A while ago triggers were slow. Very slow. In the versions prior to SQL Server 2005, triggers scanned transaction log in order to build internal inserted and deleted tables. That approach has been changed in SQL Server 2005 when triggers started to use version store – similarly to what optimistic locking is using. That helps with performance but same time introduces a few interesting issues. Let’s take a look.
First of all, let’s create a table and populate it with some data. I would like to point that I’m using tempdb in that example mainly to show that this behavior is completely independent from transaction isolation levels and optimistic locking database options.
Now let’s take a look at what we have in the index (click on the image to open it in the different tab)
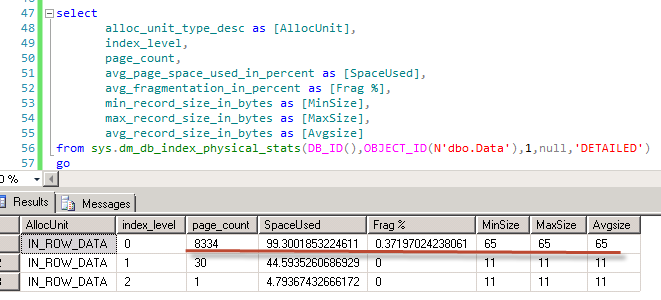
As you can see, we have 65 bytes rows without any fragmentation. So far so good. Now let’s update Value column.

We updated fixed-width column. Row size has not changed. No fragmentation here. As the next step let’s create a trigger.

As you see, trigger itself is empty – we don’t even access inserted/deleted tables there. Now let’s update our table again
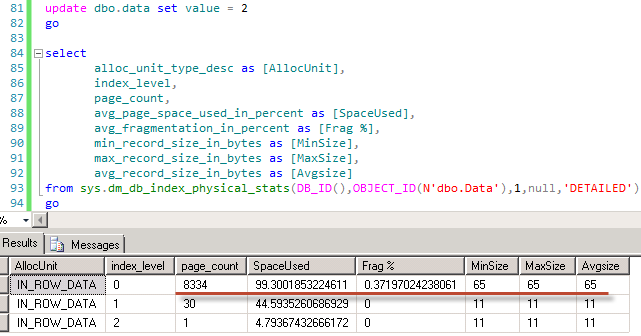
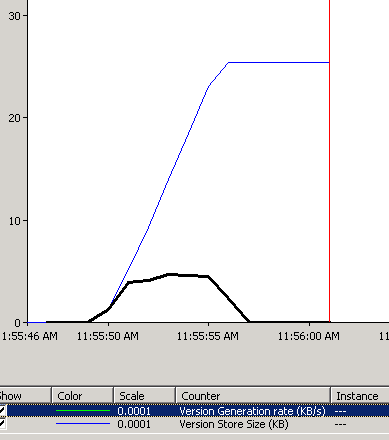
Still the same thing. But if we look at performance monitor counters – we can see that update now generates version store activity.
As the next step I’d like to add LOB column to the table. I’m using varchar(max) but you can replace it with nvarchar, binary, xml or clr data type. It would be the same.
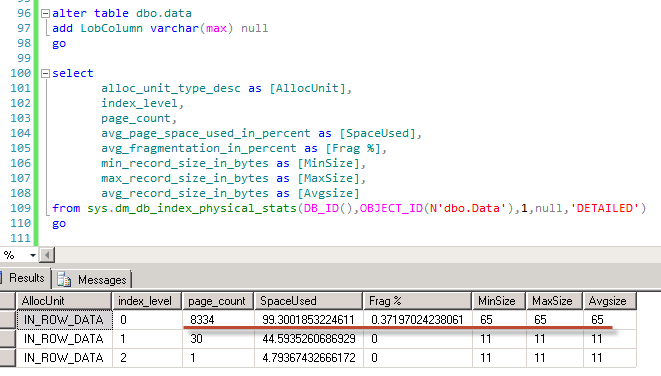
Column is nullable so alteration here is pure metadata operation. And now let’s run the update statement.

Oops – now we have 14 bytes version store pointer added to the row. That introduces heavy fragmentation (new versions are larger so they don’t fit into the pages) and double our storage space. Well, a little bit unexpected development. Generally speaking this is very similar problem with what we have with data modifications when we use optimistic isolation levels.
OK, it happens with LOB columns. Now let’s check the case when ROW OVERFLOW is possible. Let’s drop LOB column and add to varchar(5000) columns here.

Again, we rebuilt the index – 14 bytes pointers are went away. Now let’s run update statement again.

Same thing – extra 14 bytes and fragmentation.
And let’s prove that trigger is the problem. First, let’s drop the trigger and rebuild the index
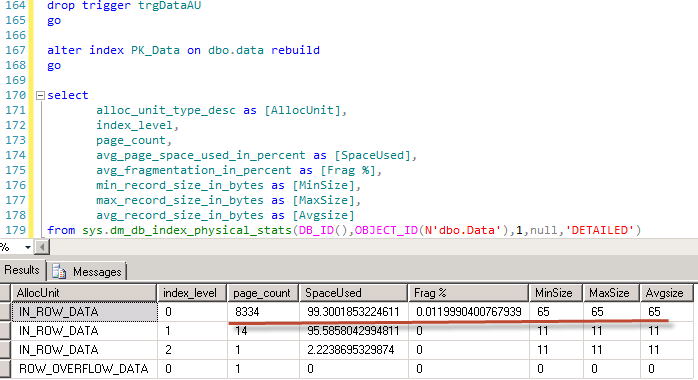
And next – run update again.

As you can there are no 14 bytes version store pointer nor fragmentation.
At last, let’s take a look at the very interesting thing – let’s see what happens when we have ON DELETE trigger. Generally speaking, when we delete the row, only thing that SQL Server initially does is mark row as the “ghost” row. Just the change in the header. But with the trigger the situation could be different.

You can see, that in our case we ended up with page split on delete!

This behavior adds extra arguments to the discussion why triggers are bad in general. Triggers add extra load to tempdb. And in case if you have the possibility of row overflow or LOB allocations, you’d end up with 14 bytes version store pointer and extra fragmentation.
Source code is available for download
P.S. I’d like to thank Paul White for his help with that post.
Hi Dmitri,
I’m glad to see you blogged this (very well!) and thank you for the mention! I plan to blog something on this topic myself because I don’t think it is well-understood by many people – I’ll link back to this post of course.
Thanks,
Paul
Pingback: Writing Triggers in the Right Way | About Sql Server