint – READPAST – tells SQL Server to skip the locked rows rather than being blocked. Let’s modify our stored procedure to use that approach.

I’m adding some code to the procedure to emulate race condition. In one session we will run the stored procedure with @UseDelay = 1. In another with @UseDelay = 0. Both of those sessions will start to execute the main update statement roughly at the same time.

This method works even more efficiently than the “critical section” approach. Multiple sessions can read the data in parallel.
Well, I hope that we achieved two goals today. First – we learned how to implement critical section and/or mutexes in T-SQL. But, more importantly, I hope that it taught us that in some cases, the “classic” approach is not the best and we need to think out of the box. Even when this thinking involved the standard functional available in SQL Server.
Source code is available for download