One of the biggest challenges for the developers who are not familiar with T-SQL is understanding the conceptual difference between client side and T-SQL functions. T-SQL functions look very similar to the functions developed withhigh-level programming languages. While encapsulation and code reuse are very important patterns there, it could hurt database code badly.
There are 2 kinds of functions in Microsoft SQL Server that can return table result set. The good one and the bad one. Unfortunately the bad one is much easier to use and understand for people who used ti work with high-level languages.
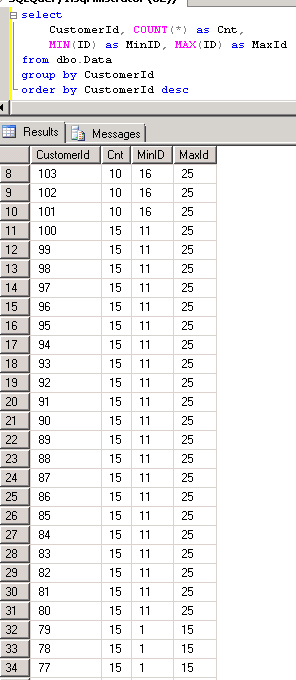
Let’s take a look. First, let’s create 2 tables and populate them with the data. Don’t put much attention how good is the data and how logically correct are the statements – we’re talking about performance here.


Now let’s create the multi-statement function here and run it. As you can see, total execution time is 176 millisecond in my environment.

Now let’s do inline function. We need to change the original select statement and use cross apply here. Looks more complex but at the end – execution time is 106 milliseconds – about 40 percent faster.

Now let’s check the execution plans – as you can see – first plan (multi-statement) is very simple – CI scan + aggregate. Second (inline) introduces much more complicated execution plan. Also it worth to notice that SQL Server shows that second plan takes all the cost.
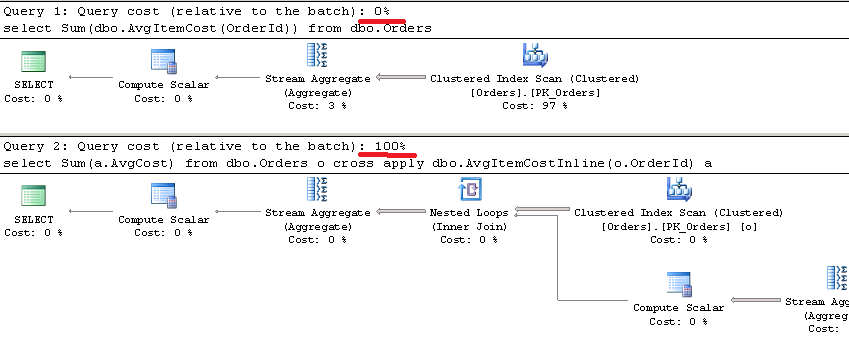
How could it happen? How less expensive and simpler plan could run slower? The answer is that SQL Server lies – it does not show multi-statement function executions there at all. Let’s run the profiler and start to capture SP:Starting event.

As you can see – multi-statement function introduces SP call for each row processed. Think about all overhead related with that. Inline functions are working similarly to C++ inline functions – those are “embedded” to the execution plan and don’t carry any SP calls overhead.
So the bottom line – don’t use multi-statement functions if possible. I’m going to start the set of the posts related with CTEs – and will show how you can convert very complex multi-statement functions to inline ones.
Source code is available for download
Update (2011-12-18):
As Chirag Shah mentioned in comments, my example above is not 100% valid. I demonstrated the difference between Inline TVF and Scalar Multi-Statement function. So let’s correct that and and run the test again. (Image is clickable)

As you can see, results are even worse. The main point I want to stress – as long as UDF body has begin/end keywords, SQL Server treats them similarly to stored procedures. And that hurts.
Source code has been updated to include the last example