Unfortunately, disasters happen. Regardless of how good is High Availability strategy that you have implemented, there is always the chance that one day you will need to move the database to another server and quickly bring system online. And the chance is – you will have to do it under stress with your phone ringing every few minutes and your manager asking about ETA. It does not help that such process can be very time consuming in the case of the large databases.
Enterprise Edition of SQL Server supports concept of piecemeal restore and allows you to restore database on filegroup-by-filegroup basis keeping database online during the process. Queries that access data from online filegroups would work just fine. This is the great technique that can dramatically reduce system downtime.
In the large number of cases, the size of the operational data that is required for system to be operational is relatively small. Historical data, on the other hand, is often kept due to regulation/compliance reasons and rarely accessed by the applications. As you can guess, it allows you to quickly bring part of the database that supports operational activity online and work with remaining historical data afterwards while customers can connect and use the system.
Obviously, you should design data placement in the way that supports piecemeal restore. In the nutshell, it means the separation of the operational and historical data across different filegroups. As the example, let’s consider Order Entry/Shopping Cart system that stores data for several years. One of the data layout designs could be the following:
- Empty Primary FG. Primary Filegroup should be online in order for database to be online. It is good idea to keep primary filegroup empty and do not place any objects there.
- Entities FG. This filegroup could store catalog tables, such as Customers, Articles and others.
- One or more filegroups for the operational data. For example, if operational period is the current year, this filegroup can store Orders, OrderLineItems and related entities that stores current-year data.
- One or more filegroups for the historical data. Those filegroups store data that is not required to support operational activity in the system.
Piecemeal restore strategy will require you to bring online Primary, Entities and Operation data filegroups first. System will be available to the customers at this point. After that, you can work on restoring historical data filegroups, which in most part of the cases, will be significantly larger than operational data and, therefore, will take longer time to restore.
It is also worth noting, that in case of SQL Server 2014 In-memory OLTP, you should also have Hekaton filegroup online before database becomes available to the users. Usually, In-memory tables keep operational data anyway, so it should not be a problem in most part of the cases.
Let’s look at the example and create a database with the structure outlined above. For simplicity sake, every filegroup has only one data file. However, in the real-life you should consider creating multiple files to reduce allocation contention in the filegroups with volatile data.
create database [MyBigOrderDb] on primary (name = N'MyBigOrderDb', filename = N'c:\db\MyBigOrderDb.mdf'), filegroup [Entities] (name = N'MyBigOrderDB_Entities', filename = N'c:\db\MyBigOrderDB_Entities.ndf'), filegroup [FG2013] (name = N'MyBigOrderDB_FG2013', filename = N'c:\db\MyBigOrderDB_FG2013.ndf'), filegroup [FG2014] (name = N'MyBigOrderDB_FG2014', filename = N'c:\db\MyBigOrderDB_FG2014.ndf') log on (name = N'MyBigOrderDb_log', filename = N'c:\db\MyBigOrderDb_log.ldf')
As the next step, let’s create a few tables including partitioned table Orders.
create table dbo.Customers
(
CustomerId int not null,
CustomerName nvarchar(64) not null,
)
on [Entities];
create table dbo.Articless
(
ArticlesId int not null,
ArticleName nvarchar(64) not null,
)
on [Entities];
create partition function pfOrders(smalldatetime)
as range right
for values('2014-01-01');
create partition scheme psOrders
as partition pfOrders
to (FG2013,FG2014)
go
create table dbo.Orders
(
OrderId int not null,
OrderDate smalldatetime not null,
OrderNum varchar(32) not null,
constraint PK_Orders
primary key clustered(OrderDate, OrderId)
on psOrders(OrderDate)
)
go
insert into dbo.Customers(CustomerId, CustomerName) values(1,'Customer 1');
insert into dbo.Orders(OrderDate, OrderId, OrderNum)
values
('2013-01-01',1,'Order 1'),
('2013-02-02',2,'Order 2'),
('2014-01-01',3,'Order 3'),
('2014-02-02',4,'Order 4')
Next, let’s create the backup chain and perform FULL, DIFFIRENTIAL and LOG backups.
-- Full backup
backup database [MyBigOrderDb]
to disk = N'c:\db\MyBigOrderDb_Full.bak'
with noformat, init, name = N'MyBigOrderDb-Full Database Backup',
compression, stats = 2
go
-- Differential backup
backup database [MyBigOrderDb]
to disk = N'c:\db\MyBigOrderDb_Diff.bak'
with differential, noformat, init,
name = N'MyBigOrderDb-Differential Database Backup',
compression, stats = 2
go
-- Transaction log
backup log [MyBigOrderDb]
to disk = N'c:\db\MyBigOrderDb_Log.trn'
with noformat, init, name = N'MyBigOrderDb-Tran Log',
compression, stats = 2
go
And at this point, let’s assume that disaster happens and we need to move database to another server. In this example, I would assume that we still have access to transaction log of the original database and we will perform tail-log backup to avoid any data loss.
backup log [MyBigOrderDb] to disk = N'c:\db\MyBigOrderDb_TailLog.trn' with no_truncate, noformat, init, name = N'MyBigOrderDb-Tail Log', compression, norecovery, stats = 2
At this point, we will need to copy all files from the backup chain to another server and start restore process. We will perform piecemeal restore of Primary, Entities and FG2014 filegroups to support operational activity of the system without bringing historical FG2013 data online. The first operation is performing restore of the FULL database backup specifying just the filegroups we need to restore.
-- Restoring on another server (Same folder structure for demo sake) -- Full Backup restore database [MyBigOrderDb] FILEGROUP = 'primary', FILEGROUP = 'Entities', FILEGROUP = 'FG2014' from disk = N'C:\DB\MyBigOrderDb_Full.bak' with file = 1, move N'MyBigOrderDB' to N'c:\db\MyBigOrderDb.mdf', move N'MyBigOrderDB_Entities' to N'c:\db\MyBigOrderDb_Entities.ndf', move N'MyBigOrderDB_FG2014' to N'c:\db\MyBigOrderDb_2014.ndf', move N'MyBigOrderDb_log' to N'c:\db\MyBigOrderDb.ldf', NORECOVERY, partial, stats = 2;
it is worth mentioning, that I am using WITH NORECOVERY clause in all RESTORE commands including tail-log backup restore. In the end, I am recovering database with the separate RESTORE statement. This is just a good practice and safety measurement. By default, Management Studio uses WITH RECOVERY option with restore, which can lead to the situation that you accidentally recovered database at intermediate restore stage. You would not be able to restore further backups after that and would be forced to start from scratch.
As the next steps, we need to restore DIFFERENTIAL, LOG and tail-log backups as shown below. You do not need to specify filegroups as part of restore statement anymore – SQL Server would perform restore only in scope of the filegroups we are working with and which are in RESTORING state.
-- Diff Backup restore database [MyBigOrderDb] from disk = N'C:\DB\MyBigOrderDb_Diff.bak' with file = 1, NORECOVERY, stats = 2; -- Tran Log restore database [MyBigOrderDb] from disk = N'C:\DB\MyBigOrderDb_Log.trn' with file = 1, NORECOVERY, stats = 2; -- Tail-log restore database [MyBigOrderDb] from disk = N'C:\DB\MyBigOrderDb_TailLog.trn' with file = 1, NORECOVERY, stats = 2; -- Recovery restore database [MyBigOrderDb] with RECOVERY;
At this point, our database is partially online. We can query operational data as it shown below in Figure 1.
select * from MyBigOrderDb.dbo.Customers select * from MyBigOrderDb.dbo.Orders where OrderDate >= '2014-01-01'
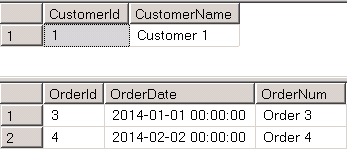
01. Querying Data from Operational Filegroups
However, if we try to query historical data, we will get an error, as shown in Figure 2
select * from MyBigOrderDb.dbo.Orders where OrderDate < '2014-01-01'

02. Querying Data from Historical Filegroup
You can check the status of the database filegroups with the following query. Figure 3 shows that three filegroups are online while FG2013 filegroup is still in RECOVERY_PENDING stage.
select file_id, name, state_desc, physical_name from MyBigOrderDb.sys.database_files
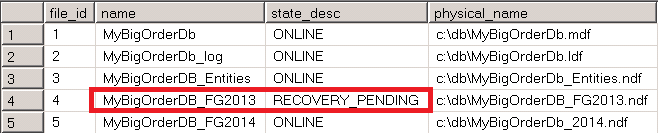
03. Filegroup Status Before Historical Filegroup Restore
As you see, customers can use the system while we are working on restoring of FG2013 filegroup. We can perform this with the following script:
-- Full Backup (restoring individual filegroup) restore database [MyBigOrderDb] FILEGROUP = 'FG2013' from disk = N'C:\DB\MyBigOrderDb_Full.bak' with file = 1, move N'MyBigOrderDB_FG2013' to N'c:\db\MyBigOrderDb_2013.ndf', stats = 2; -- Diff Backup restore database [MyBigOrderDb] from disk = N'C:\DB\MyBigOrderDb_Diff.bak' with file = 1, stats = 2; -- Tran Log restore database [MyBigOrderDb] from disk = N'C:\DB\MyBigOrderDb_Log.trn' with file = 1, stats = 2; -- Tail-log restore database [MyBigOrderDb] from disk = N'C:\DB\MyBigOrderDb_TailLog.trn' with file = 1, stats = 2;
Now database is online as it is shown in Figure 4.
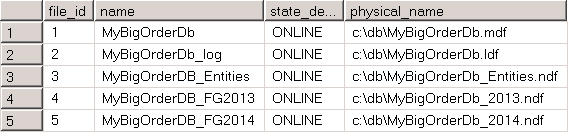
04. Filegroups Status After Historical Filegroup Restore
Piecemeal restore can significantly decrease database restore time. However, there is still time-consuming part in this process. Regardless how many filegroups you are restoring, you should copy/move backup file that contains initial FULL database backup to the new server. Time of this operation depends on network throughput and slow network and/or large backup files can lead to very long delays.
Obviously, you can take several approaches. You can always “be prepared” and copy files to reserved server after each backup. With such strategy, you would already have backup files in place when they need to be restored if/when disaster occurs.
However, you can use another approach if historical data is read-only. This approach is called “partial database backup”. Even though, Microsoft stated that it is designed for SIMPLE recovery models, it would work just fine with FULL recovery model, as long as you implemented it correctly.
Let’s look how it works and as the first step, let’s mark our FG2013 filegroup as read-only:
alter database MyBigOrderDb modify filegroup FG2013 readonly
At this point, you should start the new backup chain, which, in the nutshell, are two different sets of backup files. One set includes backup files for read-write filegroups (FULL, DIFFERENTIAL and LOG backups using READ_WRITE_FILEGROUPS option. In addition, you need to perform backup of read-only filegroup. You can do it with the script shown below:
-- Backing Up Read-Only Filegroup backup database [MyBigOrderDb] FILEGROUP = N'FG2013' to disk = N'c:\db\MyBigOrderFG2013.bak' with noformat, init, name = N'MyBigOrderDb-FG2013 FG backup', compression, stats = 2 go -- Full backup of read_write filegroups backup database [MyBigOrderDb] READ_WRITE_FILEGROUPS to disk = N'c:\db\MyBigOrderDbRW_Full.bak' with noformat, init, name = N'MyBigOrderDb-Full Database Backup (R/W FG)', compression, stats = 2 go -- Differential backup backup database [MyBigOrderDb] to disk = N'c:\db\MyBigOrderDbRW_Diff.bak' with differential, noformat, init, name = N'MyBigOrderDb-Differential Database Backup (R/W FG)', compression, stats = 2 go -- Transaction log backup log [MyBigOrderDb] to disk = N'c:\db\MyBigOrderDbRW_Log.trn' with noformat, init, name = N'MyBigOrderDb-Tran Log', compression, stats = 2
The beauty of this situation that now you have data backups separated. You would have relatively small backup chain file(s) for operational data as well as large static backup file for read-only historical data. This will dramatically reduce time required to move operational data backup files over network. It also helps with day-to-day backup strategy and reduces the time of backup operation and, server and network load, and storage space required to store the files. You can create new backup chains of operation data without taking new backup for historical data as long as those filegroups stay read-only.
If disaster occurs and you need to move database to another server, you can start with operation data backup chain as shown below. For simplicity sake, I am omitting tail-log backup – however, in real life you should always obtain it to avoid data loss.
-- Restoring on another server (Same folder structure for demo sake) -- Full Backup (R/W filegroups only) restore database [MyBigOrderDb] filegroup = 'primary', filegroup = 'Entities', filegroup = 'FG2014' from disk = N'C:\DB\MyBigOrderDbRW_Full.bak' with file = 1, move N'MyBigOrderDB' to N'c:\db\MyBigOrderDb.mdf', move N'MyBigOrderDB_Entities' to N'c:\db\MyBigOrderDb_Entities.ndf', move N'MyBigOrderDB_FG2014' to N'c:\db\MyBigOrderDb_2014.ndf', move N'MyBigOrderDb_log' to N'c:\db\MyBigOrderDb.ldf', norecovery, partial, stats = 2; -- Diff Backup restore database [MyBigOrderDb] from disk = N'C:\DB\MyBigOrderDbRW_Diff.bak' with file = 1, norecovery, stats = 2; -- Tran Log restore database [MyBigOrderDb] from disk = N'C:\DB\MyBigOrderDbRW_Log.trn' with file = 1, norecovery, stats = 2; -- Recovery restore database [MyBigOrderDb] with recovery;
If you queried the status of the database filegroups after restore, you would see very similar picture – all operational filegroups are online and historical filegroup is in RECOVERY_PENDING state. Figure 5 illustrates that.
05. Filegroup Status During Partial Restore
Again, at this point system is available to users and you can continue working on historical data while system is operational with the following script.
-- Restoring Read/Only Filegroup restore database [MyBigOrderDb] filegroup = 'FG2013' from disk = N'C:\DB\MyBigOrderFG2013.bak' with file = 1, move N'MyBigOrderDB_FG2013' to N'c:\db\MyBigOrderDb_2013.ndf', recovery, stats = 2;
Be careful when you change read-only status of the filegroups when partial backup is used. One of examples of such scenario is when operational period changed and you need to move some former-operational data that becomes historical to another filegroup. One of the approaches to accomplish it is making historical filegroup as read-write, copying data there and making it read-only again. You can still restore the database using old read-only filegroup backup as long as you have backup chain with LOG backups that cover data movement operations. However, you would not be able to recover historical data if you start new backup chain for updateable filegroups after the fact and did not take new backup of the read-only filegroup.
As the general recommendation, it is safer to start new backup chain together with backup of historical filegroup after you made historical filegroup read-only again. And, most importantly, regardless what solution you are using, test your backup and restore strategies. This would help you to avoid unpleasant surprises when things went south.
Pingback: (SFTW) SQL Server Links 03/07/14 - John Sansom
Very helpfull step by step demonstration of the Partial Database Backup (Piecemeal)
Thanks
Thank you!
Does this apply to SQL2016, SQL2014 or both. No mention in the article. Please let me know.
Hi Tony,
You can utilize partial DB availability in all versions of SQL Server. You need Enterprise Edition though.
Dmitri
Hi, I noticed that the full backup of Read_Write filegroups only is the same size on disk as a regular full backup. Shouldn’t this be smaller if the Read_Only filegroup is being backup separately? or does a backup of Read_Write file groups also include the Read_Only group?
Hi Adrian,
READ_ONLY filegroups should be excluded. Email me if it is still a problem – we can troubleshoot it offline.
Sincerely,
Dmitri