One of the most challenging issues for developers who don’t live in RDBMS world is how to make the system working seamlessly in multi-user environment. The code which works perfectly in development and QA starts to fall apart when dozens of users access the system. There are timeouts, deadlocks and other issues that developer cannot even reproduce in house. It does not really matter that SQL Server uses row level locking, that transaction isolation level set to read uncommitted – locking, blocking and deadlocking still occurs.
Today I’m going to start the series of the posts about locking in Microsoft SQL Server. I’ll try to explain why blocking and deadlocks occur in the system, how you can troubleshoot related problems and what should you do in order to minimize it. We will cover different transaction isolation levels and see how and why it affects behavior of the system. And talk about quite a few other things.
Update (2018-01-23): Consider to read Part 21: Intro into Transaction Management and Error Handling first
So let’s start with the lock types. What is the lock? In short, this is in-memory structure (64 bytes on 32 bit OS or 128 bytes on 64 bit OS). The structure has the owner, type and resource hash that links it to the resource it protects (row, page, table, file, database, etc). Obviously it’s more complicated and has quite a few other attributes, but for our practical purposes that level of details is enough.
SQL Server has more than 20 different lock types but for now let’s focus on the most important ones.
- Shared locks (S). Those locks acquired by readers during read operations such as SELECT. I’d like to mention that it happens in most part of the cases but not all the time. There are some cases when readers don’t acquire (S) locks. We will talk about it later.
- Exclusive locks (X). Those locks acquired by writers during data modification operators such as Insert, Update or Delete. Those locks prevent one object to be modified by the different sessions. Those locks are always acquired and held till end of transaction
- Update locks (U). Those locks are the mix between shared and exclusive locks. SQL Server uses them with data modification statements while searching for the rows need to be modified. For example, if you issue the statement like: “update MyTable set Column1 = 0 where Column1 is null” SQL Server acquires update lock for every row it processes while searching for Column1 is null. When eligible row found, SQL Server converts (U) lock to (X).
- Intent locks (IS, IX, IU, etc). Those locks indicate locks on the child objects. For example, if row has (X) lock, it would introduce (IX) locks on page, table and database level. Main purpose of those locks is optimization. This about situation when you need to have exclusive access to the database (i.e. (X) lock on database level). If SQL Server did not have intent locks, it would have to scan all rows in the all objects and see if there are any low level locks acquired.
Obviously the biggest question is lock compatibility. If you open MSDN site you’ll see nice and “easy to understand” matrix with more than 400 cells. But for our practical purpose let’s focus on the smaller version:
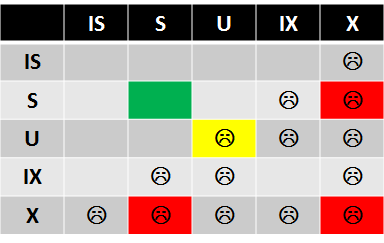
So what we need to remember are basically 3 things:
- (S) locks are compatible with (S) and (U) locks.
- (X) locks are incompatible with any other lock types
- (U) locks are compatible with (S) but incompatible with (U)
Simple enough. Next time we will look at transaction isolation levels and see how it affects lock behavior.
Can you please add a link to the glossary to each individual page? I’m trying right now to find the first page with the content and already spent 10 minutes looking…
Yes u r wright.
Can you elaborate a bit on the meaning of “(S) locks are compatible with (S) and (U) locks” ?
Hi Panco,
(S) locks are compatible with (S) locks – basically it means that multiple sessions can read (SELECT) the same row simultaneously.
(U) locks are issued during update scans. When SQL Server looks for the data to update, it acquires (U) lock while reading/checking if row needs to be updated. Then, if row does not need to be updated, SQL Server releases (U) lock. Otherwise it converts (U) lock to exclusive (X) lock. (S) lock is compatible with (U) lock – so session that reads (SELECT) the data could read the row with (U) lock acquired. It would not be able to read the row in case if (U) lock has been converted to (X) lock (e.g. data has been modified).
Hope this helps.
Couldn’t quite get what green, yellow, red, light grey, bright grey colors in table mean?
Hi Micha,
Green means – “no blocking – we are fine”. Red – “here is the blocking, which could affect us”, Yellow – “here is the blocking, but that is usually short-term condition”.
Perhaps I need to be less creative with the colors 🙂
Sincerely,
Dmitri
BTW, the comments are being dumped (disappear without any reaction) if to fill the “Website:” field in comments
I am moderating comments before they appears. Way too many spam comes through without it
Hello!
I tried to reproduce X-IS deadlock like you did in one of your presentation. In this session I have read uncommited transaction with escalation lock, when I try to update 10000 records. In another session, I try to select other record in the same table. Everything works fine.
Would you please help to understand why I get Sch-S lock when I simply select everything from particular table (this table alredy has X lock), instead of having IS lock that I would expect.
Hi Sergei,
What isolation level are you running your SELECT under? You will get Sch-S instead of IS in READ UNCOMMITTED, READ COMMITTED SNAPSHOT and SNAPSHOT levels. If you used default READ COMMITTED level, I’d suspect that you have READ_COMMITTED_SNAPSHOT db option enabled and, therefore, execute it in READ COMMITTED SNAPSHOT mode. You can check it by querying sys.databases.
Sincerely,
Dmitri