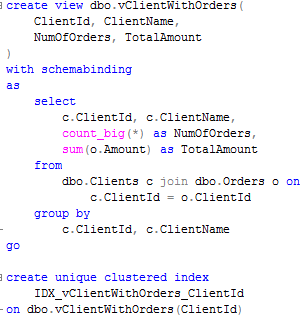
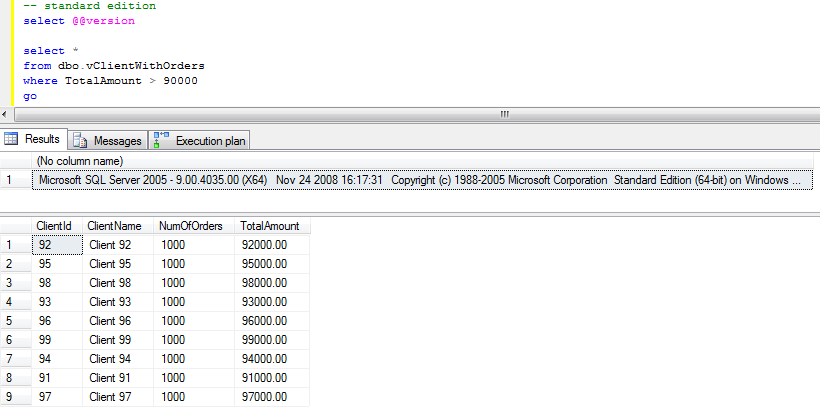
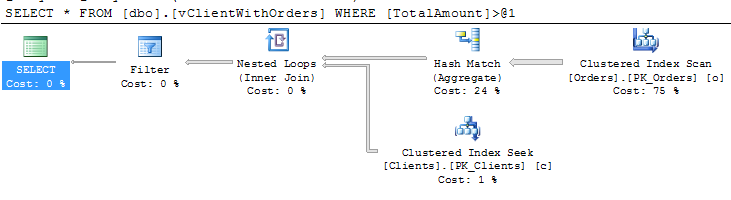
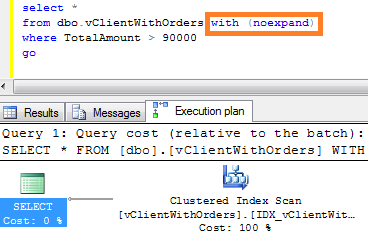
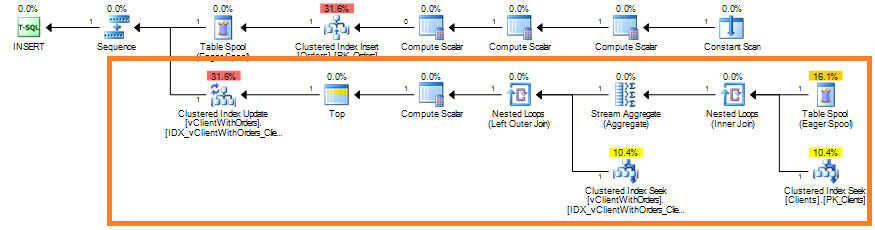
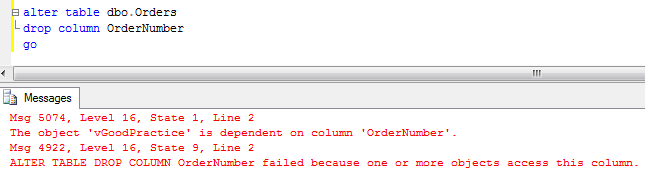
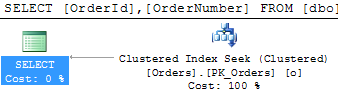
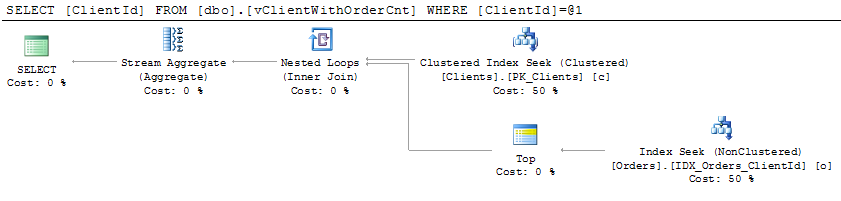
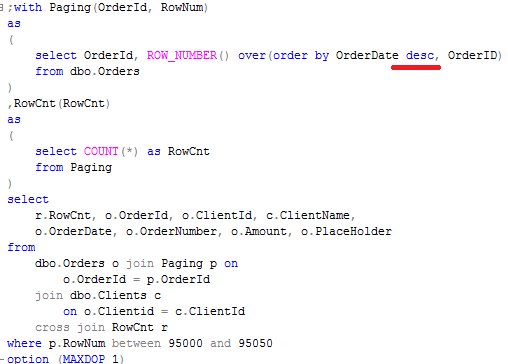
As we already know, usually blocking happens due non-optimized queries. But how to detect queries that need to be optimized? Of course, in case of severe issues, we can analyze the queries that timeouts on the client side, but it gives us only the worst cases – with default settings it would show the queries that ran for more than 30 seconds.
So, what can we do? Keeping various monitoring software out of scope, there are 2 simple methods to do the troubleshooting. First one is Blocking Process Report and second one is DMV. Let’s start with the first one.
Blocking process report provides you nice XML with information about sessions involved in the blocking. But first, you have to set Blocked Process Threshold with the following commands:
EXECUTE sp_configure 'show advanced options', 1
GO
RECONFIGURE
GO
EXECUTE sp_configure 'blocked process threshold', 5 -- in seconds.
GO
RECONFIGURE
GO
EXECUTE sp_configure 'show advanced options', 0
GO
RECONFIGURE
GO
Of course, you should think what threshold you want to use and balance between a lot or very few events reported. I’d suggest to start with threshold of 5 seconds – if you have processes that are blocked for more than 5 seconds there is the good chance that deadlock monitor is constantly running. There are 2 things to keep in mind. First – SQL does the good job trying to monitor the blocking and generate blocked processes report, but it does not guarantee that it will do it all the time. E.g. it does the check when it has available resources to do so. Secondary, if you have process blocked for a long time, SQL generates report on every try. I.e. if you have threshold equal to 5 seconds, you will get the different reports for the same blocked condition after 5 seconds, 10 seconds and so on.
After you set that threshold, the next step is to run SQL Server Profiler and setup the trace with only 1 event: “Blocked process report”. You can do it in UI:

But the better way to run server side trace. You can export trace definition and run the script to do that.

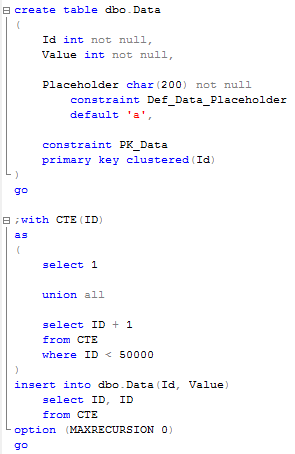
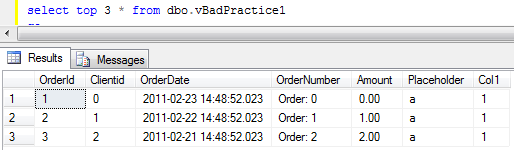
I’m not going to focus on the details how to set it up – you can find information in Books Online. So let’s see what information that trace produces. Let’s run the blocking script from my previous post. In one session let’s run the update in uncommitted transaction (X lock on the row):

In another session let’s run select that introduces table scan:
![]()
Blocked process trace generates the report with following XML.

It has 2 elements: blocked-process and blocking-process. Simple case has just 2 processes involved but in real life it could be more complicated – Process A can block Process B and same time be blocked by Process C. That leads to the multiple events in the trace.
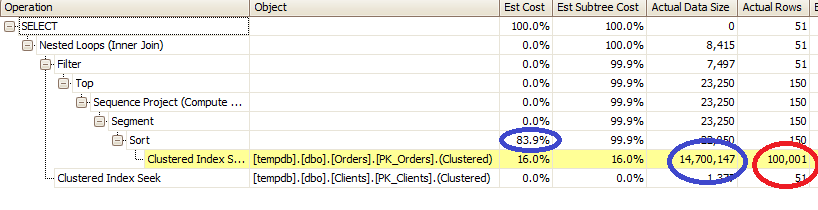
Let’s take a quick look at the details. First of all, you can see the status (red lines). Blocked process has the status of “Suspended”. Blocking process status is more interesting. “Sleeping” status indicates that process is waiting for the next command. Most likely it’s the sign of incorrect transaction handling on the client. Think about situation when client starts transaction when user opens the form, update data when user does some changes and commit or rollback it when user clicks on SAVE or CANCEL button.
Next, blocking report shows quite a few details about processes itself (Green lines). SPID, login, host, client app, etc. It also includes the information (Blue lines) about transaction isolation level, lock mode requested as well as point to resource that is locked. If you need, you can trace it down to specific row although I found that it’s rarely needed.
But most interesting are execution stacks and buffers (Pink blocks). For Ad-hoc sql you can see actual SQL involved in the locking. The situation is a little bit more complicated when stored procedures are involved. Let’s take a look. First, let’s create the simple procedure that replaces this update statement:
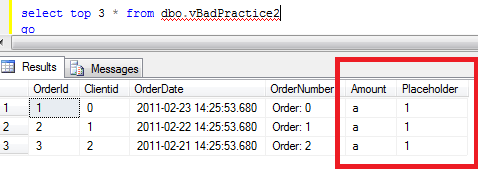
Next, let’s run this SP and select statement again. Make sure you commit or rollback transaction from the previous example first. Here is the blocking report:

As you can see in the blocking report, it does not show you what statement caused the blocking. In order to get it, you can use SQLHandle from the top statement in the execution stack and sys.dm_exec_sql_text data management function. Let’s see that:
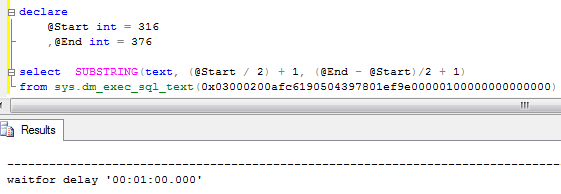
You can either count the line based on the trace value or find the actual statement based on offsets. It worth to mention that this could return different statement that the one that acquired the lock.
That method has one major drawback – statement needs to be in the cache in order at the time when you call sys.dm_exec_sql_text function. Alternative and better method to obtain blocked process report is using extended events (SQL Server 2008+). While it returns the same data, event is triggered at the time of the blocking, so you can analyze/query the system at the time of the blocking. But it’s far more complex to setup and out of the scope for now.
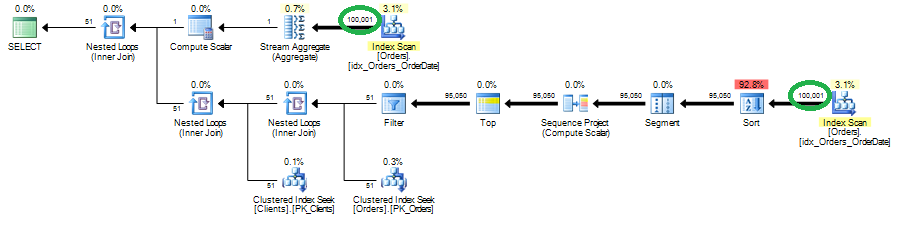
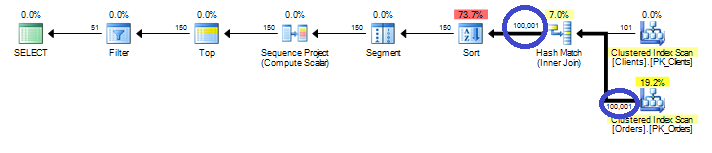
After you find the statements involved in the blocking, you can analyze while blocking occurs. As I mentioned before, the chance is that there are scans involved. You can use management studio and see execution plan there. Alternatively I found that those queries are quite often become one of the biggest IO consumers in the system, so you’ll see them if you analyze sys.dm_query_exec_stats data management view. You can use the script below. If query is there – just click on the plan and you’re all set.
SELECT TOP 50
SUBSTRING(qt.TEXT, (qs.statement_start_offset/2)+1,
((
CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.TEXT)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2)+1),
qp.query_plan,
qs.execution_count,
(qs.total_logical_reads + qs.total_logical_writes) / qs.execution_count as [Avg IO],
qs.total_logical_reads, qs.last_logical_reads,
qs.total_logical_writes, qs.last_logical_writes,
qs.total_worker_time,
qs.last_worker_time,
qs.total_elapsed_time/1000 total_elapsed_time_in_ms,
qs.last_elapsed_time/1000 last_elapsed_time_in_ms,
qs.last_execution_time
FROM
sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
ORDER BY
[Avg IO] DESC
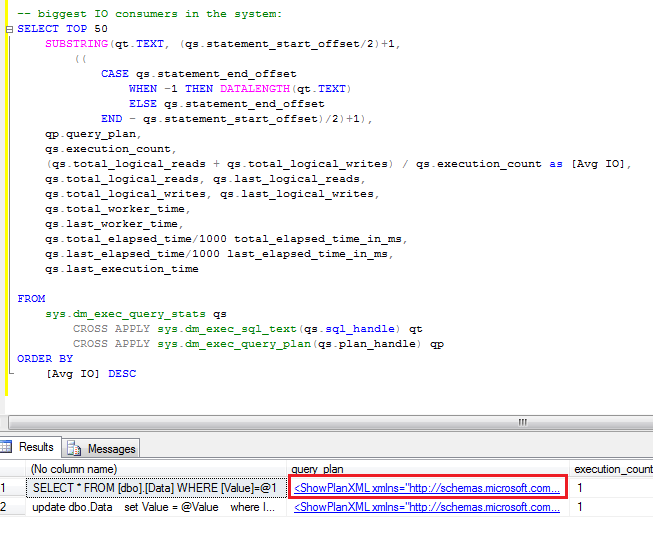
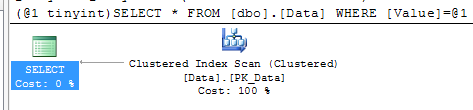
Blocking process report is extremely useful when you need to collect information about blocking. Although, if you need to look what happens in the system right now, you can use sys.dm_tran_locks data management view. I’ll show you 2 scripts below.
The first one gives you the list of the locks system has right now:
select
TL1.resource_type
,DB_NAME(TL1.resource_database_id) as [DB Name]
,CASE TL1.resource_type
WHEN 'OBJECT' THEN OBJECT_NAME(TL1.resource_associated_entity_id, TL1.resource_database_id)
WHEN 'DATABASE' THEN 'DB'
ELSE
CASE
WHEN TL1.resource_database_id = DB_ID()
THEN
(
select OBJECT_NAME(object_id, TL1.resource_database_id)
from sys.partitions
where hobt_id = TL1.resource_associated_entity_id
)
ELSE
'(Run under DB context)'
END
END as ObjectName
,TL1.resource_description
,TL1.request_session_id
,TL1.request_mode
,TL1.request_status
,WT.wait_duration_ms as [Wait Duration (ms)]
,(
select
SUBSTRING(
S.Text,
(ER.statement_start_offset / 2) + 1,
((
CASE
ER.statement_end_offset
WHEN -1
THEN DATALENGTH(S.text)
ELSE ER.statement_end_offset
END - ER.statement_start_offset) / 2) + 1)
from
sys.dm_exec_requests ER
cross apply sys.dm_exec_sql_text(ER.sql_handle) S
where
TL1.request_session_id = ER.session_id
) as [Query]
from
sys.dm_tran_locks as TL1 left outer join sys.dm_os_waiting_tasks WT on
TL1.lock_owner_address = WT.resource_address and TL1.request_status = 'WAIT'
where
TL1.request_session_id <> @@SPID
order by
TL1.request_session_id

The second one is slightly modified version that shows you only blocking and blocked processes.
/*
Shows blocked and blocking processes. Even if it works across all database, ObjectName
populates for current database only. Could be modified with dynamic SQL if needed
Be careful with Query text for BLOCKING session. This represents currently active
request for this specific session id which could be different than query which produced locks
It also could be NULL if there are no active requests for this session
*/
select
TL1.resource_type
,DB_NAME(TL1.resource_database_id) as [DB Name]
,CASE TL1.resource_type
WHEN 'OBJECT' THEN OBJECT_NAME(TL1.resource_associated_entity_id, TL1.resource_database_id)
WHEN 'DATABASE' THEN 'DB'
ELSE
CASE
WHEN TL1.resource_database_id = DB_ID()
THEN
(
select OBJECT_NAME(object_id, TL1.resource_database_id)
from sys.partitions
where hobt_id = TL1.resource_associated_entity_id
)
ELSE
'(Run under DB context)'
END
END as ObjectName
,TL1.resource_description
,TL1.request_session_id
,TL1.request_mode
,TL1.request_status
,WT.wait_duration_ms as [Wait Duration (ms)]
,(
select
SUBSTRING(
S.Text,
(ER.statement_start_offset / 2) + 1,
((
CASE
ER.statement_end_offset
WHEN -1
THEN DATALENGTH(S.text)
ELSE ER.statement_end_offset
END - ER.statement_start_offset) / 2) + 1)
from
sys.dm_exec_requests ER
cross apply sys.dm_exec_sql_text(ER.sql_handle) S
where
TL1.request_session_id = ER.session_id
) as [Query]
from
sys.dm_tran_locks as TL1 join sys.dm_tran_locks TL2 on
TL1.resource_associated_entity_id = TL2.resource_associated_entity_id
left outer join sys.dm_os_waiting_tasks WT on
TL1.lock_owner_address = WT.resource_address and TL1.request_status = 'WAIT'
where
TL1.request_status <> TL2.request_status and
(
TL1.resource_description = TL2.resource_description OR
(TL1.resource_description is null and TL2.resource_description is null)
)

So those are 2 techniques that can help you with the troubleshooting. Again, I think it’s not as powerful as extended events approach but same time those are much simpler to accomplish.
Source code is available for download
Also check Part 16: Monitoring Blocked Processes with Event Notifications that shows how to automate the process.