The only correct way of writing triggers is not writing them. I would repeat – the only correct way of writing triggers is not writing them. Triggers negatively affect performance. AFTER triggers introduce fragmentation and increase tempdb load due to version store usage. Triggers are running in context of transaction, increase the time in which locks are held and contribute to locking and blocking in the system. However, in some cases, we have to use triggers and it is important to develop them correctly.
SQL Server fires triggers on statement rather than row level. For example, if update statement modified 10 rows, AFTER UPDATE and/or INSTEAD OF UPDATE trigger would fire once rather than 10 times. Therefore, trigger must handle situations when inserted and/or deleted tables have multiple rows. Let’s look at the example and create a table with AFTER INSERT trigger as shown below:
create table dbo.Data ( ID int not null, Value varchar(32) ) go create trigger trgData_AI on dbo.Data after insert as /* Some code */ declare @ID int set @ID = (select ID from inserted) /* Some code */
Everything is fine when you inserted a single row. However, multi-row insert would fail with exception shown below.
Msg 512, Level 16, State 1, Procedure trgData_AI, Line 9 Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression. The statement has been terminated.
And there is another consequence of statement-level nature of triggers. They fire even if DML statement did not modify any rows. Would it introduce any issues in the system or not depends on implementation. However, it would always lead to unnecessary performance overhead.
Let’s look at example. The code below creates another table and changes trigger in a way, that mimics behavior of audit functional, which is frequently implemented based on triggers.
create table dbo.Audit ( ID int not null identity(1,1), OnDate datetime2(0) not null constraint DEF_Audit_OnDate default getutcdate(), Message varchar(64) not null, ) go alter trigger trgData_AI on dbo.Data after insert as begin declare @Msg varchar(64) = 'Triggers are bad. And @@ROWCOUNT=' + convert(varchar(10),@@rowcount) insert into dbo.Audit(Message) values(@Msg); end
Now let’s run insert statement, which does not insert any rows to the table.
insert into dbo.Data(ID, Value) select 1, 'ABC' where 1 = 0
If you checked content of Audit table, you would see that trigger was fired:
01. Content of Audit table
So the first important conclusion is that every trigger must checks @@ROWCOUNT variable as the very first statement in implementation.
SET NOCOUNT ON should be the second action trigger does. Without that SQL Server returns affected number of rows for each operator in the trigger in addition to original DML statement. Some client libraries rely on the single message in the output and would not work correctly in case of multiple messages. Therefore, the first two statements in the trigger should look like it is shown below.
alter trigger trgData_AI on dbo.Data after insert as begin if @@ROWCOUNT = 0 return set nocount on /* Some Code Here */ end
Finally, there is another caveat. While implementation above works for insert, update and delete operators, it is not the case with merge. @@ROWCOUNT in this case represents total number of rows affected by merge statement rather than by individual insert, update or delete action in the trigger. Let’s prove it with the example.
create table dbo.Data2(Col int not null) go create trigger trg_Data_AI on dbo.Data2 after insert as select 'After Insert' as [Trigger] ,@@RowCount as [RowCount] ,(select count(*) from inserted) as [Inserted Cnt] ,(select count(*) from deleted) as [Deleted Cnt] go create trigger trg_Data_AU on dbo.Data2 after update as select 'After Update' as [Trigger] ,@@RowCount as [RowCount] ,(select count(*) from inserted) as [Inserted Cnt] ,(select count(*) from deleted) as [Deleted Cnt] go create trigger trg_Data_AD on dbo.Data2 after delete as select 'After Delete' as [Trigger] ,@@RowCount as [RowCount] ,(select count(*) from inserted) as [Inserted Cnt] ,(select count(*) from deleted) as [Deleted Cnt] go
Now let’s run MERGE statement as shown below:
merge into dbo.Data2 as Target using (select 1 as [Value]) as Source on Target.Col = Source.Value when not matched by target then insert(Col) values(Source.Value) when not matched by source then delete when matched then update set Col = Source.Value;
The table is empty, therefore only one insert statement would be executed. However, as you should see below, all three triggers were fired, It is worth mentioning that previous code example demonstrated very bad practice of returning result sets from trigger. You should avoid doing it in production code.
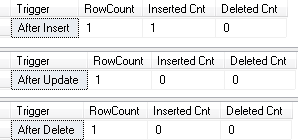
02. Triggers and MERGE statement
The right way to deal with such situation is checking content of inserted and deleted tables as shown below.
alter trigger trg_Data_AI on dbo.Data2 after insert as if @@rowcount = 0 return set nocount on if exists(select * from inserted) /* Some Code Here */ go alter trigger trg_Data_AU on dbo.Data2 after update as if @@rowcount = 0 return set nocount on if exists(select * from inserted) and exists(select * from deleted) /* Some Code Here */ go alter trigger trg_Data_AD on dbo.Data2 after delete as if @@rowcount = 0 return set nocount on if exists(select * from deleted) /* Some Code Here */
I hope that those tips will help you to write trigger in the most optimal way. However, I would repeat – the best way of writing triggers is not writing them at all.
Thanks for very interesting facts about triggers.
The article is interesting, and the code presented is fine. However, I have objections.
First, I never check @@rowcount in a trigger, because triggers might cause other triggers to fire ans so on. So, for triggers, it’s best to turn rowcounting of generally.
Second, I totally disagree with the statement that the correct way to write triggers is not to write them.
Of course, it is true that triggers create processing overhead. However, I would argue that this is the minimal overhead at all to get things done, for several reasons;
– Since triggers run as close as possible to the data, they can take advantage of all the optimizations implemented by the database vendor/open source community, and you can write triggers accordingly.
– If you need features such as auditing or logging, how do you achieve this without triggers? You can move the load into the applications, but please, don’t tell me that this reduces overhead.
– The main reason for me to use triggers is to maintain data integrity. If you don’t do it using triggers, you have to implement it otherwhere in application code, to be clear, for any application manipulating the data under consideration. But all the issues you mentioned remain.
– If you move the logic into application code, you open the door to a wide field of additional problems. Apart from the fact that the number of people dealing with these questions becomes larger and therefore more difficult to synchronize in order to achieve consistent results (if at all), the overhead is, without any doubt, larger. If this logic does not run on the same machine as the database sever, there will be more network traffic; generally, you’ll have more software layers and more complex logic, ORMs involved, and whatever. There are lots of opportunities to introduce mistakes.
That is why I firmly believe: The best protection you can achieve runs as close as possible to the data. Therefore, if you need to protect data integrity, implement the necessary logic using triggers.
Hi Goetz,
First of all, thank you very much for the comments! You definitely raised very valid points!
I think that discussion deserves another blog post. I will do it shortly.
Sincerely,
Dmitri
Nice article indeed and I also agree with Goetz. Database triggers are, in some cases, the “good enouth” solution especially for audit and logging.
For my part, I would like to focus on another interest of database triggers, they can capture changes on data. And the fact that a data has changed is also a data, another kind of data, few used but with great potential.
Imagine the gain if instead of querying a very large table to process the records changed from the day before, you query a table loaded by triggers containing just what has changed… we often use this approach in BI, Operational reporting and BAM.
Pingback: Writing Triggers in the Right Way | About Sql S...
Its really helped me to solved multi rows update/insert
If you’re talking about “write trigger in the most optimal way” then you shouldn’t use “exists(select * from deleted)”. For an ‘exists’, it is sufficient that there is one record and you don’t need to retrieve all columns, so for better performance use “exists (select top 1 1 from deleted)”.
Hi Patrick,
SQL Server optimizes exists operator internally. It would not retrieve any columns regardless of the syntax used. Execution plans would be the same in both cases.
With all being said, I would avoid using exists(select TOP 1 ) in my code. Even if it did not affect execution plan, I think it is stylistically incorrect.
Sincerely,
Dmitri
“stylistically incorrect” is not enough, it is totally incorrect to use the TOP clause for so may reasons:
The top reason: The developers don’t even detect whether there are severe bugs in their data concepts ( multiple rows selected and non deterministic results chosen) id they are free to cut the results.
If we talk about EXISTS operator, it does not really matter. EXISTS(SELECT *); EXISTS(SELECT 1); EXISTS(SELECT TOP 1) all would perform the same after optimization. SQL Server does not fetch more than 1 row from subquery to validate EXISTS join.
Speaking of TOP in general – well, I am not sure if I agree with you. It is the regular operator which works perfectly for its use-cases. I wonder if you can share some examples or, perhaps, clarify your point?
Thank you!
Dmitri
Good tips. one more: you need to check whether updated column actually changed, because other columns in row might and so rowcount won’t be 0. You do that like this:
IF (UPDATE (smallThumbWidth) and exists(select 1 from _AT3SettingsStore A join deleted B on B.storeId = A.storeId where B.smallThumbWidth A.smallThumbWidth))
So all triggers should look like this:
IF EXISTS (SELECT name FROM sysobjects WHERE name = ‘_AT3SettingsStoreTrigger’ AND type = ‘TR’)
DROP TRIGGER dbo._AT3SettingsStoreTrigger
GO
CREATE TRIGGER _AT3SettingsStoreTrigger
ON _AT3SettingsStore
AFTER INSERT, UPDATE, DELETE
AS
if @@ROWCOUNT = 0
return
set nocount on
IF (UPDATE (smallThumbWidth) and exists(select 1 from _AT3SettingsStore A join deleted B on B.storeId = A.storeId where B.smallThumbWidth A.smallThumbWidth))
or (UPDATE (smallThumbWidth) and exists(select 1 from _AT3SettingsStore A join deleted B on B.storeId = A.storeId where B.smallThumbWidth A.smallThumbWidth))
or (UPDATE (smallThumbHeight) and exists(select 1 from _AT3SettingsStore A join deleted B on B.storeId = A.storeId where B.smallThumbHeight A.smallThumbHeight))
or (UPDATE (smallerThumbWidth) and exists(select 1 from _AT3SettingsStore A join deleted B on B.storeId = A.storeId where B.smallerThumbWidth A.smallerThumbWidth))
or (UPDATE (smallerThumbHeight) and exists(select 1 from _AT3SettingsStore A join deleted B on B.storeId = A.storeId where B.smallerThumbHeight A.smallerThumbHeight))
or (UPDATE (thumbWidth) and exists(select 1 from _AT3SettingsStore A join deleted B on B.storeId = A.storeId where B.thumbWidth A.thumbWidth))
or (UPDATE (thumbHeight) and exists(select 1 from _AT3SettingsStore A join deleted B on B.storeId = A.storeId where B.thumbHeight A.thumbHeight))
or (UPDATE (bigThumbWidth) and exists(select 1 from _AT3SettingsStore A join deleted B on B.storeId = A.storeId where B.bigThumbWidth A.bigThumbWidth))
or (UPDATE (bigThumbHeight) and exists(select 1 from _AT3SettingsStore A join deleted B on B.storeId = A.storeId where B.bigThumbHeight A.bigThumbHeight))
begin
update _AT3SettingsDB set regenerateImages = 10
update _AT3Products set isPicGenerated = 0
update _AT3ProductImages set isPicGenerated = 0
update _AT3CategoriesAtena set isPicGenerated = 0
update _AT3CategoriesPantheon set isPicGenerated = 0
update _AT3PropValues set isPicGenerated = 0
end
go
Hi Tone,
You are right – it is useful if you have the logic that depends on updating of particular column. Here is the catch however – the problem with UPDATE function is that it does not indicate if column has been actually updated – it just shows the existence of the column in DML statement. Moreover, it becomes hard to handle when trigger fires in the scope of the multiple rows.
In most of the cases I use: exists (select * from inserted i join deleted d on i.Key = d.Key and i.Col != d.Col) – obviously NULLs require additional logic.
Sincerely,
Dmitri
Hey man, Thank you so much for the page. It really helped.
But you didn’t give solution for the case more than 1 row is affected for “after update” trigger.
Amir,
It just depends on what you are trying to accomplish. My point was – treat inserted/deleted tables as they may have multiple (or zero) rows. And write your code in the way that handles it.
If you need row-by-row processing – use cursor (yuck) or patterns like: SELECT TOP 1 @ID = ID from inserted WHERE ID > @ID ORDER BY ID in the loop. But better – implement SET-based logic for inserted/deleted data
Dmitri
If one wants to check if of all the columns in any of them the value has really changed, then one could – instead of using UPDATE(…) and then checking for a real change in WHERE – use EXCEPT with all the columns one’s interested in. For a moderate number of rows affected it’s certainly a viable and rather fast solution and does not require you to do tedious checks. Moreover, it does not require you to handle NULLs in any special way. All the drudgery’s done by the EXCEPT operator. So, to find out rows that really have had a real change applied to them you’d do: select from Inserted as I EXCEPT select from Deleted as D. You could put this statement in a CTE to modularize code (which is always good). In the you should have some unique identifier (for instance, a primary key or a unique constraint) to be able to then, for instance, join to the original table and do something with it.
Hi Darek,
Yes, your method would work. However, it serves a little bit different purpose. My main usage for UPDATE() is checking if column is present in the statement. For example, I may have some logic in the trigger that needs to be executed only when specific column(s) changed. I would like to avoid any logic and its overhead if columns were not present in the statement..
EXCEPT is very easy way to validate if something have been changed in multiple columns. Just remember the overhead of this operation on large unindexed batches. In many cases it may be cheaper to use joins between INSERTED and DELETED tables comparing column values (yes, you are right – it is trickier with NULLs). For small or 1-row batches, EXCEPT is fine.
Sincerely,
Dmitri
Great article. I think all these problems starts popping up when we use triggers for writing business logic along with the code to check integrity.
Thank you, Mitesh!