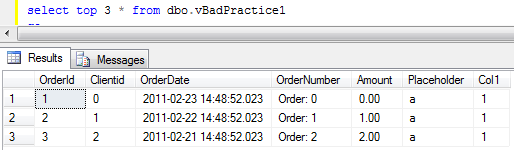
Even if it sounds almost the same as the regular views, indexed views are completely different animals. That type of the views are not only about the abstraction but more about performance. When you create the indexed view, SQL Server “materializes” the data in the view into physical table so instead of doing complex joins, aggregates, etc, it can queries the data from that “materialized” table. Obviously it’s faster and more efficient.
Let’s take a look at that using our favorite Clients and Orders table. Before we begin, I’d like to mention that there are quite a few requirements you have to met when you create the indexed views. And quite a few limitations. You can get more information in MSDN (http://msdn.microsoft.com/en-us/library/ms191432.aspx).
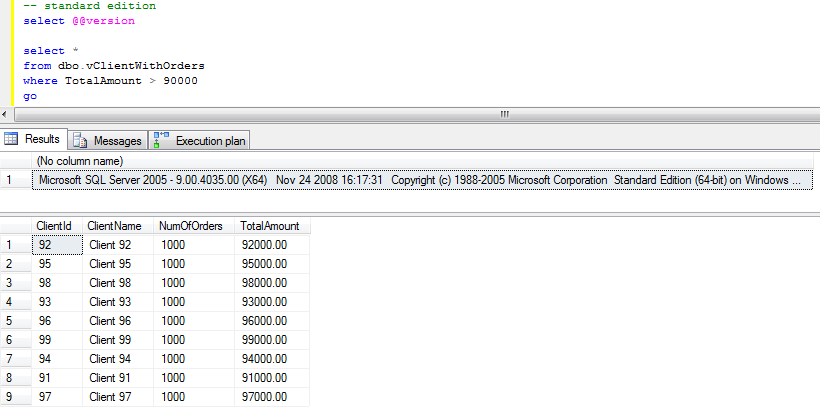
So let’s run the query that return the list of the clients who spends more than 900,00 for the orders together with # of orders.



Now let’s create the indexed view.
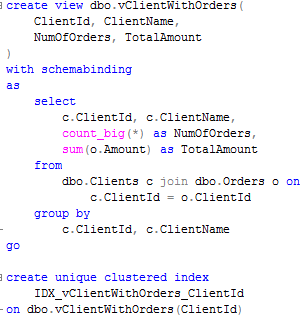
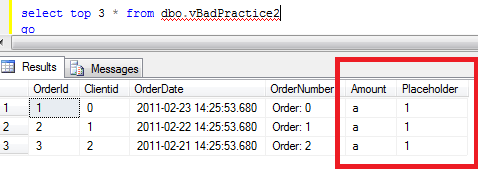
Now let’s run the query against this view.

![]()

As you can see the situation is dramatically improved. But that’s not all. Now let’s run the original statement in Enterprise edition of SQL Server and see the plan. And this is the magic – even if you don’t reference the view in the select, SQL Server founds that it can use the view for this select.

This is in fact very good optimization technique if you need to deal with 3rd party applications. If vendor does not allow you to change the indexes on the tables, you can create indexed views and SQL Server Enterprise edition will use them automatically. Unfortunately this is not the case with other editions but Enterprise and Developer. Let’s see that:
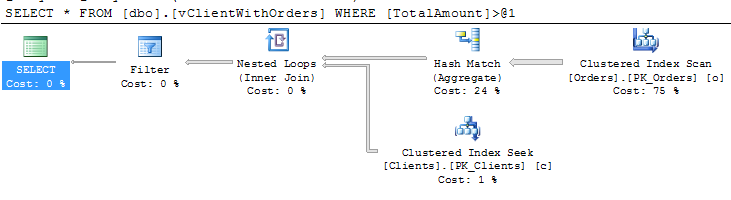
With the standard edition of SQL Server it does not even use “materialized” data by default. If you want to force SQL to use the view data, you have to use (noexpand) hint.
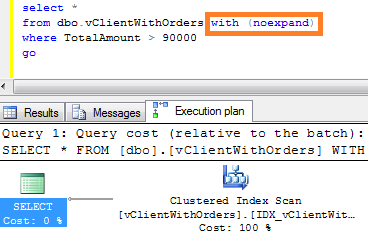
Obviously, other magic, like using the view indirectly would not work either.

What does it mean for you? First of all, if you expect to support different editions of SQL Server backend, you should keep this behavior and noexpand hint in mind. Obviously optimization technique for 3rd party applications would not work either.
Last thing I’d like to show is performance implications. Let’s insert the new order.

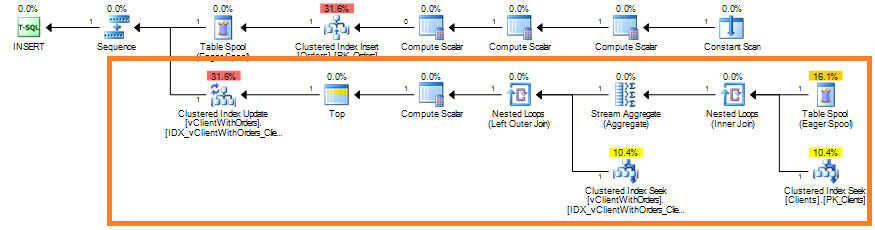
As you can see, it introduces nice performance hit because of the view support. Similar to the indexes – you have to pay the price of view maintenance for the benefit of performance improvements. Is it worth to do in your system? Hard to say especially if you have heavy loaded OLTP system. For Data Warehouse/Reporting/OLAP systems it could greatly benefit you. Another thing to keep in mind – indexed views shine when you use them with the aggregates.
Source code is available for download