Last time we have discussed how parameter sniffing can affect the quality of generated execution plans. Today, I would like to talk about another aspect of plan caching, which is plan reuse. Plans, cached by SQL Server, must be valid for any combination of parameters during future calls that reuse the plan. In some cases, this can lead to situations where a cached plan is suboptimal for a specific set of parameter values.
One of the common code patterns that leads to such situations is the implementation of stored procedure that search for the data based on a set of the optional parameters. Let’s look at the typical implementation of such stored procedure as shown in the code below. That code uses dbo.Employees table from the “parameter sniffing” post and it also creates two nonclustered indexes on that table.
create proc dbo.SearchEmployee ( @Number varchar(32) = null ,@Name varchar(100) = null ) as begin select Id, Number, Name, Salary, Country from dbo.Employees where ((@Number is null) or (Number=@Number)) and ((@Name is null) or (Name=@Name)) end go create unique nonclustered index IDX_Employees_Number on dbo.Employees(Number); create nonclustered index IDX_Employees_Name on dbo.Employees(Name);
There are several different approaches how SQL Server can execute the query from the stored procedure based on what parameters were provided. In the large number of cases, the most efficient approach would be using Nonclustered Index Seek and Key Lookup operators. Let’s run the stored procedure several times with different parameter combinations and check the execution plans:
exec dbo.SearchEmployee @Number = '10000'; exec dbo.SearchEmployee @Name = 'Canada Employee: 1'; exec dbo.SearchEmployee @Number = '10000', @Name = 'Canada Employee: 1'; exec dbo.SearchEmployee @Number = NULL, @Name = NULL;
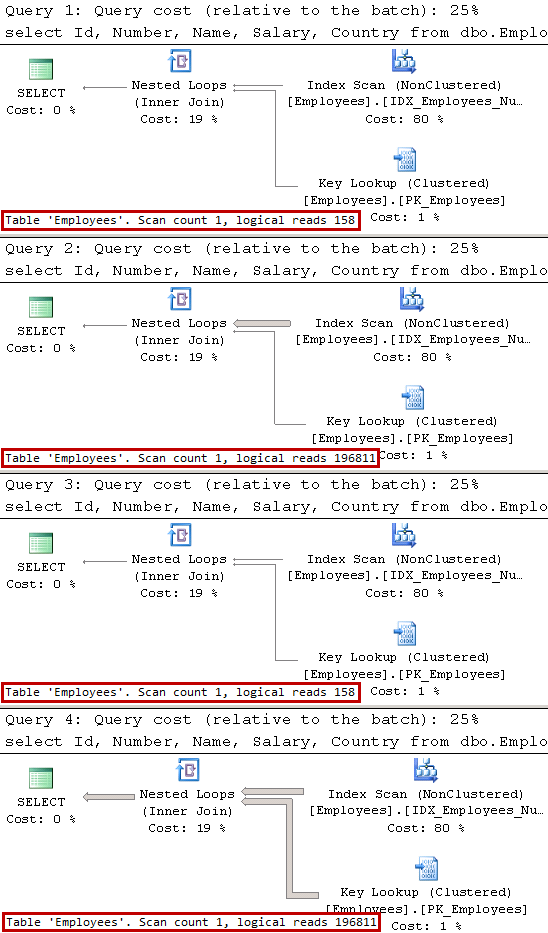
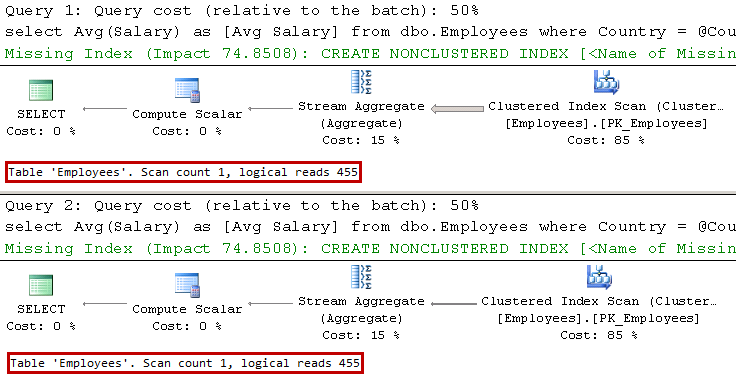
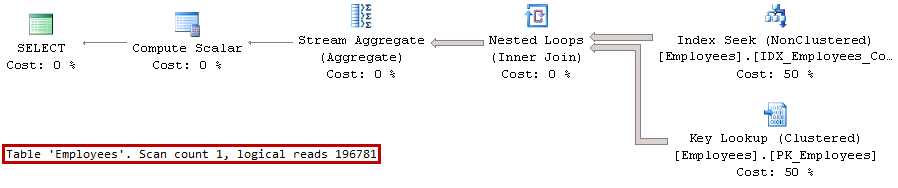
01.Execution Plans When Plans Are Cached
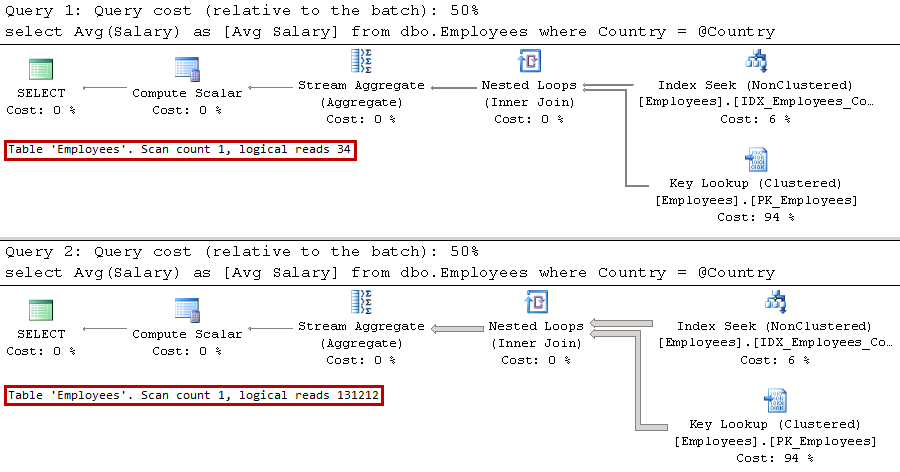
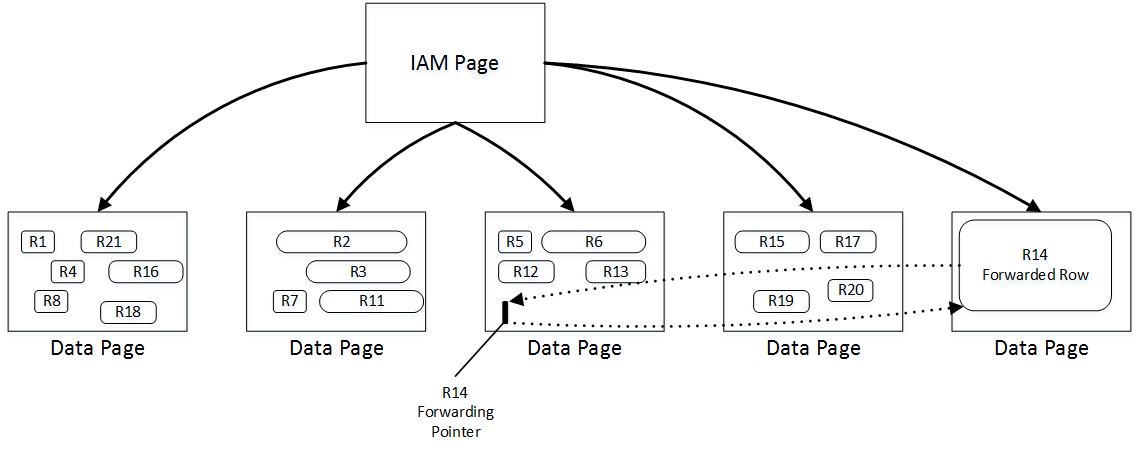
SQL Server compiles stored procedure at time of the first call when only @Number parameter was provided. Even though, the most efficient execution plan for this case is IDX_Employees_Number Index Seek operation, SQL Server cannot cache such execution plan because it would not be valid for the case, when @Number parameter is NULL. Therefore, SQL Server generated and cached execution plan that utilizes Index Scan operation, which is highly inefficient in case, when @Number parameter is not provided. In that case, SQL Server performs Key Lookup operation for every row in the nonclustered index optionally evaluating predicate on @Name parameter afterwards.
Similar to parameter sniffing issues, you can address this problem with statement-level recompilation as it is shown below. SQL Server recompiles the query on every call, and therefore it can choose the most beneficial execution plan for every parameter set.
It is also worth mentioning that the plans are not cached in cases where statement-level recompile is used.
alter proc dbo.SearchEmployee ( @Number varchar(32) = null ,@Name varchar(100) = null ) as begin select Id, Number, Name, Salary, Country from dbo.Employees where ((@Number is null) or (Number=@Number)) and ((@Name is null) or (Name=@Name)) option (recompile) end

02.Execution Plans With Statement-Level Recompile
As we already discussed, query recompilation adds CPU overhead. That overhead can be acceptable in case of large and complex queries when compilation time is just the fraction of the query execution time and system is not CPU-bound. In that case, recompilation can even help producing the better execution plans, which would be generated based on the current parameter values, especially if table variables are involved. However, this recompilation overhead is usually not acceptable in case of OLTP queries that are called very often.
One of the options you can use to address the issue is writing multiple queries using IF statements covering all possible combinations of parameters. SQL Server would cache the plan for each statement in the procedure. Listing below shows such an approach, however it quickly becomes unmanageable with a large number of parameters. The number of combinations to cover is equal to the number of parameters squared.
alter proc dbo.SearchEmployee ( @Number varchar(32) = null ,@Name varchar(100) = null ) as begin if @Number is null and @Name is null select Id, Number, Name, Salary, Country from dbo.Employees else if @Number is not null and @Name is null select Id, Number, Name, Salary, Country from dbo.Employees where Number=@Number else if @Number is null and @Name is not null select Id, Number, Name, Salary, Country from dbo.Employees where Name=@Name else select Id, Number, Name, Salary, Country from dbo.Employees where Number=@Number and Name=@Name end
In the case of a large number of parameters, dynamic SQL becomes the only option. SQL Server will cache the execution plans for each dynamically generated SQL statement. Remember that using dynamic SQL breaks ownership chaining, and it always executes in the security context of CALLER. You should also always use parameters with dynamic SQL to avoid SQL Injection.
alter proc dbo.SearchEmployee ( @Number varchar(32) = null ,@Name varchar(100) = null ) as begin declare @SQL nvarchar(max) = N' select Id, Number, Name, Salary, Country from dbo.Employees where 1=1' if @Number is not null select @Sql = @SQL + N' and Number=@Number' if @Name is not null select @Sql = @SQL + N' and Name=@Name' exec sp_executesql @Sql, N'@Number varchar(32), @Name varchar(100)' ,@Number=@Number, @Name=@Name end
While most of us are aware about danger of using optional parameters and OR predicates in the queries, there is another less known issue associated with filtered indexes. SQL Server will not generate and cache a plan that uses a filtered index, in cases when that index cannot be used with some combination of parameter values.
Listing below shows an example. SQL Server will not generate the plan, which is using the IDX_RawData_UnprocessedData index, even when the @Processed parameter is set to zero because this plan would not be valid for a non-zero @Processed parameter value.
create unique nonclustered index IDX_RawData_UnprocessedData on dbo.RawData(RecID) include(Processed) where Processed = 0; -- Compiled Plan for the query would not use filtered index select top 100 RecId, /* Other columns */ from dbo.RawData where RecID > @RecID and Processed = @Processed order by RecID;
In that particular case, rewriting the query using IF statement would be, perhaps, the best option.
if @Processed = 0 select top 1000 RecId, /* Other Columns */ from dbo.RawData where RecId > @RecId and Processed = 0 order by RecId; else select top 1000 RecId, /* Other Columns */ from dbo.Data where RecId > @RecId and Processed = 1 order by RecId;
Unfortunately, IF statement does not always help. In some cases, SQL Server can auto-parametrize the queries and replace some of the constants with auto-generated parameters. That behavior allows SQL Server to reduce the size of the plan cache; however, it could lead to all plan reuse issues we have already discussed.
By default, SQL Server uses SIMPLE parametrization and parametrize only the simple queries. However, if database or query are using FORCED parametrization, that behavior can become the issue. Let’s look at a particular example and create a database with a table with a filtered index and populate it with some data, as shown below.
use master go create database ParameterizationTest go use ParameterizationTest go create table dbo.RawData ( RecId int not null identity(1,1), Processed bit not null, Placeholder char(100), constraint PK_RawData primary key clustered(RecId) ); /* Inserting: Processed = 1: 65,536 rows Processed = 0: 16 rows */ ;WITH N1(C) AS (SELECT 0 UNION ALL SELECT 0) -- 2 rows ,N2(C) AS (SELECT 0 FROM N1 AS T1 CROSS JOIN N1 AS T2) -- 4 rows ,N3(C) AS (SELECT 0 FROM N2 AS T1 CROSS JOIN N2 AS T2) -- 16 rows ,N4(C) AS (SELECT 0 FROM N3 AS T1 CROSS JOIN N3 AS T2) -- 256 rows ,N5(C) AS (SELECT 0 FROM N4 AS T1 CROSS JOIN N4 AS T2 ) -- 65,536 rows ,IDs(ID) AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM N5) insert into dbo.RawData(Processed) select 1 from Ids; insert into dbo.RawData(Processed) select 0 from dbo.RawData where RecId <= 16; create unique nonclustered index IDX_RawData_Processed_Filtered on dbo.RawData(RecId) include(Processed) where Processed = 0;
For the next step, let’s run the queries that count a number of unprocessed rows in both SIMPLE and FORCED parametrization modes.
select count(*) from dbo.RawData where Processed = 0 go alter database ParameterizationTest set parameterization forced go select count(*) from dbo.RawData where Processed = 0
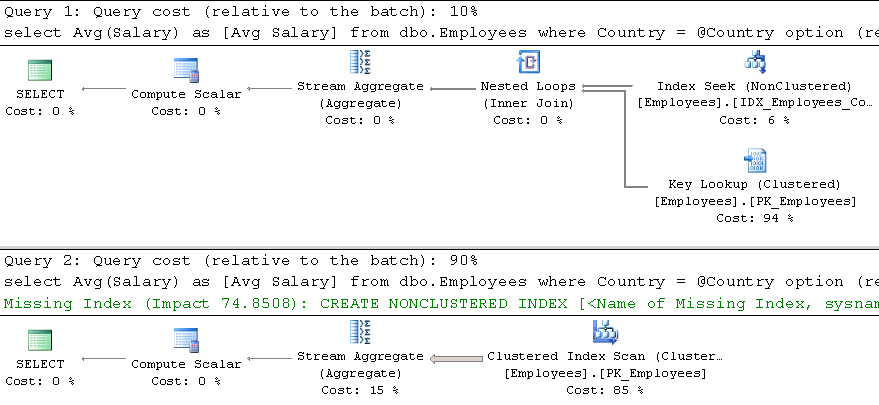
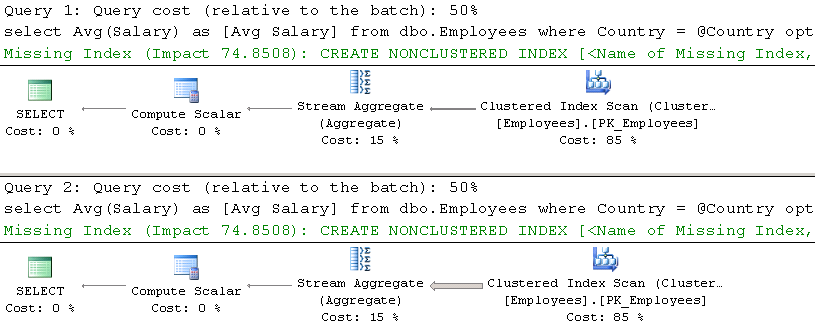
If you examine the execution plans shown in Figure 3, you will notice that SQL Server utilized a filtered index in the case of a SIMPLE parametrization. SQL Server can cache this plan because of the constant in the Processed=0 predicate. Alternatively, with FORCED parametrization, SQL Server parametrizes the query using the parameter in the Processed=@0 predicate. Therefore, it cannot cache the plan with the filtered index because it would not be valid for the case when a query selects processed (Processed=1) rows. SQL Server generated the execution plan with a Clustered Index Scan, which is far less efficient in this case.

03.Execution Plans and Parametrization
The workaround in this case is using SIMPLE parametrization for the database, or forcing it on query level with plan guide (more on it later). In some cases, you would also need to rewrite the query and use one of the constructs that prevent parametrization in SIMPLE parametrization mode, such as IN, TOP, DISTINCT, JOIN, UNION, subqueries and quite a few others.
Plan caching and plan reuse are the great features that help to reduce CPU load on the server. However, they introduce several side effects you need to be aware of and keep them in mind when you write queries and stored procedures.
Source code is available for download