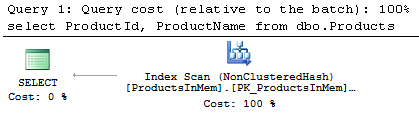
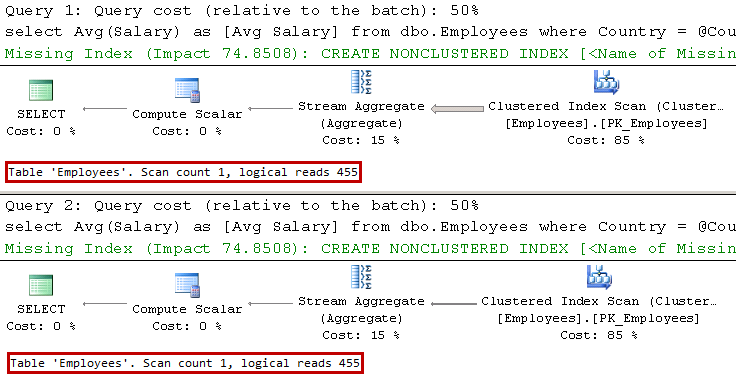
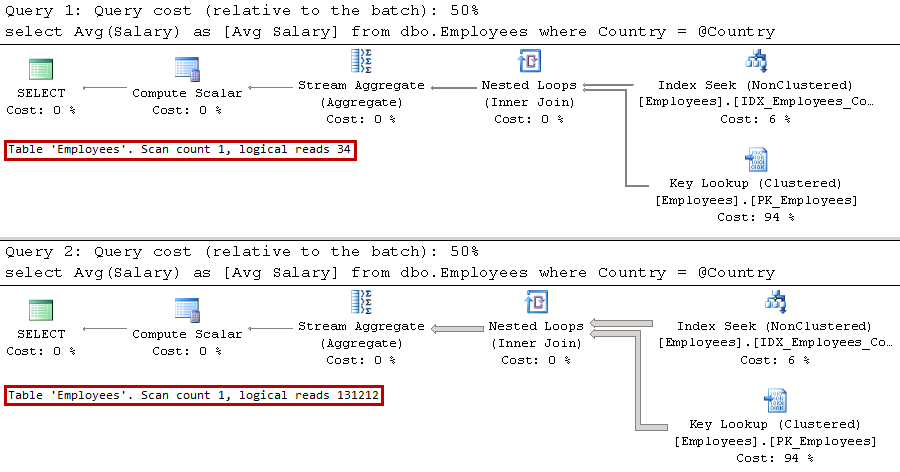
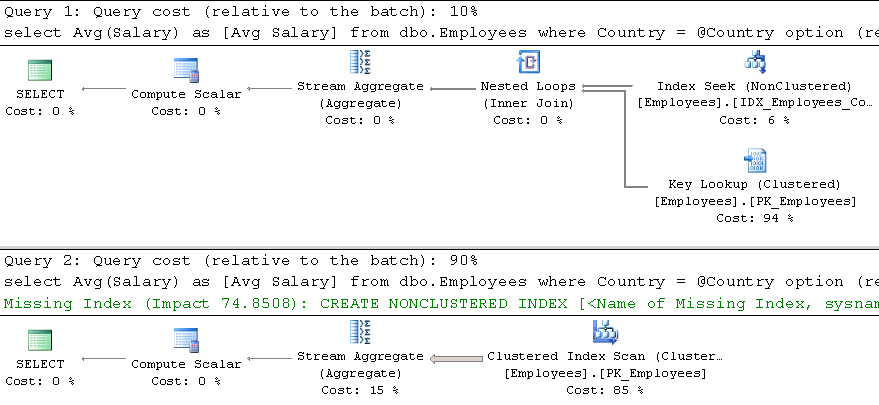
Modern software systems have become extremely complex. They consist of a large number of components and services responsible for various tasks. They must be scalable and redundant and need to be able to handle load growth and survive hardware failures and crashes.
The common approach to solving scalability and redundancy issues is to design the systems in a way that permits to deploy and run multiple instances of individual services. It allows adding more servers and instances as the load grows and helps you survive hardware failures by distributing the load across other active servers. The services are usually implemented in stateless way, and they don’t store or rely on any local data.
Most systems, however, have data that needs to be shared across the instances. For example, front-end web servers often need to maintain web session states. Back-end processing services often need to have shared cache with some data.
Historically, there were two approaches to address this issue. The first one was to use dedicated storage/cache and host it somewhere in the system. Remember the old ASP.Net model that used either a SQL Server database or a separate web server to store session data? The problem with this approach is limited scalability and redundancy. Storing session data in web server memory is fast but it is not redundant. A SQL Server database, on the other hand, can be protected but it does not scale well under the load due to page latch contention and other issues.
Another approach was to replicate content of the cache across multiple servers. Each instance worked with the local copy of the cache while another background process distributed the changesto the other servers. Several solutions on the market provide such capability; however, they are usually expensive. In some cases, the license cost for such software could be in the same order of magnitude as SQL Server licenses.
Fortunately, you can use In-Memory OLTP as the solution. In the nutshell, it looks similar to the ASP.Net SQL Server session-store model; however, In-Memory OLTP throughput and performance improvements address the scalability issues of the old on-disk solution. You can improve performance even further by using non-durable memory-optimized tables. Even though the data will be lost in case of failover, this is acceptable in most cases.
However, the 8,060-byte maximum row size limit introduces challenges to the implementation. It is entirely possible that a serialized object will exceed 8,060 bytes. You can address this by splitting the data into multiple chunks and storing them in multiple rows in memory-optimized table.
You saw an example of a T-SQL implementation in my previous blog post. However, using T-SQL code and an interop engine will significantly decrease the throughput of the solution. It is better to manage serialization and split/merge functional on the client side.
Let’s look at the oversimplified example and see how we can handle that in the client code. The first listing below creates the table that we will use to store the data along with three stored procedures to load and save data to/from the table.
create table dbo.SessionStore
(
ObjectKey uniqueidentifier not null,
ExpirationTime datetime2(2) not null,
ChunkNum smallint not null,
Data varbinary(8000) not null,
constraint PK_ObjStore
primary key nonclustered hash (ObjectKey, ChunkNum)
with (bucket_count=1048576),
index IDX_ObjectKey
nonclustered hash(ObjectKey)
with (bucket_count=1048576)
)
with (memory_optimized = on, durability = schema_only);
go
create type dbo.tvpObjData as table
(
ChunkNum smallint not null
primary key nonclustered hash
with (bucket_count = 128),
Data varbinary(8000) not null
)
with(memory_optimized=on)
go
create proc dbo.SaveObjectToStore
(
@ObjectKey uniqueidentifier
,@ExpirationTime datetime2(2)
,@ObjData dbo.tvpObjData readonly
)
with native_compilation, schemabinding, exec as owner
as
begin atomic with
(
transaction isolation level = snapshot
,language = N'English'
)
delete dbo.SessionStore
where ObjectKey = @ObjectKey
insert into dbo.SessionStore(ObjectKey, ExpirationTime, ChunkNum, Data)
select @ObjectKey, @ExpirationTime, ChunkNum, Data
from @ObjData
end
go
create proc dbo.SaveObjectToStore_Row
(
@ObjectKey uniqueidentifier
,@ExpirationTime datetime2(2)
,@ObjData varbinary(8000)
)
with native_compilation, schemabinding, exec as owner
as
begin atomic with
(
transaction isolation level = snapshot
,language = N'English'
)
delete dbo.SessionStore
where ObjectKey = @ObjectKey
insert into dbo.SessionStore(ObjectKey, ExpirationTime, ChunkNum, Data)
values(@ObjectKey, @ExpirationTime, 1, @ObjData)
end
go
create proc dbo.LoadObjectFromStore
(
@ObjectKey uniqueidentifier not null
)
with native_compilation, schemabinding, exec as owner
as
begin atomic
with
(
transaction isolation level = snapshot
,language = N'English'
)
select t.Data
from dbo.SessionStore t
where t.ObjectKey = @ObjectKey and ExpirationTime >= sysutcdatetime()
order by t.ChunkNum
end
As you can see, there are two different stored procedures that save data to the table. The first one – dbo.SaveObjectToStore – uses memory-optimized table-valued parameter and can be used in the case, when serialized object data is greater than 8,000 bytes. The second stored procedure – – dbo.SaveObjectToStore_Row – accepts varbinary(8000) parameter and can be used if serialized object is within 8,000-byte range. This is strictly for optimization purposes. Even though memory-optimized table-valued parameters are very fast, they are still slower compating to the regular parameter.
The client code would contain several static classes. The first ObjStoreUtils class provides four methods to serialize and deserialize objects into the byte arrays, and split and merge those arrays to/from 8,000-byte chunks. You can see the code below.
public static class ObjStoreUtils
{
// Serialize object of type T to the byte array
public static byte[] Serialize(T obj)
{
using (var ms = new MemoryStream())
{
var formatter = new BinaryFormatter();
formatter.Serialize(ms, obj);
return ms.ToArray();
}
}
// Deserialize byte array to the object
public static T Deserialize(byte[] data)
{
using (var output = new MemoryStream(data))
{
var binForm = new BinaryFormatter();
return (T)binForm.Deserialize(output);
}
}
/// Split byte array to the multiple chunks
public static List<byte[]> Split(byte[] data, int chunkSize)
{
var result = new List<byte[]>();
for (int i = 0; i < data.Length; i += chunkSize) { int currentChunkSize = chunkSize; if (i + chunkSize > data.Length)
currentChunkSize = data.Length - i;
var buffer = new byte[currentChunkSize];
Array.Copy(data, i, buffer, 0, currentChunkSize);
result.Add(buffer);
}
return result;
}
// Combine multiple chunks into the byte array
public static byte[] Merge(List<byte[]> arrays)
{
var rv = new byte[arrays.Sum(a => a.Length)];
int offset = 0;
foreach (byte[] array in arrays)
{
Buffer.BlockCopy(array, 0, rv, offset, array.Length);
offset += array.Length;
}
return rv;
}
}(
The ObjStoreDataAccess class shown in the next listing, loads and saves binary data to and from the database. It utilizes another static class – DBConnManager, which returns the SqlConnection object to the target database. This class is not shown there.
public static class ObjStoreDataAccess
{
// Saves data to the database
public static void SaveObjectData(Guid key,
DateTime expirationTime, List<byte[]> chunks)
{
if (chunks == null || chunks.Count == 0)
return;
using (var cnn = DBConnManager.GetConnection())
{
using (var cmd = cnn.CreateCommand())
{
cmd.CommandType = CommandType.StoredProcedure;
cmd.Parameters.Add("@ObjectKey",
SqlDbType.UniqueIdentifier).Value = key;
cmd.Parameters.Add("@ExpirationTime",
SqlDbType.DateTime2).Value = expirationTime;
if (chunks.Count == 1)
{
cmd.CommandText = "dbo.SaveObjectToStore_Row";
cmd.Parameters.Add("@ObjData",
SqlDbType.VarBinary, 8000).Value = chunks[0];
}
else
{
cmd.CommandText = "dbo.SaveObjectToStore";
var tvp = new DataTable();
tvp.Columns.Add("ChunkNum", typeof(short));
tvp.Columns.Add("ChunkData", typeof(byte[]));
for (int i = 0; i < chunks.Count; i++)
tvp.Rows.Add(i, chunks[i]);
var tvpParam = new SqlParameter("@ObjData",
SqlDbType.Structured)
{
TypeName = "dbo.tvpObjData",
Value = tvp
};
cmd.Parameters.Add(tvpParam);
}
cmd.ExecuteNonQuery();
}
}
}
// Load data from the database
public List<byte[]> LoadObjectData(Guid key)
{
using (var cnn = DBConnManager.GetConnection())
{
using (var cmd = cnn.CreateCommand())
{
cmd.CommandText = "dbo.LoadObjectFromStore";
cmd.CommandType = CommandType.StoredProcedure;
cmd.Parameters.Add("ObjectKey",
SqlDbType.UniqueIdentifier).Value = key;
var result = new List<byte[]>();
using (var reader = cmd.ExecuteReader())
{
while (reader.Read())
result.Add((byte[])reader["Data"]);
}
return result;
}
}
}
}
Finally, the ObjStoreService class shown below puts everything together and manages the entire process. It implements two simple methods,Load and Save, calling the helper classes defined above.
public static class ObjStoreService
{
private const int MaxChunkSize = 8000;
// Saves object in the object store
public static void Save(Guid key,
DateTime expirationTime, object obj)
{
var objectBytes = ObjStoreUtils.Serialize(obj);
var chunks = ObjStoreUtils.Split(objectBytes, MaxChunkSize);
ObjStoreDataAccess.SaveObjectData(key, expirationTime, chunks);
}
// Loads object from the object store
public static T Load(Guid key) where T: class
{
var chunks = ObjStoreDataAccess.LoadObjectData(key);
if (chunks.Count == 0)
return null;
var objectBytes = ObjStoreUtils.Merge(chunks);
return ObjStoreUtils.Deserialize(objectBytes);
}
}
Obviously, this is oversimplified example, which I used just to illustrate the concept. Production implementation could be significantly more complex, especially if there is the possibility that multiple sessions can update the same object simultaneously. You can implement retry logic using the similar approach with what we did enforcing uniqueness/referential integrity or create some sort of object locking management in the system if this is the case.
It is also worth mentioning that you can compress binary data before saving it into the database. The compression will introduce unnecessary overhead in the case of small objects; however, it could provide significant space savings and performance improvements if the objects are large. I did not include compression code in the example, although you can easily implement it with the GZipStream or DeflateStream classes.
You can download the demo application from “Expert SQL Server In-Memory OLTP” Companion materials. It has slightly different implementation – I denormalized classes a little bit to reduce C# code overhead during the demos when it is running on the same box with SQL Server. However, it is very similar to what you saw in this post.
P.S. I want to thank Vladimir Zatuliveter (zatuliveter at gmail dot com) for his help with the code.