Sometimes you need to do the query based on equality predicate on large text column. It does not happen quite often but it happens.Unfortunately sometimes it’s impossible to create the index on such column. First, the size of the column could be greater than 900 bytes (so index would not be created). Another possibility – you have a lot of data and simply don’t want to use a lot of space for such index.
How to optimize the query in such case? Let’s take a look at the example. First, let’s create the table and add some data there. As you can see, LargeField would have a size of 1080 bytes.

Now let’s try to run the select with the clustered index scan. 9150 reads – quite bad.



Index cannot be created – 900 bytes is the limitation.

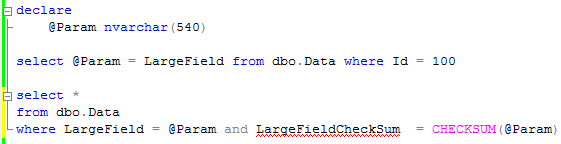
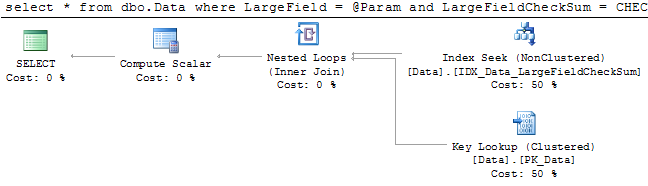
The solution is persisted calculated column with CHECKSUM() function that generates hash of the string. Let’s take a look:

![]()
There are 2 things we need to keep in mind. First – hash is not guaranteed to be unique. So statement still needs to include the predicate on the field. Second, unicode and regular strings obviously return different hash. It should not be generally a problem although make sure that client application specify correct parameter data type.
Source code is available for download
This is still not working, when we had large volume. We have created index as well as rebuild the clustered index but still execution time is very high. All the conditions are same as prescribed above.
Please reply as soon as possible.
Worked with Shree offline. In his case, calculated checksum column used ISNULL function, which forced Query Optimizer to recalculate column rather than use persisted value. This is one of QO limitations.