If you asked the database developer about referential integrity, everybody would agree that it’s “must have” feature. Implementation though is the different question. There are quite a few ways how you can implement it and, of course, it’s impossible to say which way is the right one. As usual, it depends.
I’d like to talk about referential integrity in general and discuss pros and cons of the different implementation methods. I’m not trying to cover every possible implementation method and focus on a few most obvious ones.
So first of all, why referential integrity is good? Quite a few obvious reasons:
- It makes sure that data is clean
- It helps query optimizer (in some cases)
- It helps to detect some bugs in the code on the early stages.
As for the negative side, it always introduces some performance implications. In most part of the cases those implications are minor. Although in some cases you need to take them into the consideration.
So let’s take a look at the different implementation approaches. First, foreign key constraints. Probably most known method. When you use this method, everything is automatic. SQL Server checks the existence of the master (referenced) row when detail (referencing) row is inserted. And vice verse. Now let’s think about the implications. Let’s create the tables and populate it with some data.

Now let’s create the foreign key constraint.
Now let’s enable “display actual execution plan” and insert data to the OrderItems table.

Obviously SQL Server needs to make sure that master row exists. So it adds clustered index seek on the Orders table to the picture. Now let’s try deletion of the master row:
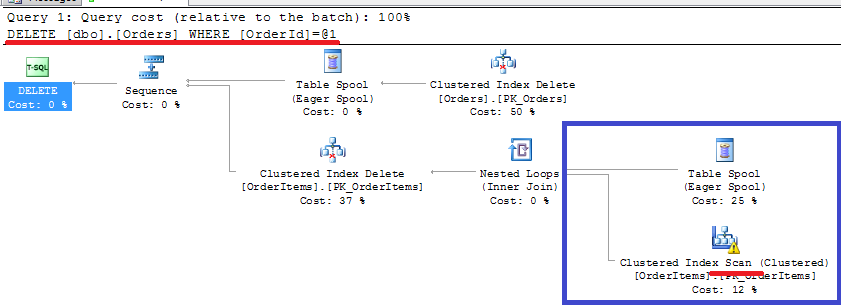
Oops. Clustered index SCAN on the OrderItems table. This is the most common mistake database developers do – when you create the foreign key, SQL Server requires to have unique index on the referenced (Master) column. But it does not automatically create the index on the referencing (Detail) column. And now think if you have millions of the rows in OrderItems table.. Ohh..
Let’s add the index and try again:
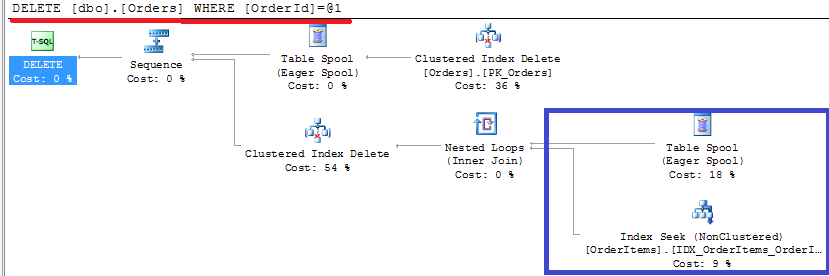
As you can see, non-clustered index seek. Better now. So at the end, when you have foreign keys in the database, every deletion from the master table introduces index seek in the detail table. Every insert into the detail table introduces index seek in the master table. Plus you need to maintain the index on the detail table. Most likely, those issues would not be critical unless the system is really big and under heavy load. But you need to be aware of it.
Another limitation we need to be aware of is partition switch. You cannot switch the partition if table is referenced by other tables. So if this is the case, you need to implement other approaches we will discuss next week.
Code is available for download
Nice explanation, Referential Integrity in SQL is one of the fundamental concept but often programmer underestimate and underutilized it.