Let’s assume you have UI that allows to see subset of the data based on pages, with sorting by wide set of columns in both ascending/descending orders. This is probably one of the worst tasks for database developers and administrators – quite easy to implement with ROW_NUMBER() function, but very hard to tune.
Let’s take a look. First of all, let’s create the tables and populate it with some data.
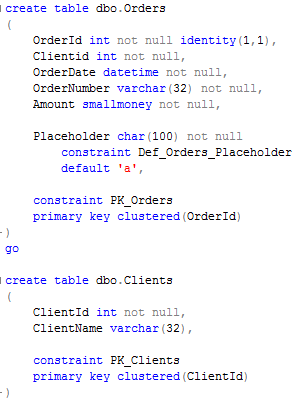

Now, let’s try to return rows #100-150 sorted by OrderDate ASC. I’m disabling parallelism to make it a little bit simpler to analyze. So let’s start with the “standard” approach. Unfortunately SQL Server does not allow to use ranking functions in WHERE clause so we need to use either CTE or subselect. Click on the images below to open them in the separate window.

Now let’s take a look at the plan. I’m using SQL Sentry Plan Explorer – great tool – check it out if you are not familiar with it
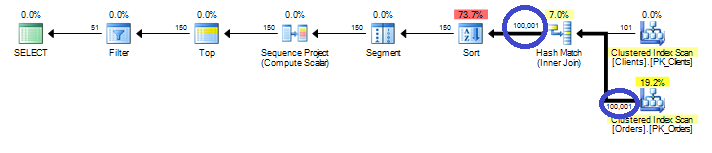
In order to calculate Row_Number, SQL Server needs to read entire row set and next sort it. Obviously performance is not so great. So let’s think how we can improve that. One of the first things there – we don’t want to do the join on “pre-sorting stage”. So first of all, let’s move join from CTE to the main select:
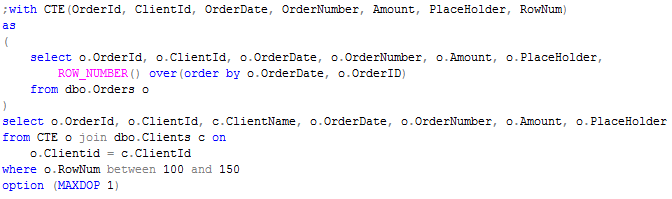

As you can see, now we need to perform join with Clients table only for 51 rows. So it looks better. Let’s try to dive a little bit deeper into details.
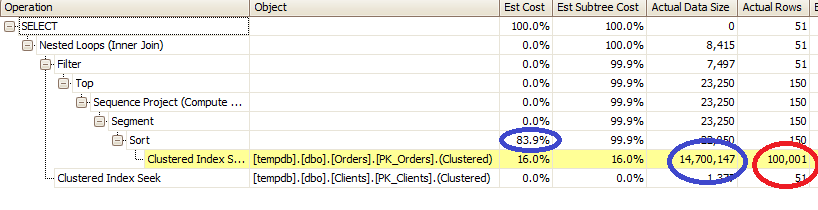
We have 2 major problems. One is obvious (Red circle) – this is clustered index scan. We will talk about it in a minute. Second one (blue circles) is much less obvious. It’s sorting. Sorting is blocking operation – it needs to collect entire input first. So in our case, it’s 100,000 rows and 14,7M of data. Well, first of all, it’s memory and CPU consuming, but more importantly, if statistics is not ideal and SQL Server underestimates # of input rows, there is the good chance that it would produce sort in tempdb which is also major performance hit. How can we improve it? Let’s massage our SQL a little bit:


At the first glance, it introduce plan not as good as the previous one. Although, if you take a look at the data size, you’ll see, that SORT operator requires 8 times less memory. As result, it would be less CPU intensive and will execute faster. At the end, it can give you huge performance improvements in the case, when output row is large.

Now let’s think about IO. Let’s create the index on OrderDate.
![]()

Obviously it helps. It removes sort operator – SQL Server just need to scan first 150 rows from the index. The problem is that this index covers only specific case – one column and one ASC sorting order. If you change it to DESC, SQL Server still needs to sort the data.
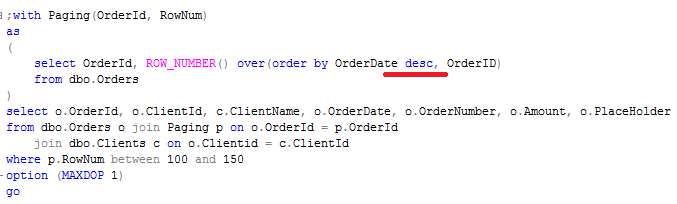

Well, if you have 10 different columns user can sort data in both ASC/DESC orders, you need to create 20 different indexes to cover all possible cases. It’s not possible, of course. On other hand, if there are just a couple combinations that users typically use, it could make sense to create a couple indexes to cover them.
One other thing worth to mention, instead of using clustered index scan, SQL Server will use non-clustered index scan which is far more efficient as long as sorting column is there. So it could make sense to at least create one index with all columns included to help that select. For example, if you have the system that always filter by client id and filter by other order columns, it could make sense to create index like that:

Next week I’ll show how to add total row count as part of the same statement.
Source code is available for download