I don’t like views. I like layers of abstractions, dedicated tiers in the system but I don’t like views. It seems kind of strange – regular views are basically the abstraction on the metadata layer. Nothing less, nothing more. It gives you some benefits in terms of security, some benefits of the code abstraction. I just think that views introduce more problems than they solves.
Today I’d focus on one specific aspect of the views – I call it “joins hell”. Remember “dll hell” from the good old days? Maybe not too old, by the way.
Let’s create a couple tables and populate it with the data.


Let’s assume we want to have a view that joins both tables and returns client name in addition to orders column.
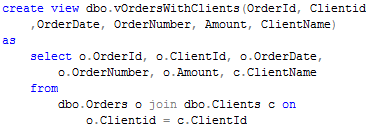
Simply enough. Natural enough especially if you come from imperative development world. You have the view as the abstraction and you can use it everywhere where you need to access orders. So let’s select the row including client name for one specific order.
![]()

Good. As you can see, it introduces 2 CI seek + join. You cannot do any better than that. Now, let’s say, you need to populate the list of the order numbers. So let’s run it again selecting OrderId and OrderNumber only (I’m still filtering out 1 single row but it hardly matters).
![]()
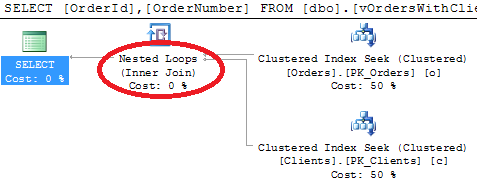
Oops – still join with the clients table even if you don’t need any columns from there. Well, if you think about that, it makes sense. If you use inner join in the view, SQL Server needs to make sure that every order has corresponding client and filter out orders without valid ClientId.
So first thing how to workaround it – use outer join instead.
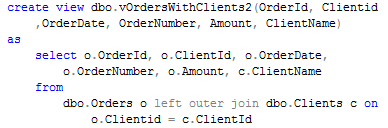
![]()
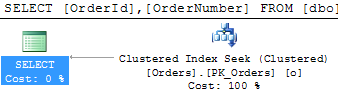
As you can see, in this example, SQL Server does not care, if order does not have corresponding client. It seeks in Orders table only. On other hand, outer join limits the choices optimizer has. It cannot switch between inner and outer record sets when processes nested loops and so on. So technically this is not the best option.
Another method is to add foreign key constraint (don’t forget to add the index on Orders.ClientID column to avoid performance hit). If you run the original select you see, that SQL eliminates the join. By the way, if you decide to run demo scripts – make sure to use regular db. TempDb does not have joins elimination.
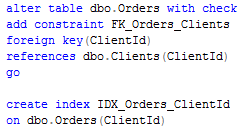
Looks like it solves our problems but unfortunately there are some cases when foreign key constraints cannot be created. And there are some cases when SQL Server cannot eliminate the joins even with constraints. Look here (click to open the plan on the different window):

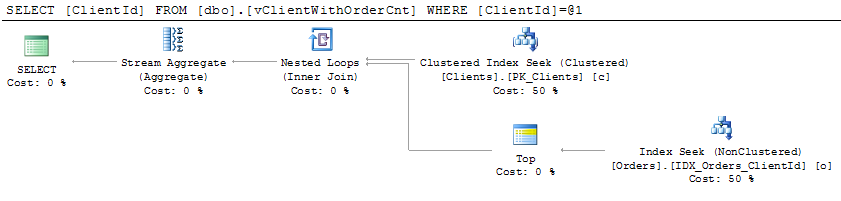
So we don’t know if SQL will be able to eliminate the joins all the times even with all foreign keys in place. What we know for sure, that SQL does not do that if you have multi-column foreign keys. Let’s see that. First let’s create the same Orders and Clients tables with additional Int1 column.

Now let’s create the view and run the same select and see the plan.

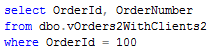

As you can see, SQL still does the join. This is one of “design limitations” SQL Server has – no join elimination with multi-column foreign keys.
And if you think about that, this is very simple case. I saw some systems with the views that includes 20+ joins and at the end every select against them introduces a lot of extra IO you don’t need. So I always ask myself – are those minor benefits views give you worth the efforts?
Source code is available for download.