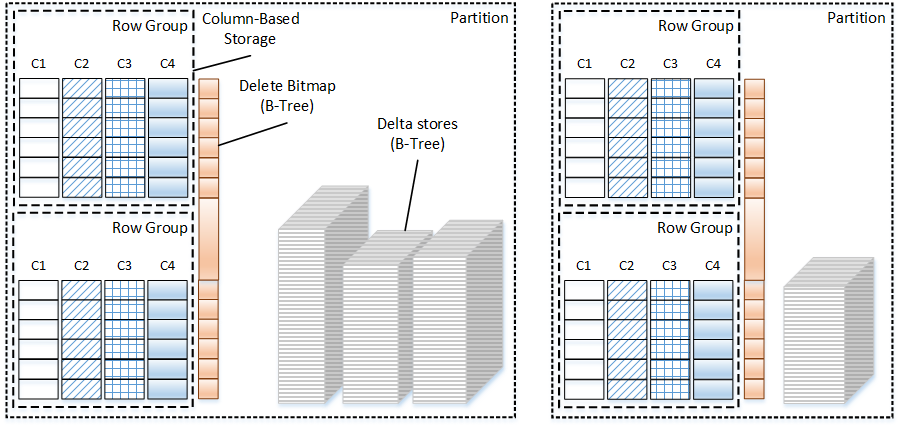
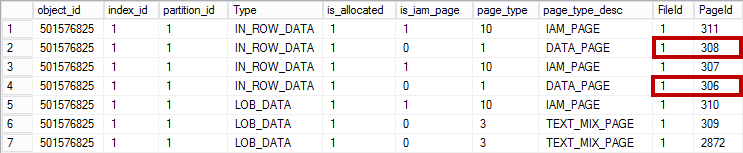
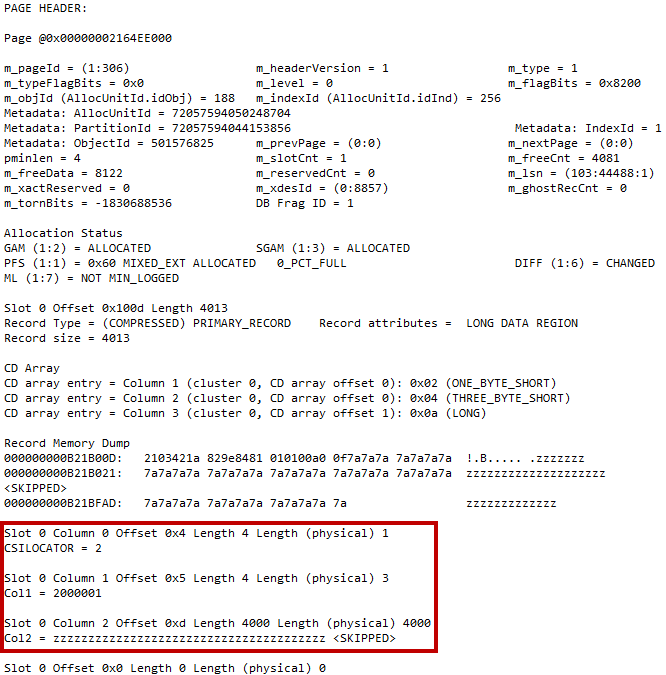
Last time we have looked at the internal structure of delta store and delete bitmap in the clustered columnstore indexes. Today, I would like us to discuss a few practical aspects affecting performance of ETL processes and queries against tables with clustered columnstore indexes.
There are two different ways how you can import data into a table with clustered columnstore index. The first approach is bulk insert, which can be done with bcp utility, BULK INSERT command and other applications that utilize the bulk insert API. The second type, called trickle inserts, are regular INSERT operations that do not use the bulk insert API.
Bulk insert operations provide the number of rows in the batch as part of the API call. SQL Server inserts data into newly created row groups if that size exceeds a threshold of a little bit over 100,000 rows. Depending on the size of the batch, one or more row groups can be created and some rows may be stored in delta store.
Figure 1 below illustrates how data from the different batches are distributed between row groups and delta stores based on batch size.

01. Batch size and data distribution during bulk insert
Let’s do some tests now and see how performance is affected based on the batch size and, therefore, number of row groups in the table. In those tests, I created a set of the tables with the structure similar to what is shown below.
create table dbo.FactSalesBig
(
ProductKey int not null,
OrderDateKey int not null,
DueDateKey int not null,
ShipDateKey int not null,
CustomerKey int not null,
PromotionKey int not null,
CurrencyKey int not null,
SalesTerritoryKey int not null,
SalesOrderNumber nvarchar(20) not null,
SalesOrderLineNumber tinyint not null,
RevisionNumber tinyint not null,
OrderQuantity smallint not null,
UnitPrice money not null,
ExtendedAmount money not null,
UnitPriceDiscountPct float not null,
DiscountAmount float not null,
ProductStandardCost money not null,
TotalProductCost money not null,
SalesAmount money not null,
TaxAmt money not null,
Freight money not null,
CarrierTrackingNumber nvarchar(25) null,
CustomerPONumber nvarchar(25) null,
OrderDate datetime null,
DueDate datetime null,
ShipDate datetime null
)
As the first step, I created CSV file with about 62M rows generated based on dbo.FactResellerSales table from the AdventureWorksDW2012 database and measured performance of the bulk import with bcp utility using 1,000,000-row batches and 102,500-row batches respectively in the 4-CPU virtual machine with 8GB of RAM allocated.
You can see row group statistics after the imports in Figure 2 below. The first import generated 62 1,000,000-row row groups while the second imported ended up with 604 102,500-row row groups.
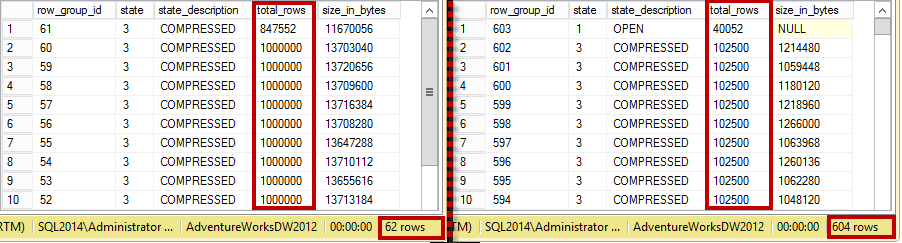
02. Row groups after insert
Performance of import operation was affected by the batch size. Bcp utility were able to process about 103,500 rows per second with 1,000,000-row batches. In case of 102,500-row batches, the throughput was about 94,300 rows per second, which is about 9% slower.
It is also worth noting that in case of the smaller batches, SQL Server imports data into the delta stores converting them to fully-populated row groups later. While, on the one hand, it would generate efficient row groups, it significantly degraded performance of insert process. For example, in case of 99,999-row batches, the throughput in my environment was only 37,500 rows per second.
As the next test, I checked how partially populated row groups affected performance of the queries using the query shown below. That query performs a MAX() aggregation on 20 columns from a table. The result of the query is meaningless; however, it forces SQL Server to read data from 20 different column segments in each row group in the table.
select
max(ProductKey),max(OrderDateKey),max(DueDateKey)
,max(ShipDateKey),max(CustomerKey),max(PromotionKey)
,max(CurrencyKey),max(SalesTerritoryKey),max(SalesOrderLineNumber)
,max(RevisionNumber),max(OrderQuantity),max(UnitPrice)
,max(ExtendedAmount),max(UnitPriceDiscountPct),max(DiscountAmount)
,max(ProductStandardCost),max(TotalProductCost),max(SalesAmount)
,max(TaxAmt),max(Freight)
from dbo.FactSalesBig
Figure 3 illustrates execution statistics of the query against tables with fully and partially populated row groups (shown in Figure 2). As you can see, the query against a table with partially populated row groups took a considerably longer time to execute.

03. Execution Statistics in case of fully and partially populated row groups
In the next step, let’s check how large delta store affects performance of the queries. For that test, I inserted one million rows to the table using small batches and run the test query. After that, I rebuilt the columnstore index, comparing the execution time of the test query before and after the index rebuild.
The index rebuild process moved all data from the delta store to row groups. You can see the status of row groups and the delta store before (on the left side) and after (on the right side) the index rebuild in Figure 4.
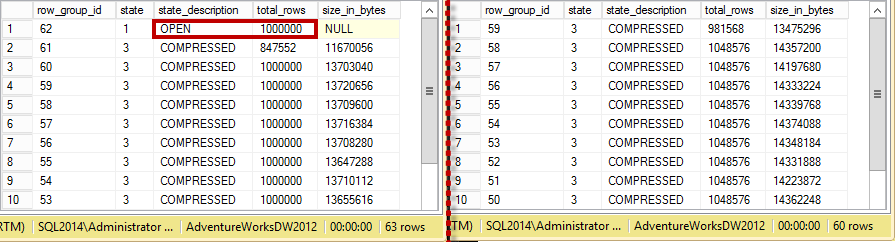
04. Row groups and delta store after insertion of 1,000,000 rows
Figure 5 illustrates the execution times of the test query in both scenarios, and it shows the overhead introduced by the large delta store scan during query execution.

05. Execution time and delta store size
Finally, let’s see how delete bitmaps affect query performance. For that test, I deleted almost 30,000,000 rows from a table (the one where I just rebuilt the index). You can see row groups’ information in Figure 6.
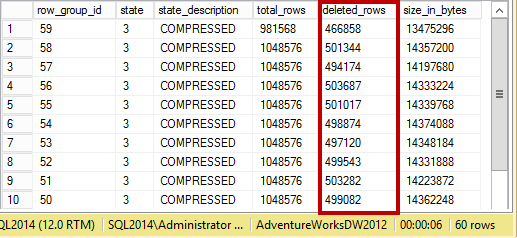
06.Row groups after deletion of 30,000,000 rows
The test query needs to validate that rows have not been deleted during query execution. Similar to the previous test, this adds considerable overhead. Figure 7 shows the execution time of the test query, comparing it to the execution time of the query before the data deletion.

07. Execution time and delete bitmap
The bottom line – partially populated row groups, and large delta stores and delete bitmaps, they all negatively affect performance of the systems that use clustered columnstore indexes. You can address all of these performance issues by rebuilding the columnstore index, which you can trigger with the ALTER INDEX REBUILD command. The index rebuild forces SQL Server to remove deleted rows physically from the index and to merge the delta stores’ and row groups’ data. All column segments are recreated with row groups fully populated.
Similar to index creation, the index rebuild process is very resource intensive. Moreover, it prevents any data modifications in the table by holding shared (S) table lock. However, other sessions can still read data from a table while the rebuild is running.
One of the methods you can use to mitigate the overhead of index rebuild is table/index partitioning. You can rebuild indexes on a partition-basis and only perform it for partitions that have volatile data. Old facts table data in most Data Warehouse solutions is relatively static, and ETL processes usually load new data only. Partitioning by date in this scenario localizes modifications within the scope of one or very few partitions. This can help you dramatically reduce the overhead of an index rebuild.
A columnstore indexes maintenance strategy should depend on the volatility of the data and the ETL processes implemented in the system. You should rebuild indexes when a table has a considerable amount of deleted rows and/or a large number of partially populated row groups.
To summarize:
- You should design ETL processes in the way that data is bulk imported in the batches as close to 1,048,576 rows as possible. This will guarantee that every batch will become separate and fully populated row-group. Do not exceed this size and avoid spilling batches across multiple row groups
- Even though clustered columnstore indexes are updateable, you should minimize such updates. Large delta stores and/or delete bitmaps negatively affect query performance. You should monitor their sizes and design index maintenance strategy in the way that keep them as small as possible
- Columnstore index rebuild is very resource-intensive. Table partitioning would help you to mitigate performance impact by allowing index rebuild in the scope of the one or very few partitions. You should design partitioning strategy in the way, that limits data modification and/or import into small subset of partitions rebuilding them afterwards