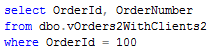Last time we discussed a few major lock types that SQL Server uses. Shared(S), Exclusive(X) and Update(U). Today I’d like to talk about transaction isolation levels and how they affect locking behavior. But first, let’s start with the question: “What is transaction?”
Transaction is complete unit of work. Assuming you transfer money from checking account to saving, system should deduct money from the checking and add it to the saving accounts at once. Even if those are 2 independent operations, you don’t want it to “stop at the middle”, well at least in the case if bank deducts it from the checking first 🙂 If you don’t want to take that risk, you want them to work as one single action.
There is useful acronym – ACID – that describes requirements to transaction:
- (A) – Atomicity or “all or nothing”. Either all changes are saved or nothing changed.
- (C) – Consistency. Data remains in consistent stage all the time
- (I) – Isolation. Other sessions don’t see the changes until transaction is completed. Well, this is not always true and depend on the implementation. We will talk about it in a few minutes
- (D) – Durability. Transaction should survive and recover from the system failures
There are a few common myths about transactions in SQL Server. Such as:
- There are no transactions if you call insert/update/delete statements without begin tran/commit statements. Not true. In such case SQL Server starts implicit transaction for every statement. It’s not only violate consistency rules in a lot of cases, it’s also extremely expensive. Try to run 1,000,000 insert statements within explicit transaction and without it and notice the difference in execution time and log file size.
- There is no transactions for select statements. Not true. SQL Server uses (lighter) transactions with select statements.
- There is no transactions when you have (NOLOCK) hint. Not true. (NOLOCK) hint downgrades the reader to read uncommitted isolation level but transactions are still in play.
Each transaction starts in specific transaction isolation level. There are 4 “pessimistic” isolation levels: Read uncommitted, read committed, repeatable read and serializable and 2 “optimisitic” isolation levels: Snapshot and read committed snapshot. With pessimistic isolation levels writers always block writers and typically block readers (with exception of read uncommitted isolation level). With optimistic isolation level writers don’t block readers and in snapshot isolation level does not block writers (there will be the conflict if 2 sessions are updating the same row). We will talk about optimistic isolation levels later.
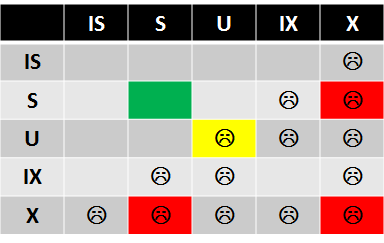
Regardless of isolation level, exclusive lock (data modification) always held till end of transaction. The difference in behavior is how SQL Server handles shared locks. See the table below:

So, as you can see, in read uncommitted mode, shared locks are not acquired – as result, readers (select) statement can read data modified by other uncommitted transactions even when those rows held (X) locks. As result any side effects possible. Obviously it affects (S) lock behavior only. Writers still block each other.
In any other isolation level (S) locks are acquired and session is blocked when it tries to read uncommitted row with (X) lock. In read committed mode (S) locks are acquired and released immediately. In Repeatable read mode, (S) locks are acquired and held till end of transaction. So it prevents other session to modify data once read. Serializable isolation level works similarly to repeatable read with exception that locks are acquired on the range of the rows. It prevents other session to insert other data in-between once data is read.
You can control that locking behavior with “set transaction isolation level” statement – if you want to do it in transaction/statement scope or on the table level with table hints. So it’s possible to have the statement like that:
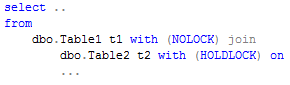
So you access Table1 in read uncommitted isolation level and Table2 in serializable isolation level.
It’s extremely easy to understand the difference between transaction isolation levels behavior and side effects when you keep locking in mind. Just remember (S) locks behavior and you’re all set.
Next time we will talk why do we have blocking in the system and what should we do to reduce it.