It is impossible to resist the urge of exploring in-memory OLTP Engine (code name Hekaton) released as part of SQL Server 2014. This technology can provide you huge performance boost, assuming, of course, that you can live within surface area limitations. Nevertheless, internal implementation of in-memory OLTP is fascinating. Almost everything is done differently than what you get used to with SQL Server Storage Engine. To put things into prospective, I seriously considered to name this post as “Concurrency – upside down”. 🙂
Today, I want to focus on particular aspect of in-memory OLTP, such as its concurrency model. While implementation of SNAPSHOT isolation is more or less obvious, I was intrigued, how higher isolation levels, such as REPEATABLE READ and SERIALIZABLE, would work in latch- and lock-free environment.
I assume, that you have a basic understanding of key principles used in-memory OLTP. Otherwise, you can consider to read MSDN documentation and Kalen Delaney’ whitepaper at first.
Even though, I am not going to focus much on in-memory OLTP indexes and access methods, I would like to reiterate how Hekaton works with the data. It uses completely different mechanism comparing to regular on-disk tables. The data rows live in memory and linked to each other in single-linked list of pointers – one pointer chain per index.
Concurrency model in in-memory OLTP is a version-based supporting multiple versions of the rows with different lifetime. SQL Server maintains two different unique values, such as:
- Global Transaction Timestamp is auto-incremented value, which is uniquely identifying every transaction in the system. SQL Server increments this value at transaction pre-commit stage.
- TransactionId is another identifier (timestamp), which is also uniquely identifies a transaction. SQL Server obtains and increments its value at moment when transaction starts.
Every row has BeginTs and EndTs timestamps, which correspond to a Global Transaction Timestamp of the transaction that created or deleted this version of a row. A special timestamp value, called Infinity, is used to indicate rows that have not been deleted (EndTs=Infinity). SQL Server never updates rows. When row needs to be modified, it deletes (updates EndTs) of original row and create a new row version with a new timestamp and EndTs of Infinity.
A transaction can only see rows that existed at time of transaction start, which is similar to SNAPSHOT isolation levels for on-disk tables. However, for in-memory data that behavior does not change with isolation level. REPEATABLE READ and SERIALIZABLE isolation levels follow exactly the same rules.
Figure 1 illustrates an example of data access and visibility. It shows hash index on Name (on left side) and multiple data rows linked into that index pointer chain. Again, if you do not know what hash index is, consider to read about it in documentation. For simplicity sake, let’s consider that hash function is based on the first letter of the Name.
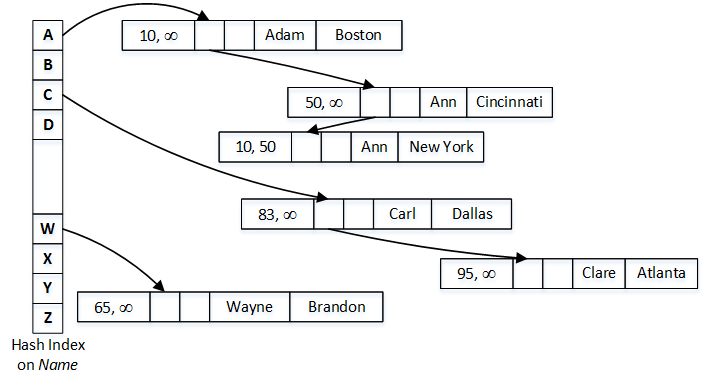
01. Hash index and data rows
Let’s assume that we need to run a query that selects all rows with Name=’Ann’ in the transaction that started when Global Transaction Timestamp was 65. SQL Server calculates hash value for Ann, which is ‘A‘ and find corresponding bucket in the hash index. It follows the pointer from that bucket, which references a row with Name=’Adam’. This row has BeginTs of 10 and EndTs of Infinity; therefore, it is visible to the transaction. However, Name value does not match the predicate and row is ignored.
As the next step, SQL Server follows the pointer from Adam index pointer array, which references first Ann row. This row has BeginTs of 50 and EndTs of Infinity; therefore, it is visible to the transaction and needs to be selected.
As the final step, SQL Server follows the next pointer in the index. Even though, last row also has Name=’Ann’, it has EndTs of 50, which indicates that row has been deleted before transaction started and it is invisible to the transaction.
I hope, that provides you very basic example of access methods and data visibility used in in-memory OLTP. However, before we start diving deeper into internal implementation of concurrency model in Hekaton, I would like us to remember about data logical consistency rules provided by different transaction isolation levels.
Any transaction isolation level resolve write/write conflicts. Multiple transactions cannot update a same row simultaneously. Different outcomes are possible, in some cases, SQL Server uses blocking and preventing transactions from accessing uncommitted changes until transaction that made those changes is committed. In other cases, SQL Server rolls back one of transactions due to update conflict. In-memory OLTP uses latter method to resolve write/write conflicts and abort the transaction. We will discuss this situation later, and now let’s focus on the read data consistency.
There are three major data inconsistency issues possible in multi-user environments, such as:
Dirty Reads: Transaction reads uncommitted (dirty) data from the other uncommitted transactions.
Non-Repeatable Reads: Subsequent attempts to read the same data from within the same transaction returns different results. This data inconsistency issue arises when the other transactions modified, or even deleted, data between the reads done by affected transaction.
Phantom Reads: This phenomenon occurs when subsequent reads within the same transaction return the new rows (the ones transaction did not read before). This happens when another transaction inserted the new data in between the reads done by affected transaction.
Figure 2 below shows data inconsistency issues that are possible for different transaction isolation levels.

02. Transaction isolation levels and data consistency
With exception of SNAPSHOT isolation level, SQL Server uses locking to address data inconsistency issues when dealing with on-disk tables. It blocks sessions from reading or modifying data to prevent data inconsistency. Such behavior also means that in case of write/write conflict, last modification wins. For example, when two transactions are trying to modify a same row, SQL Server blocks one of transactions until another transaction is committed allowing blocked transactions to modify data afterwards. No errors or exceptions would be raised, however changes from the first transactions would be lost.
SNAPSHOT isolation level uses row-versioning model where all data modifications done by other transactions are invisible for the transaction. It is implemented differently in case of on-disk and memory-optimized tables however, logically it behaves the same. Write/write conflicts in that model are resolved by aborting and rolling back the transactions.
It is also worth mentioning that even though SERIALIZABLE and SNAPSHOT isolation levels provide the same level of protection against data inconsistency issues, there is a subtle difference in their behavior. With SNAPSHOT isolation level transaction sees a data as of at beginning of transaction. With SERIALIZABLE isolation level, transaction sees a data as of a time when data was accessed a first time. Consider a situation when session is reading data from a table in the middle of transaction. If another session changed data in that table after transaction started but before data was read, transaction in SERIALIZABLE isolation level would see the changes while SNAPSHOT transaction would not.
As I already mentioned, In-memory OLTP supports three transaction isolation levels – SNAPSHOT, REPEATABLE READ and SERIALIZABLE. However, in-memory OLTP uses completely different approach to enforce data consistency rules comparing to on-disk tables. Rather than block or being blocked by the other sessions, in-memory OLTP validates data consistency at transaction commit time throwing exception and rolling back the transaction if rules were violated. This is very confusing behavior comparing to on-disk tables – transaction is continue working without being blocked. It returns data to clients; however it is failed to commit in the end.
Let’s look at a few examples that demonstrates such behavior. As the first step let’s create memory-optimized table and insert a few rows there.
create table dbo.HKData
(
ID int not null,
Col int not null,
constraint PK_HKData
primary key nonclustered hash(ID)
with (bucket_count=64),
)
with (memory_optimized=on, durability=schema_only);
insert into dbo.HKData(ID, Col)
values(1,1),(2,2),(3,3),(4,4),(5,5);
Figure 3 shows two examples how REPEATABLE READ transactions handle non-repeatable and phantom reads. Session 1 transaction starts at time when first SELECT operator executes. Remember, that SQL Server starts transaction at moment of first data access rather than at time of BEGIN TRAN statement.

03. REPEATABLE READ behavior
As you see, with memory-optimized tables, other sessions were able to modify data that was read by active REPEATABLE READ transaction, which led to transaction abort at time of commit. This is completely different behavior from on-disk tables, where other sessions would be blocked until REPEATABLE READ transaction successfully commits.
It is also worth mentioning that in case of memory-optimized tables, REPEATABLE READ isolation level protects you from Phantom Read phenomenon, which is not the case with on-disk tables.
As the next step, let’s repeat our tests in SERIALIZABLE isolation level. You can see a code and results of the execution in Figure 4.
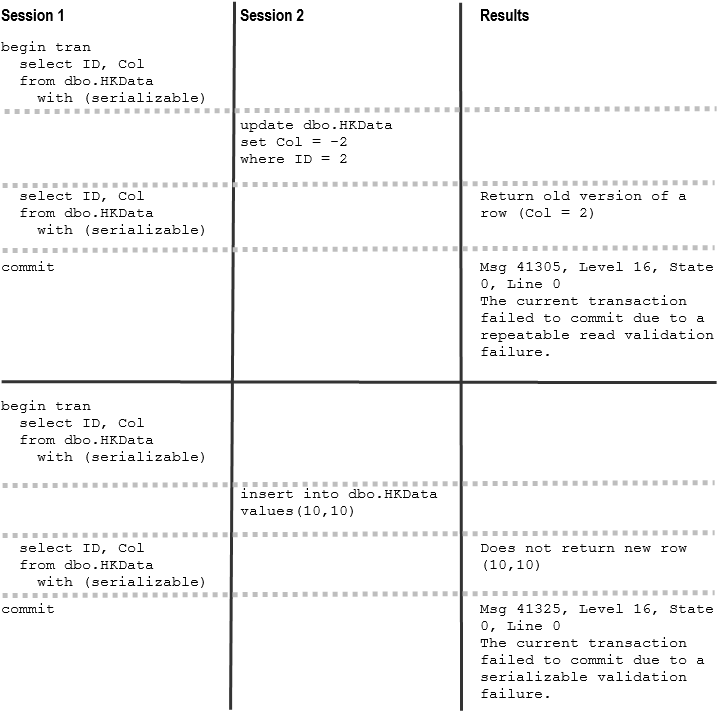
04. SERIALIZABLE behavior
As you see, SERIALIZABLE isolation level prevents session to commit transaction when another session inserted a new row and violate serializable validation. Similar to REPEATABLE READ isolation level, this behavior is different from on-disk tables, where SERIALIZABLE transaction would successfully commit blocking other sessions until it is done.
Finally, let’s repeat our tests in SNAPSHOT isolation level. The code and results are shown in Figure 5.

05. SNAPSHOT behavior
SNAPSHOT isolation level works similar to on-disk tables and protects from Non-Repeatable Reads and Phantom Reads phenomenon. As you can guess, it does not need to perform repeatable read and serializable validations at commit stage and, therefore, reduces the load to SQL Server.
Write/write conflicts work the same way regardless of transaction isolation level in in-memory OLTP. SQL Server does not allow transaction to modify a row that has been modified by other uncommitted transactions. Figures 6 and 7 illustrate such behavior. It uses SNAPSHOT isolation level, however behavior does not change in different isolation levels.

06. Write/write conflict (1)

07. Write/write conflict (2)
Now, let’s dive deeper and look what happens under the hood. Figure 8 illustrates lifetime of in-memory OLTP transaction.
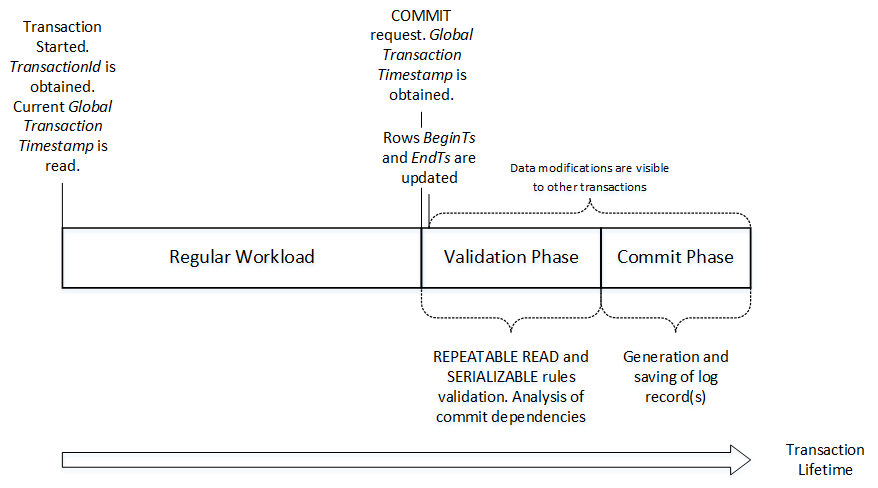
08. In-memory OLTP transaction lifetime
At time, when new transaction starts, it generates new TransactionId and obtains current Global Transaction Timestamp value. Global Transaction Timestamp value dictates what version of the rows are visible to the transaction and timestamp value should be in between BeginTs and EndTs for row to be visible. During data modifications, however, transaction analyzes if there are any uncommitted versions of the rows preventing write/write conflicts when multiple sessions modify the same data.
When transaction needs to delete a row, it updates EndTs timestamp with TransactionId value, which also has an indicator that timestamp contains TransactionId rather than Global Transaction Timestamp. Insert operation creates of a new row with BeginTs of TransactionId and EndTs of Infinity. Finally, update operation consists of delete and insert operations internally.
Figure 9 shows the data rows after we created and populated dbo.HKData table. I am omitting hash index structure for simplicity sake.

09. Data rows after table creation
Let’s assume that we have transaction started at time when Global Transaction Timestamp value was 10 and TransactionId generated as -5. I am using negative value for TransactionId to illustrate a difference between two values in the figures below.
Let’s assume that transaction performs a few data modification operations as shown below.
insert into dbo.HKData with (snapshot) (ID, Col) values(10,10); update dbo.HKData with (snapshot) set Col = -2 where ID = 2; delete from dbo.HKData with (snapshot) where ID = 4;
Figure 10 illustrates the state of a data after data modifications. INSERT statement created a new row, DELETE statement updated EndTs value in the row with ID=4 and UPDATE statement changed EndTs value of the row with ID=2 and created a new version of a row with same ID.
It is important to mention that transaction maintains a write set – pointers to rows that have been inserted and deleted by transaction. Moreover, in SERIALIZABLE and REPEATABLE READ isolation levels, transactions maintains read set of the rows that were read by a transaction. Write set is used to generate transaction log records, while read set is used to perform REPEATABLE READ and SERIALIZABLE rules validation.
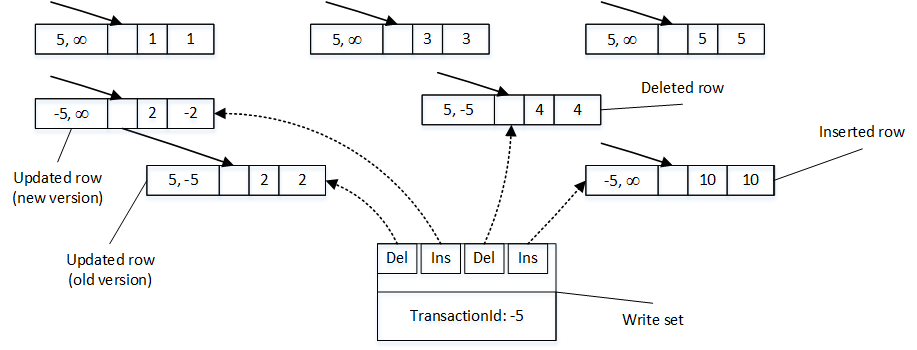
10. Data Rows after update (transaction is active)
When COMMIT request is issued, transaction starts validation phase. First, it generates new Global Transaction Timestamp value and replaces TransactionId with this value in all BeginTs and EndTs timestamps in the rows it modified. Figure 11 illustrates that, assuming that Global Transaction Timestamp value is 11.
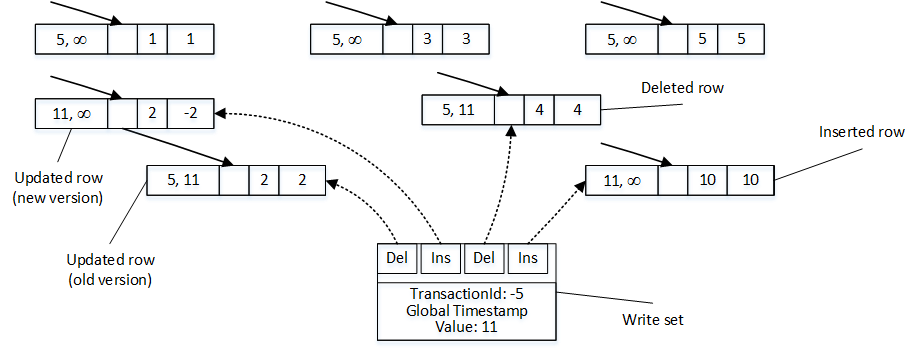
11. Committing transaction (pre-commit stage)
At this moment, rows modified by transactions become visible to other transactions in the system even though transaction has yet to be committed. Other transactions can see uncommitted rows, which leads to the situation called commit dependency. Those transactions would not be blocked at time when they access those rows, however they would not return data to clients nor commit until original transaction they have commit dependency on would commit itself. If, for some reason, that transaction failed to commit, other dependent transactions would be rolled back and error would be generated.
Commit dependency is technically a case of blocking in in-memory OLTP. However, validation and commit phases of transactions are relatively short and that blocking should not be excessive.
After timestamps in rows were replaced, transaction validates REPEATABLE READ and SERIALIZABLE rules and waits for commit dependencies to clear. When it is done, transaction moves to commit phase, generate one or more log records, save them to transaction log and complete the transaction.
Obviously, validation phase of transactions in REPEATABLE READ and SERIALIZABLE isolation levels is longer than in SNAPSHOT isolation level due to rules validation. Do not use them unless you have legitimate use-case for such data consistency. To be frank, I do not see much use-cases for them besides importing and exporting data to/from in-memory tables.