The presentation is available for download from Presentations page
Tampa IASA Presentation
Leave a reply
The presentation is available for download from Presentations page
Last week we saw a few potential problems that views can introduce because of the extra IO and joins. Today I’ll show you the biggest “bad practice” with views and the simple way how to avoid it. All of us are lazy and sometimes it really backfires..
Let’s use the same tables (Clients and Orders) we had last week. Let’s add another column to Orders table and create the simplest view.

Now let’s query the view.
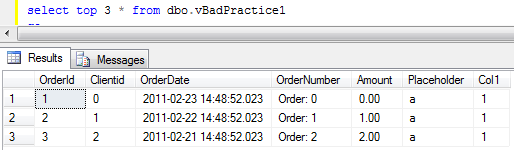
Simple, don’t you think? Now let’s add another column to the view and repeat the query.
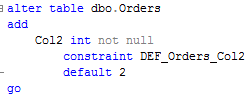
As you can see, it does not appear in the result set. Now let’s do the opposite action and drop both columns.

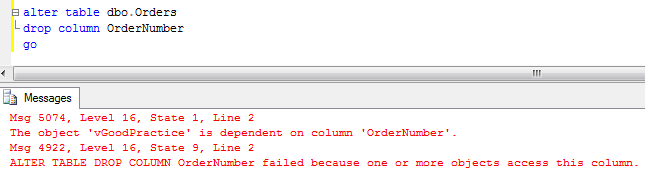
As you can see nothing prevents us from doing that. Although, if we run the same select again, we will get the following error.
![]()
If we check the catalog views, we can see that Col1 is still there. Unfortunately this is only the part of the problem. You can “recompile” view with sp_refreshview stored procedure but still…

Now let’s do another test. Let’s create another view first and next add and drop columns.

Now, if we run the select again, it would work although results would be completely screwed up. It returns Placeholder data as Amount (dropped column) and new Col1 data under Placeholder column. Can you imagine all wonderful side effects you can have on the client side?
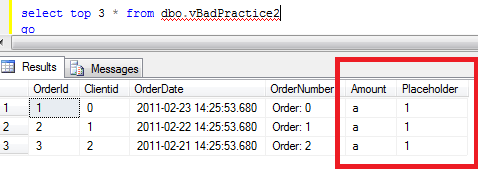
So speaking about that, first rule is never ever use “select *” in the view definition. This is the source of all potential problems. Second, the good practice is to use schemabinding option. With this option SQL Server links the view and underlying schema and does not allow any changes that can break the views.

Source code is available for download
Last week we discussed foreign key constraints as the way to implement referential integrity. Today I’d like to focus on the other implementation approaches.
First of all, let’s try to outline the situations when foreign key constraints would not work for you
How to accomplish it? First, you can handle it in the client code. Generally this solution is not really good and could easily become nightmare, especially in the case if system does not have dedicated data access layer/tier code. With data access layer (especially if it’s done on the database side via stored procedures) it’s not so simple. On one hand it gives you all control possible you don’t have with the triggers. On the other, you need to make sure that there are no code, especially legacy code, that does not use data access layer/tier code. And you also need to be sure that same would be true at the future. Again, in some cases it could make sense. It depends.
Second, obvious method, is using triggers. Frankly I don’t see any benefits of using triggers in compare with actual foreign key constraints in the case, if you have deletion statement in the trigger. Although, something like that can make sense (it uses the same tables created last week):

As you can see, trigger simply inserts list of deleted OrderIds to the queue. Next, you can have sql server job running during off-peak hours that deletes the data from detail table.

That example covers the case with deletion of the master rows. As for detail (referencing) side, there are a couple things you can do. First is the trigger:

Second is using user-defined function and check constraint.

This approach could be better than trigger because it does not fire the validation if OrderId has not been changed.
In any case – to summarize:
If you asked the database developer about referential integrity, everybody would agree that it’s “must have” feature. Implementation though is the different question. There are quite a few ways how you can implement it and, of course, it’s impossible to say which way is the right one. As usual, it depends.
I’d like to talk about referential integrity in general and discuss pros and cons of the different implementation methods. I’m not trying to cover every possible implementation method and focus on a few most obvious ones.
So first of all, why referential integrity is good? Quite a few obvious reasons:
As for the negative side, it always introduces some performance implications. In most part of the cases those implications are minor. Although in some cases you need to take them into the consideration.
So let’s take a look at the different implementation approaches. First, foreign key constraints. Probably most known method. When you use this method, everything is automatic. SQL Server checks the existence of the master (referenced) row when detail (referencing) row is inserted. And vice verse. Now let’s think about the implications. Let’s create the tables and populate it with some data.

Now let’s create the foreign key constraint.
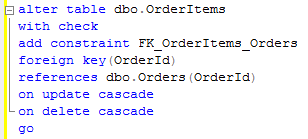
Now let’s enable “display actual execution plan” and insert data to the OrderItems table.

Obviously SQL Server needs to make sure that master row exists. So it adds clustered index seek on the Orders table to the picture. Now let’s try deletion of the master row:
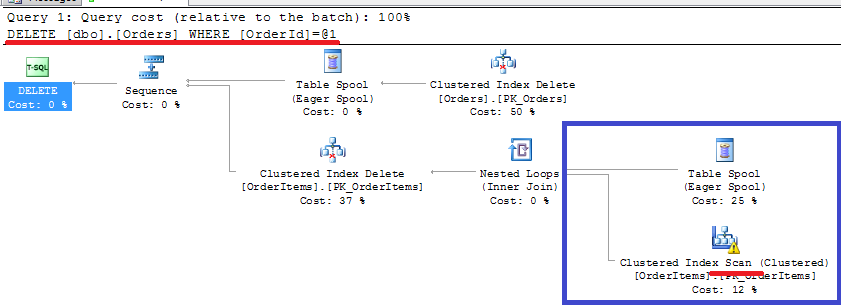
Oops. Clustered index SCAN on the OrderItems table. This is the most common mistake database developers do – when you create the foreign key, SQL Server requires to have unique index on the referenced (Master) column. But it does not automatically create the index on the referencing (Detail) column. And now think if you have millions of the rows in OrderItems table.. Ohh..
Let’s add the index and try again:
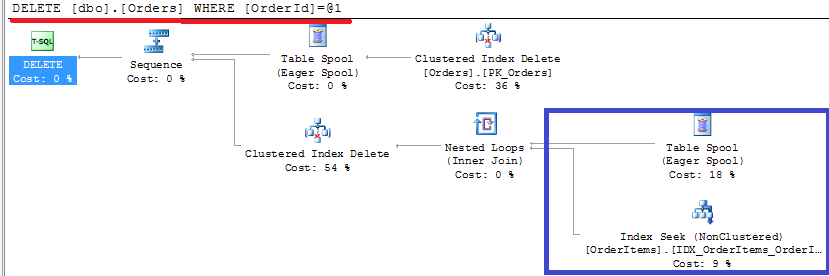
As you can see, non-clustered index seek. Better now. So at the end, when you have foreign keys in the database, every deletion from the master table introduces index seek in the detail table. Every insert into the detail table introduces index seek in the master table. Plus you need to maintain the index on the detail table. Most likely, those issues would not be critical unless the system is really big and under heavy load. But you need to be aware of it.
Another limitation we need to be aware of is partition switch. You cannot switch the partition if table is referenced by other tables. So if this is the case, you need to implement other approaches we will discuss next week.
Code is available for download
You can download the code from the presentations page. Thank you very much for attending!
As we already discussed, implementing of sliding window scenario is one of the biggest benefits you can get from table partitioning. Technically this is quite simple process – when time comes, you have to do 2 different actions:
There are quite a few resources that can show how you can achieve that from the technical standpoint. You can see the example in technet. I’m not going to focus on the implementation details and rather talk about a few less obvious aspects of the implementation.
Usually, we are implementing partitions on the Date basis. We want to purge data daily, monthly or yearly. The problem with this approach is that partition column needs to be included to the clustered index (and as result every non-clustered index). It means extra 4-8 bytes per row from the storage prospective and less efficient index because of bigger row size -> more data pages -> more IO. Obviously there are some cases when nothing can be done and you have to live with it. Although, in a lot of cases, those transaction tables have autoincremented column as part of the row and CI already. In such case, there is the great chance that date column (partition column candidate) would increment the same way with autoincremented ID column. If this is the case, you can think about partitioning by ID instead. This introduces a little bit more work – most likely you’ll
need to maintain another table with (Date,ID) correlations although it would pay itself off because of less storage and better performance requirements. Of course, such assumption cannot guarantee that row always ends up on the right partition. If, for example, insert is delayed, ID could be generated after the split. But in most part of the cases you can live with it.
Second thing is creating the new partition. Let’s take a look at the example. First, let’s create the partitioned table and populate it with some data.

This table has 2 partitions – left with ID <= 100,000 and right, with ID > 100,000. Let’s assume we want to create another partition for the future data (let’s even use ID=200,000 as the split point).

At this point, SQL needs to find out if some data needs to be moved to the new partition. As you can see, it produces a lot of reads. Now let’s try to create another partition with 300,000 as the split point.

As you can see – no IO in such case. So the rule is to always have one additional empty partition reserved. If you decide to accomplish partitioning by ID like we already discussed, make sure:
Last thing I’d like to mention is locking. Partition switch is metadata operation. Although it will require SCHEMA MODIFICATION (Sch-M) lock. This lock is not compatible with schema stability (SCH-S) lock SQL Server issues during query compilation/execution. If you have OLTP system with a lot of concurrent activity, make sure the code around partition switch/split handles lock timeouts correctly.
Source code is available here
Also – check this post – it could give you some tips how to decrease the possibility of deadlocks during partition/metadata operations.
Last week we started to discuss table partitioning and specified a few cases when partition is really useful. Today I want to focus on the downsides of the process.
First, column used in the partition function needs to be included into the clustered index (and as result all non-clustered indexes). Unless this column is ALREADY part of the clustered index, it means you’re increasing non-clustered index row size. And think about it – you typically partition the large table with millions of rows (what is the reason to partition the small tables?). With such number of rows, index size matters. From both – storage size prospective and index performance.
Another interesting thing – that unless you have rare case when you don’t want index to be aligned, partitioned column should be included into the index definition. It would not increase the row size (CI values are part of the NCI rows anyway), but it could break the indexes you’re using to check uniqueness of the data.
Next, you cannot do partition switch if table is replicated with SQL Server 2005. Fortunately SQL Server 2008 addresses this issue.
Next, you cannot do partition switch if table is referenced by other tables. Typically it’s not an issue for the large transaction tables but still – it could happen.
And now let’s see the worst one. When index is aligned, the data is distributed across multiple partitions. And regular TOP operator does not work anymore. Let’s see that in example. First let’s create the table and populate it with some data.

Now, let’s run the select that get TOP 100 rows:

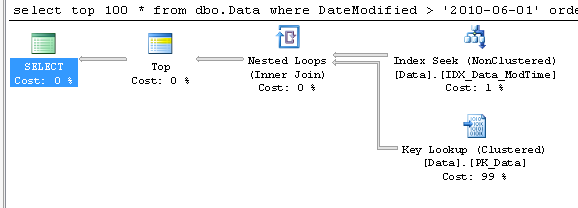
As you can see the plan is straight-forward – TOP and INDEX SEEK.
Now let’s partition that table by DateCreated.

And run the same select.
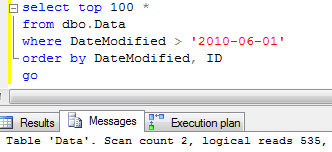
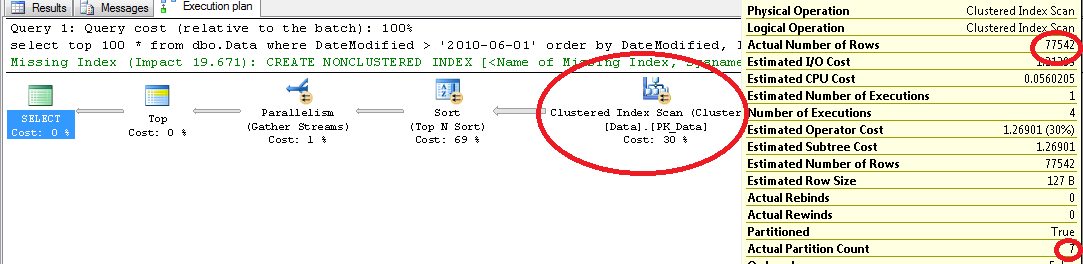
Surprisingly it uses clustered index scan. Let’s try to force SQL to use index:
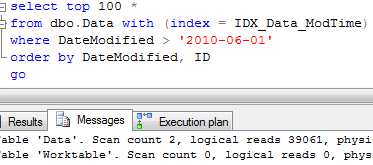

As you can see, it introduces 100 times more reads. Let’s think about it for a minute. Why does it happen?
Think about first example with non-partitioned table. Index data is sorted by DateModified and ID.
![]()
So when you run the select like above, SQL Server needs to locate the first row in the index and continue to scan index forward for the next 100 rows. Sweet and simple.
Now let’s think about partition case. We partition index by DateCreated – 3rd column in the index. This column affects the placement of the index row to specific partition. And index is sorted by DateModified and ID only within the partition. See example below – you can see that the row with DateModified = 2010-01-02 can be placed on the first partition because it controlled by DateCreated.
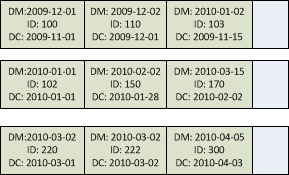
Now let’s think how SQL Server runs the select if it uses the index. For each partition on the table it selects the first row that matches the predicates and scan forward entire partition up to the end. Next, it merges results from all partitions, does the sort and next selects TOP N rows from all the partitions. As you can see, it introduces huge performance hit. I wish SQL Server would be smart enough to scan only N row from each partition, but unfortunately it’s not the case. It scans everything.
Unfortunately there is no simple workaround. This is something you need to live with.
Update (2011-12-18) – Well, there is the workaround that would work in some cases. Check it out here: http://aboutsqlserver.com/2011/12/18/sunday-t-sql-tip-select-top-n-using-aligned-non-clustered-index-on-partitioned-table/
Update (2012-03-11) – Another, more clean and generic workaround – http://aboutsqlserver.com/2012/03/11/sunday-t-sql-tip-aligned-non-clustered-indexes-on-partitioned-table-again/
Source code is available for download.
Next week we will talk about sliding window implementation.
If you’re the lucky user of SQL Server 2005/2008 Enterprise Edition, there is the good chance that you already have table partitioning implemented. Granted, this is one of the best new features introduced in SQL Server 2005 and there were a lot of talks when it was released. Same time, it introduces a few issues and limitations you need to be aware of before the implementation.
I’d like to talk about it in more details. There will be 4 parts in that talk. Today I’m going to be positive – or tell about a few examples when the partitioning benefits you. Next time I’ll show when partitioning is not the best candidate and demonstrate a few interesting side effects you can have in the system. Next, I’ll talk about specific implementation case – Sliding Window and show a couple tricks that can make it more efficient. And at last, I’ll focus on a few other techniques that can replace partitioning if you’re using other editions of SQL Server.
I’d like to talk about it in more details. There will be 4 parts in that talk. Today I’m going to be positive – or tell about a few examples when the partitioning benefits you. Next time I’ll show when partitioning is not the best candidate and demonstrate a few interesting side effects you can have in the system. Next, I’ll talk about specific implementation case – Sliding Window and show a couple tricks that can make it more efficient. And at last, I’ll focus on a few other techniques that can replace partitioning if you’re using other editions of SQL Server.
So what is the table partitioning? There are ton of documentations and white papers (http://msdn.microsoft.com/en-us/library/ms345146%28SQL.90%29.aspx) that can give you a lot of details on implementation level. But let’s keep it simple. Partitioning is the internal storage separation for the subset of the data in the entity. Think about it as about one “virtual” table and multiple “internal” tables which store and combine data seamlessly to the client. Again, I’m not going to focus on implementation and internal details – let’s think about it from the logical standpoint.
Let’s think about specific functional use-cases when it’s beneficial.
The biggest point though is manageability. Different partitions can reside on the different filegroups. It means, you can:
Performance though is the interesting question. SQL Server (especially 2008) has improved algorithms for the parallel execution on partitioned tables. This is definitely good thing for reporting/data warehouse type systems. As for OLTP – it should not be the case. If OLTP system constantly accesses the data from the multiple partitions in one statement, most likely there are some issues in the system. Same time, there are some performance implications I’ll show you next time.
So partitioning is good when you need partitioning. Otherwise it makes the situation worse. Will talk about some performance implications next time.
As we remember from the last week – there are 3 requirements for the clustered index. It needs to be unique, static and narrow. Let’s think about identity and GUID – what is more appropriate for that.
Let’s add one other factor into consideration.
Identity is increasing monotonously. It means that SQL Server fills data pages one-by-one. That’s typically not a bad thing – it introduces high fillfactor and reduces the fragmentation unless you have the table with really high number of inserts. In such case the system will have contention in the extents allocation. The number varies based on the multiple factors – row size, hardware, etc. I would not worry about that unless I have at least a few hundred inserts per second. In such case I would like to have the clustered index that distributes the load across entire table. (And let’s be realistic – in such case I want to have clustered index that covers most critical queries).
GUID could behave similarly to Identity when it generated with NewSequentialId() or random when generated with NewId(). This is probably the most important difference besides the size. So technically, you can alter the behavior with one default constraint, although again, I’m not sure that GUID is a good choice for the transactional tables anyway.
So use GUID if:
Otherwise use identity.
Primary key looks similar to the clustered index but it’s not the same.
Primary key is the logical concept. Clustered index is the physical concept. By default SQL Server creates the clustered index on the table primary key. But this is default behavior only


How to choose correct clustered index? Obviously it would be beneficial for the system if clustered index covers most frequent/important queries. Unfortunately in real life it’s not always possible. Although there are 3 criteria you need to use. Those criteria are straightforward if you remember the structure of the indexes. I will post 2 old images here:
Clustered index:

Non-clustered index:

So what are the criteria?
Those 3 factors are important. You have to keep them in mind when you design the table.
Update (2011-11-24). I covered Unifuifiers in much greater depth in that post