Almost one year ago I blogged about table partitioning in Microsoft SQL Server. I mentioned one specific case when table partitioning hurt the performance – case when you need to select top N rows using aligned non-clustered index. I said that there is no good workarounds for this particular case. Well, there is one. Kind of.
First, let’s take a look at the original problem. I adjusted the script I used an year ago a little bit. First, assuming we have non-partitioned table with clustered index on ID and non-clustered index on DateModified date. Let’s create that table an populate it with some data (if you click on the images below those would be opened in the new browser window).

Now let’s say we need to select top 100 rows based on DateModified column. This is quite typical scenario you’re using in production systems when you need to export and/or process the data.

As long as table is not partitioned, you can see that plan is very good. Basically SQL Server looks up the first row in the non-clustered index for specific DateModified value and do the ordered scan for the first 100 rows. Very efficient. Now, let’s partition the table based on DateCreated on quarterly basis.

And now – let’s run that statement again. As you can see, SQL Server started to use CI scan with SORT Top N. I explained why it happened in the previous post.

If we force SQL Server to use the index, the plan would be even worse in this particular case.
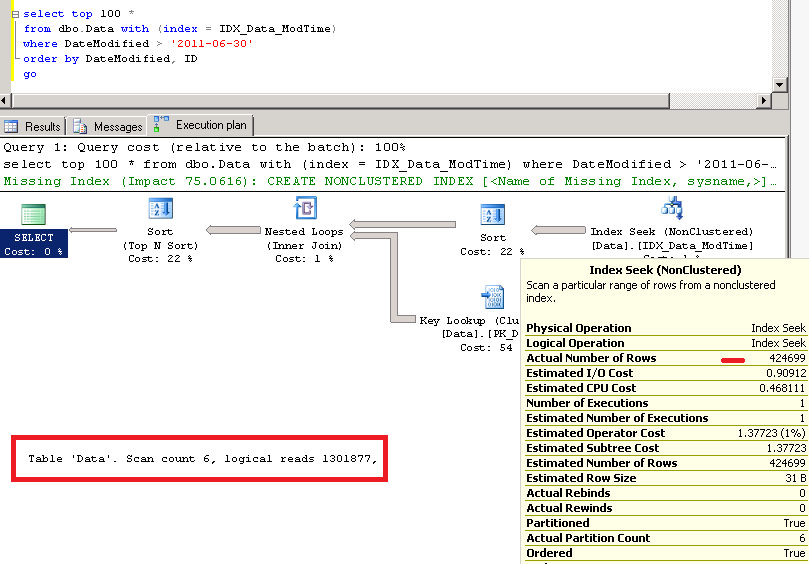
Although If you have the huge transactional table and # of rows with DateModified > ? is relatively small, the plan above could be more efficient than CI scan but SCAN/SORT TOP N would always be there.
Is there solution to this problem? Well, yes and no. I don’t know if there is generic solution that would work in all cases, although if you table has limited number of partitions and packet size is not huge there is one trick you can do.
Let’s take a look at the picture that shows how non-clustered index is aligned.
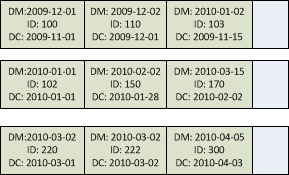
I just copied it from the old post, so dates are a little bit off. SQL Server cannot use the same efficient plan with non-partitioned/non-aligned index because data could reside on the different partitions. Although, we can still use ordered index scan within each partition. And next, if we select top N rows from each partition independently, union them all and next sort them all together and grab top N rows, we will have what we need. And we can do it using $Partition function. Let’s take a look:

Each PData CTE uses $Partition function that limits data search within the single partition so SQL Server can use ordered index scan there. In fact, it would be very similar to what we had when we did the select against non-partitioned table. Next, AllData CTE merges all results from PData CTEs and sort them based on DateModified and ID – returning top 100 rows. Last select joins the data from the main table with IDs returned from AllData CTE. One very important point I want to stress – as you can see, PData/AllData CTEs don’t select all columns from the table but only columns from the non clustered index. Data from the clustered index selected based on the join in the main select. This approach limits CTE operation to use index only and avoids unnecessary key lookups there.
If we look at result set, we can see that data is basically selected from partition 3 and 4.
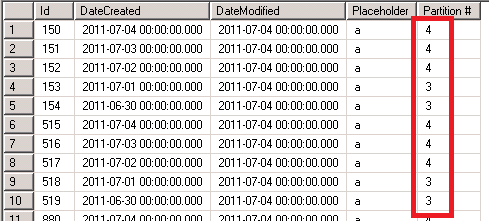
And now let’s look at the execution plan.
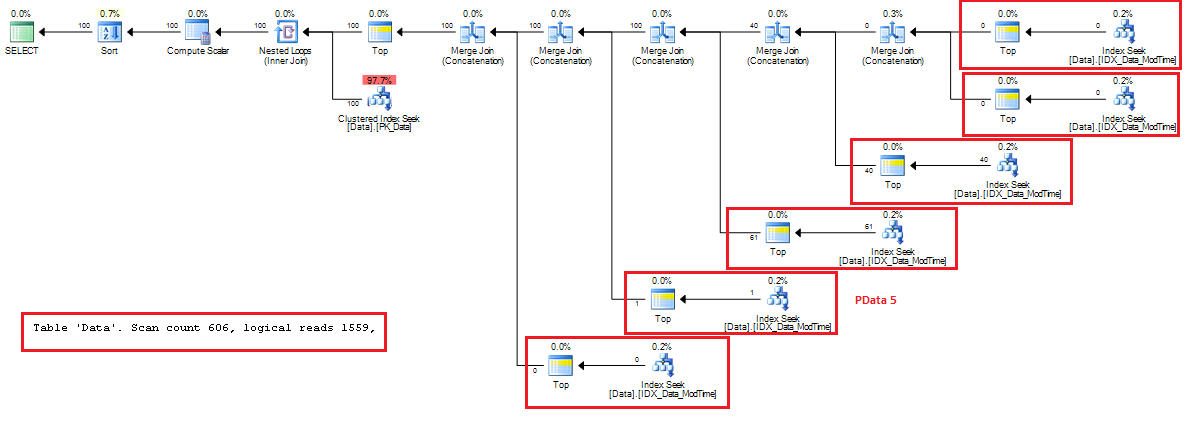
As you can see, red rectangles represent PData CTEs. There is no key lookups until very last stage and those lookups are done only for 100 rows. One other thing worth to mention that SQL Server is smart enough to perform SORT as part of Concatenation operator and illuminate unnesesary rows there. As you can see, only 1 row is returned as part of PData5 – SQL Server does not bother to get other 99 rows.
This particular example has the data distributed very evenly (which usually happens with DateCreated/DateModified pattern). Generally speaking, cost of the operation will be proportional to the number of partitions multiplied by packet size. So if you have the table with a lot of partitions, that solution would not help much. On the other hand, there are usually some tricks you can use. Even in this particular case you don’t need to include PData6 to the select. This partition is empty. Also, you can put some logic in place – perhaps create another table and store most recent DateModified value per partition. In such case you can dynamically construct the select and exclude partitions where data has not been recently modified.
As the disclaimer, that solution is not the silver bullet especially if you have a lot of partitions and need to select large data packet. But in some cases it could help. And PLEASE TEST IT before you put it to production
Source code is available for download
UPDATE (2012-03-11): Look at that post to see how to implement that particular example in a different way