Long time ago we discussed that good clustered index needs to be unique, static and narrow. I mentioned that internally SQL Server needs to be able to unique identify every row in the table (think about non-clustered index key lookup operation) and in case, if clustered index is not defined as unique, SQL Server adds 4 bytes uniquifier to the row. Today I want us to talk about that case in much more details and see when and how SQL Server maintains that uniquifier and what overhead it introduces.
In order to understand what happens behind the scene we need to look at the physical row structure and data on the page. First, I have to admit, that general comment about 4 bytes uniquifier overhead was not exactly correct. In some cases overhead could be 0 bytes but in most cases it would be 2, 6 or 8 bytes. Let’s look at that in more details. Click on the images below to open them in the new window.
First, let’s create 3 different tables. Each of them will have only fixed-width columns 1000 bytes per row + overhead. So it gives us an ability to put
- UniqueCI – that table has unique clustered index on KeyValue column
- NonUniqueCINoDups – that table has non unique clustered index on KeyValue column. Although we don’t put any KeyValue duplicates to that table
- NonUniqueCIDups – that table has non unique clustered index on KeyValue column and will have a lot of duplicates.

Now let’s add some data to those tables.

First, let’s take a look at the physical stats on the clustered index. Two things are interesting. First – Min/Max/Avg record size, and second is the Page Count.
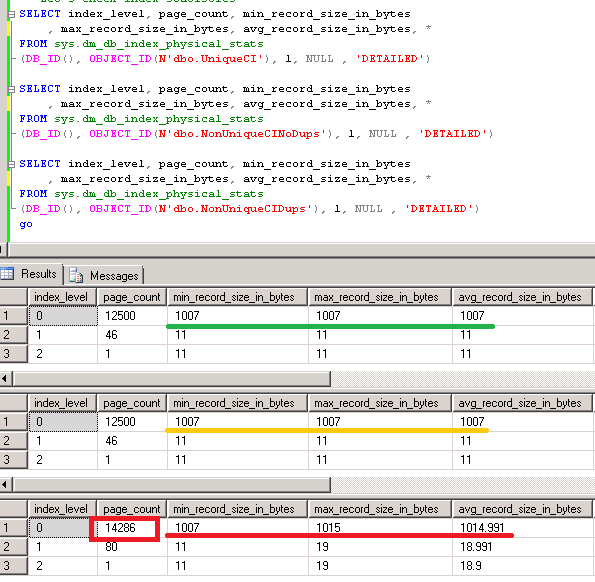
As you can see, best case scenario in UniqueCI table has 1007 bytes as Min/Max/Avg record size (again – all columns are fixed width) and uses 12500 pages. Each page can store 4 rows (1,007 bytes per row * 8 = 8,056 bytes < 8,060 bytes available on the page.
Next, let’s take a look at NonUniqueCINoDups table. Even if clustered index is not unique, Min/Max/Avg/Page Count are the same with UniqueCI clustered index. So as you can see, in this particular case of non-unique clustered index, SQL Server keeps null value for uniquifier for the first (unique) value of the clustered index. And we will look at it in more details later.
The last one – NonUniqueDups table, is more interesting. As you can see, if Min record size is the same (1,007 bytes), Maximum is 1,015 bytes. And Average record size is 1,014.991 – very similar to the maximum record size. Basically, uniquifier value added to all rows with exception of the first row per unique value. Interestingly enough that even if uniquifier itself is 4 bytes the total overhead is 8 bytes.
Another thing is worth to mention is the page count. As you can see, there are 1,786 extra pages (about extra 14M of the storage space). 8 rows don’t fit on the page anymore. Obviously this example does not represent real-life scenario (no variable with columns that can go off-row, etc) although if you think about non-clustered indexes, the situation is very close to the real-life. Let’s create non-clustered indexes and checks the stats.

As you can see, in the latter case, we almost doubled the size of the non-clustered index leaf row and storage space for the index. That makes non-clustered index much less efficient.
Now let’s take a look at the actual row data to see how SQL Server stores uniquifier. We will need to take a look at the actual data on the page. So the first step is to find out what is the page number. We can use DBCC IND command below. Let’s find the first page on the leaf level (the one that stores very first row from the table). Looking at DBCC IND result set, we need to select PagePID for the IndexLevel = 0 and PrevPageFID = 0.

Next, we need to run DBCC PAGE command and provide that PagePID. Both DBCC IND and DBCC PAGE are perfectly save to run on the production system. One other thing you need to do is to enable trace flag 3604 to allow DBCC PAGE to display result in the console rather than put it to SQL Server error log.
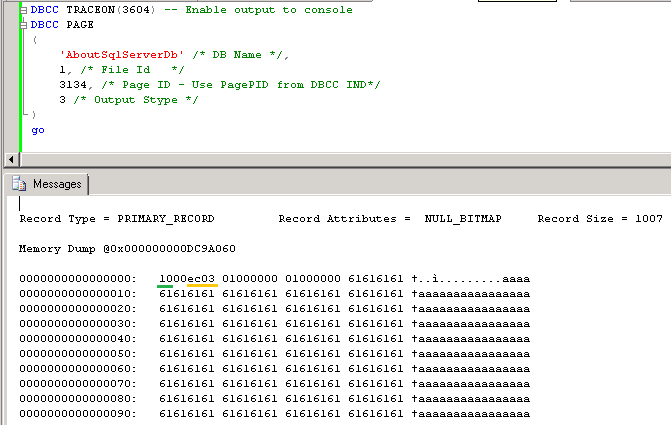
So let’s take a look at the row itself. First, we need to remember that DBCC PAGE presents multi-byte values with least-significant bytes first (for example int (4 bytes) value 0x00000001 would be presented as 0x01000000). Let’s take a look at the actual bytes.
- Byte 0 (TagByteA) (green underline) – this is the bit mask and in our case 0x10 means that there is NULL bitmap
- Byte 1 (TagByteB) – not important in our case
- Byte 2 and 3 (yellow underline) – Fixed width data size
- Bytes 4+ stores the actual fixed width data. You can see values 0x01 (0x10000000 in reverse order) for KeyValue and ID and ‘a..’ for the CharData columns.
But much more interesting is what we have after Fixed-Width data block. Let’s take a look:
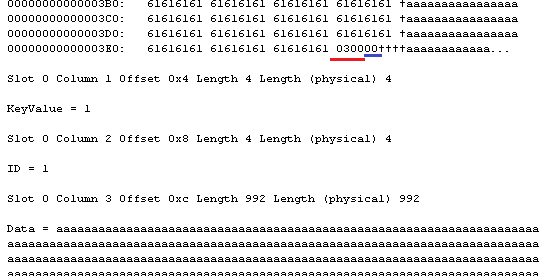
Here we have:
- Number of columns – 2 bytes (Red underline): 0x0300 in reverse order – 3 columns that we have in the table.
- Null bitmap (Blue underline): 1 byte in our case – no nullable columns – 0.
So everything is simple and straightforward. Now let’s take a look at NonUniqueCINoDups data. Again, first we need to find the page id with DBCC IND and next – call DBCC PAGE.

I’m omitting first part of the row – it would be exactly the same with UniqueCI row. Let’s take a look at the data after fixed-width block.
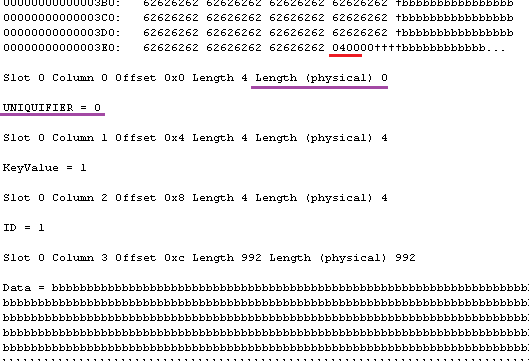
As you can see, number of columns (Red underline) is now 4 that includes uniquifier which does not take any physical space. And if you thinking about it for a minute – yes, uniquifier is nullable int column that stores in the variable-width section of the row. SQL Server omits data for nullable variable width columns that are the last in the variable-width section which is the case here. If we had any other variable width columns with the data, uniquifier would use two bytes in the offset array even if value itself would be null.
And now let’s take a look at NonUniqueCIDups rows. Again, DBCC IND, DBCC PAGE.

If we look at the variable width section of the first row in the duplication sequence), it would be exactly the same with NonUniqueCINoDups. E.g. uniquefier does not take any space.

But let’s look at the second row.

Again we have:
- Number of columns – 2 bytes (Red underline): 4
- Null bitmap (Blue underline)
- Number of variable-width columns – 2 bytes (Green underline) – 0x0100 in reverse order – 1 variable width column
- Offset of variable-width column 1 – 2 bytes (Black underline)
- Uniquefier value – 4 bytes (purple underline)
As you can see, it introduces 8 bytes overhead total.
To summarize storage-wise – if clustered index is not unique then for unique values of the clustered key:
- There is no overhead if row don’t have variable-width columns or all variable-width columns are null
- There are 2 bytes overhead (variable-offset array) if there is at least 1 variable-width column that stores not null value
For non-unique values of the clustered key:
- There are 8 extra bytes if row does not have variable-width columns
- There are 6 extra bytes if row has variable-width columns
This applies not only to the clustered indexes but also to non-clustered index that references clustered index key values. Well, storage is cheap but IO is not..
Source code is available for download
P.S. Happy Thanksgiving! 🙂
Pingback: Auto-incrementing surrogate Key vs. compound keys for a clustered index on a fact table - instadba