Last week we discussed foreign key constraints as the way to implement referential integrity. Today I’d like to focus on the other implementation approaches.
First of all, let’s try to outline the situations when foreign key constraints would not work for you
- If you need to reference the table involved in partition switch. SQL Server simply does not allow it.
- When you have the situation when detail and master data can be inserted/deleted out of order. For example, in my system we have 2 streams of transactional data and one stream is referencing another. Those streams are collected and processed differently so we cannot guarantee that master data row would be inserted prior detail data row. So foreign key constraints are not the options for us.
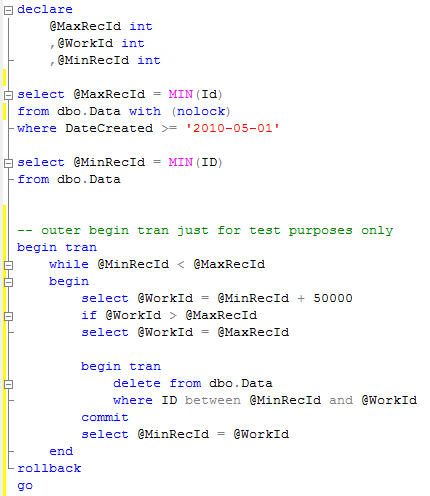
- When additional index on detail (referencing) column is not appropriate. This one is interesting. There are some cases when you don’t want to maintain/support another index on the table. This approach would not work very well if you want to delete detail rows same time with the master rows. If this requirement is not critical, you can purge detail rows once per night even if it forces scan(s) of detail table). In some cases it makes sense.
How to accomplish it? First, you can handle it in the client code. Generally this solution is not really good and could easily become nightmare, especially in the case if system does not have dedicated data access layer/tier code. With data access layer (especially if it’s done on the database side via stored procedures) it’s not so simple. On one hand it gives you all control possible you don’t have with the triggers. On the other, you need to make sure that there are no code, especially legacy code, that does not use data access layer/tier code. And you also need to be sure that same would be true at the future. Again, in some cases it could make sense. It depends.
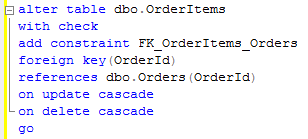
Second, obvious method, is using triggers. Frankly I don’t see any benefits of using triggers in compare with actual foreign key constraints in the case, if you have deletion statement in the trigger. Although, something like that can make sense (it uses the same tables created last week):

As you can see, trigger simply inserts list of deleted OrderIds to the queue. Next, you can have sql server job running during off-peak hours that deletes the data from detail table.

That example covers the case with deletion of the master rows. As for detail (referencing) side, there are a couple things you can do. First is the trigger:

Second is using user-defined function and check constraint.

This approach could be better than trigger because it does not fire the validation if OrderId has not been changed.
In any case – to summarize:
- Referential integrity is generally good.
- It makes sure that data is clean
- It helps optimizer in some cases
- It helps to detect the errors on the early stages
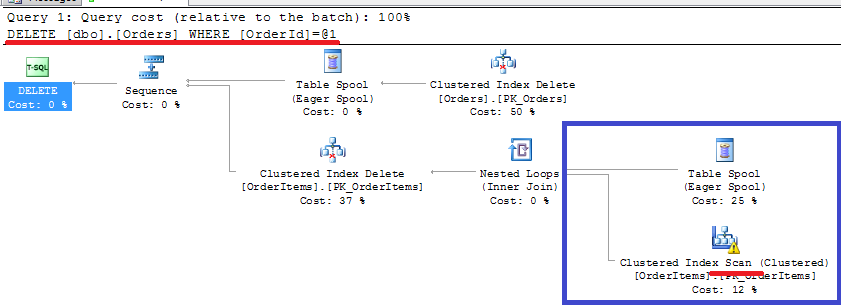
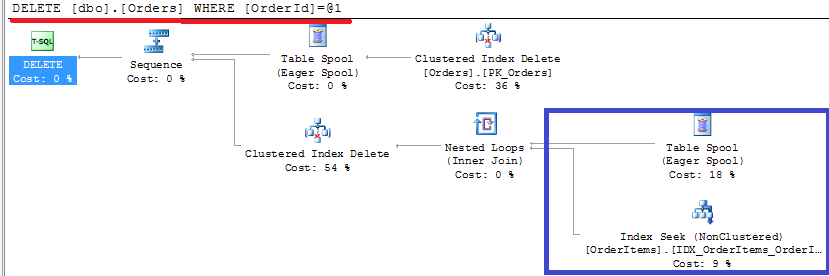
- Referential integrity always introduces performance implications regardless of implementation. Although in most part of the systems those implications are minor. If you cannot afford to have referential integrity implemented in your system, always enable it during DEV/QA stages. Be careful and disable it for the performance testing though because foreign key constraints could change the plan
- Use foreign keys unless you have specific cases described above
- Do not use referential integrity in the code/data access tier only UNLESS you have absolute control over the database and absolutely sure that nothing would change at the future. And think twice about it.