Let’s think about the system that collects and processes the data. Quite often processing happens after data have been inserted into the system. Typically the rows have set of the columns inserted as NULL. Processing routine loads the rows, update those columns and save rows back.
Looks simple but this pattern introduces major page split/fragmentation issues. Think about that – SQL Server tried to fill pages up to 100%. So when you update the rows, pages don’t have enough free space to keep the data. Let’s look at the example:
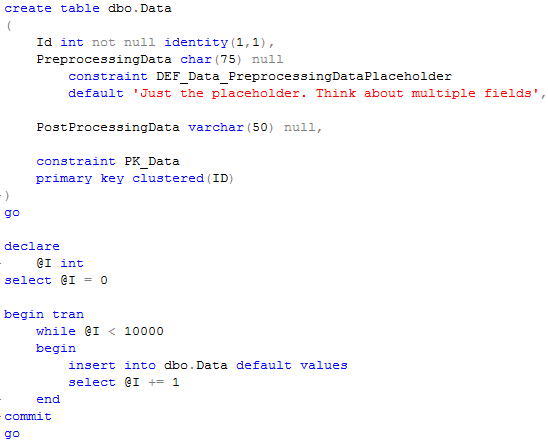
First – let’s create the table. There are only 3 columns in this table – identity, char column as the placeholder for the columns populated during insert stage and post processing placeholder.
Second, let’s check the physical index statistics. Index is practically perfect.

Now let’s execute update and populate post processing placeholder column. Now check the statistics – terrible fragmentation and a lot of space wasted.

Obviously the workaround is simple – reserve the space for the post processing columns on the insert stage.
Source code is available here