… are available for download
SQL Saturday #79 Presentations
Leave a reply
… are available for download
One of very interesting phenomenon we have not discussed earlier when we covered lock types and isolation levels is duplicate readings. As we already know, read committed isolation level protects us from reading of modified and uncommitted data but the scope of protection is “this row/right now”. So what happens if row updates during the time when query is executed.
Let’s take a look. First, as usual, let’s create the table and populate it with 100,000 rows:

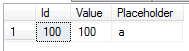
As you can see, even if we don’t have any unique constraints, that table has unique ID and Value columns (equal to each other) with values from 1 to 100,000. We can even run SQL query and see that there is no duplications.

Now let’s start another session and lock one row:

As you can see, we don’t commit transaction, so exclusive (X) lock is in play. Now let’s start another session, create temporary table and simply copy data from our main table there. When we run this statement in read committed mode, it would be blocked because there it tries to acquire shared (S) lock on the row that held (X) lock from the previous session.

Now let’s come back to the previous session and update another row (value column this time) and commit transaction.
![]()
As you can see, first (X) lock has been released and our blocked session resumes and finishes copying the data. And now, let’s see what we have in this table –

Surprise! We have 1 extra row – the one the first session updated. This row appears twice – with old and new values in Values column. In order to understand what happened, let’s take a look at the execution plan for insert/select statement.
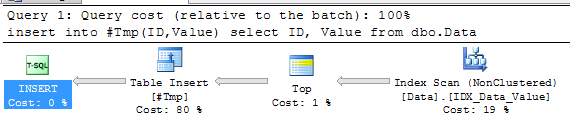
As you can see, plan uses index scan. Let’s think what happened – select read first 999 rows (with ID from 1 to 999) and was blocked by (X) lock from the different transaction. Next, that transaction updated Value column for the row with ID = 1. Because Value is the index key, that index row has been moved in the index. As result, when select resumes, it read this row (with ID = 1) second time during remaining part of the index scan. Fun?
With read uncommitted another factor could come in play – sometime SQL Server can decide to use allocation scan. There are a lot of factors that can lead to that decision – but if it happens and if you’re lucky enough to have page split during query execution, you can easily have rows to be read/processed more than once.
Fortunately neither of those cases happen quite often. I’d say I saw duplicate readings in production systems maybe 2-3 times during my career. But it could give you a lot of grey hairs – think what if #Temp table had primary key on ID and you would get primary key violation on the data that guaranteed to be unique? If you want to be protected from that you have to use optimistic isolation levels. I (promise another time) is going to blog about them next time 🙂
Source code is available for download
I cannot believe that year past since I started the blog. It happened right before SQL Saturday #40 event in Miramar, FL. Well, in 2 weeks this wonderful place is going to host SQL Saturday #79 event and I’m going to present 2 sessions there:
Stop by and say “Hello!” if you’re planning to attend!
It’s been a while since I posted any Sunday T-SQL Tips. Well, let’s do it today even if it’s Thursday :). I feel a little bit guilty stopping to blog about locking and blocking. I promise, I will blog about optimistic isolation levels in 2 weeks.
Today I want to talk about 2 very similar operators: SET and SELECT. If you ask T-SQL Developer what to use, in most part of cases she/he answers that it does not really matter. Well, it’s correct – up to degree. Those operators work in the same way unless they work differently. Let’s take a look.
First, let’s create a table and populate it with 50 rows.
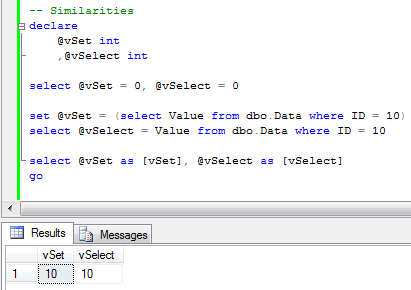
Now, let’s look at the similarities. Let’s query the row. As you can see, both operators work the same way. Plain and perfect.
Now let’s change the query and try to select the row that does not exist in the table.
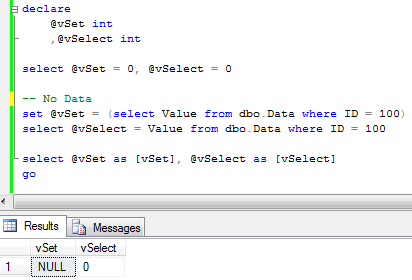
And here is the first major difference – SET operator “sets” variable to null. SELECT kept old value. It makes sense, if you think about it – SET assignes result from subquery that did not return any data. But more interesting behavior is when query tries to select multiple rows. Let’s run select first.

As you can see, it processes 9 rows and at the end variable has the value from the last one. Let’s check SET operator:

As you can see – it failed. Again, makes sense if you think about it from subquery standpoint.
Let’s think about it from the practical angle. Assuming you need to query some row from Users table based on Name. If today Name is unique (and has unique constraint/index on it) it does not really matter what to use SET or SELECT. Although, what will happen with the code that uses SELECT if in one day, name stops to be unique? Obviously it introduces hard-to-find bugs/side effects – system just picks up one of the rows. Using SET in such case helps – code simply fails. Obviously it will require troubleshooting but at the end it will take much less time to pinpoint the problem. Of course, you can check @@RowCount (and it’s the only choice if you need to select/assign more than 1 variable as part of the query), but with 1 variable SET is more elegant (based on my opinion).
Same time, when I need to assign constants to the multiple variables, I prefer to use select. Less typing and probably a couple microseconds of performance improvement due less operators.
Code can be downloaded here
Let’s take a break from locking and blocking issues and talk about Ad-hoc sql. Everybody knows that it’s bad. Most popular horror story is security hole introduced by SQL Injection. There are a lot of articles available on such subject – just google it. But today I’d like to show another problem related with that implementation – recompilations and plan cache flood. Let’s take a look.
First, let’s create our favorite Data table and populate it with some data.
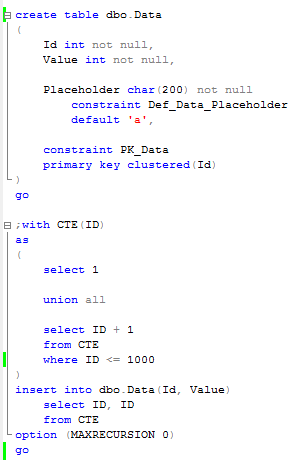
Second, let’s clear the plan cache and make sure that there are nothing there that accesses Data table.

As you see, clean and clear. Now let’s have some fun and introduce really bad client side code. This code basically runs 1000 ad-hoc selects against that table.
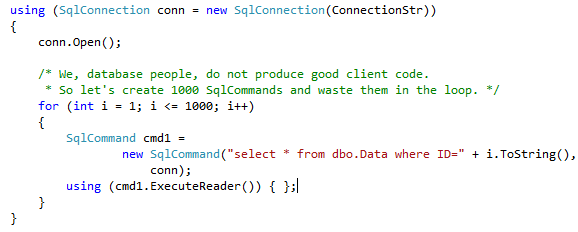
Let’s run it and query the plan cache again. As you can see, now we have 1000 cached plans.
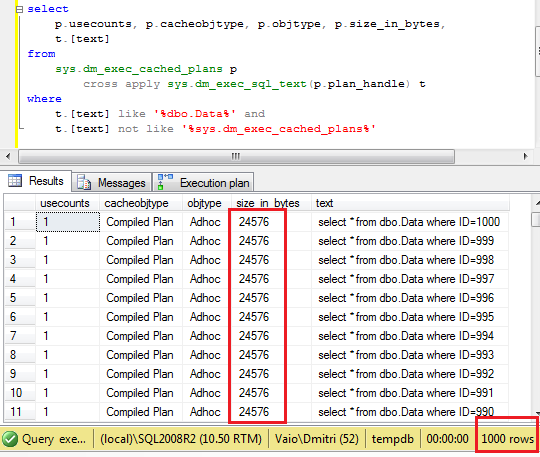
So let’s think about it for a minute – we forced SQL Server to compile 1000 different queries (which is quite expensive in terms of CPU usage), but besides that we just grab about 25MB of the server memory. Huh? Well, of course, those one-time-use plans would be removed from the cache rather sooner than later, but think what if you have the system that constantly runs those ad-hoc queries.. ?Alternatively, if we use parameters, you can see that there will be only 1 plan in the cache that was (re)used 1000 times. Don’t forget to clear cache before you run the second code snippet.

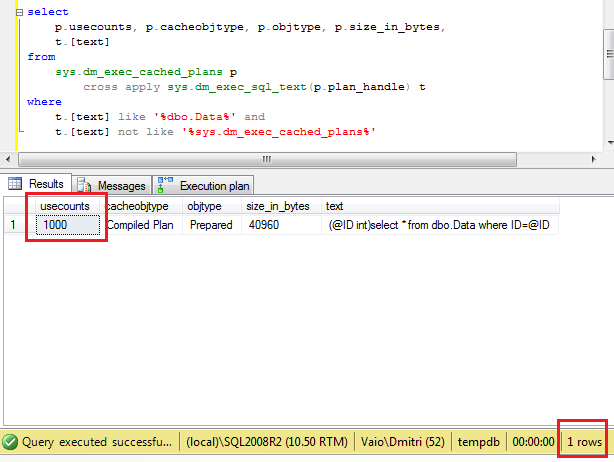
So what are the options if we cannot change the client code? First, of course, is forced parametrization. Although this is completely different can-of-worms and can introduce a lot of side effects related with parameter sniffing and bad plans. It deserves own blog post sometime later.
Another option is enable “Optimize for Ad hoc workloads” option. This is server side option that available in SQL Server 2008/2008R2 only. With this option enabled, SQL Server does not cache complete query plan at the first run – it generates plan stub (which is basically the small hash) instead. Next, when query runs the second time, SQL Server recompiles the query and replaces the stub with the actual plan. Let’s see that. First, let’s enable this option either in server properties window or via the script.
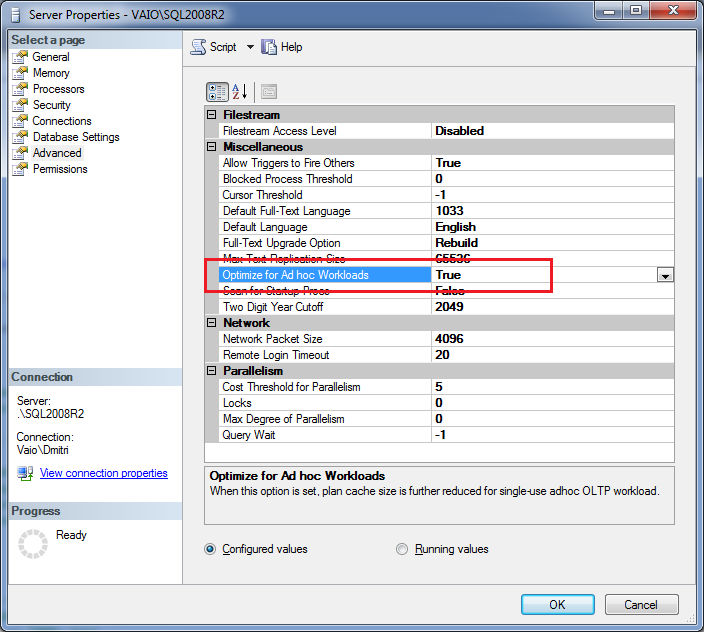

Next, let’s clear the cache and run the first code snipped again. As you can see, we still have 1000 objects in the plan cache, but each objects uses only 232 bytes. In case of complex queries/plans, the memory usage difference could be dramatic.

If you run it the second time, you’ll see that stubs were replaced with actual plans.
What are the downsides of this option? First of all, queries would be compiled twice. So it would introduce addition CPU load. Another issue that this is server-side option, so you cannot control it on the database level. In case if you have OLTP and Data-Warehouse databases hosted on the same server, that additional recompilation could be very expensive for the complex data-warehouse queries. But still, for OLTP and bad client code this option is usually useful.
Of course, the best advice is to get rid of ad-hoc sql at all!
Code is available for download
As we already saw, the reasons why we have blocking issues and deadlocks in the system are pretty much the same. They occur because of non-optimized queries. So, not surprisingly, troubleshooting techniques are very similar. Let’s have a quick look. We’ll use the same scripts I used last time.
The simplest approach is to use SQL Profiler. There is “Deadlock graph” event in the “Locks” event group you can use. Click on the picture to open it in the different window.
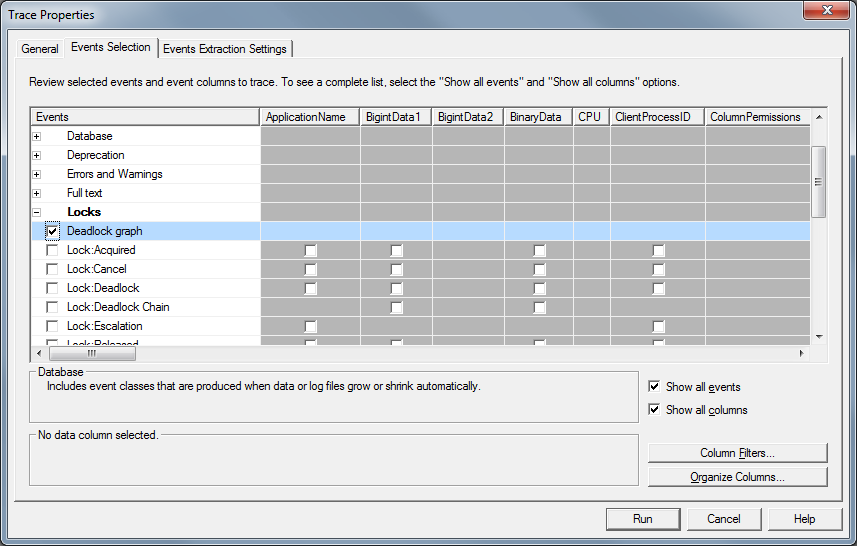
Let’s start the trace and trigger deadlock.
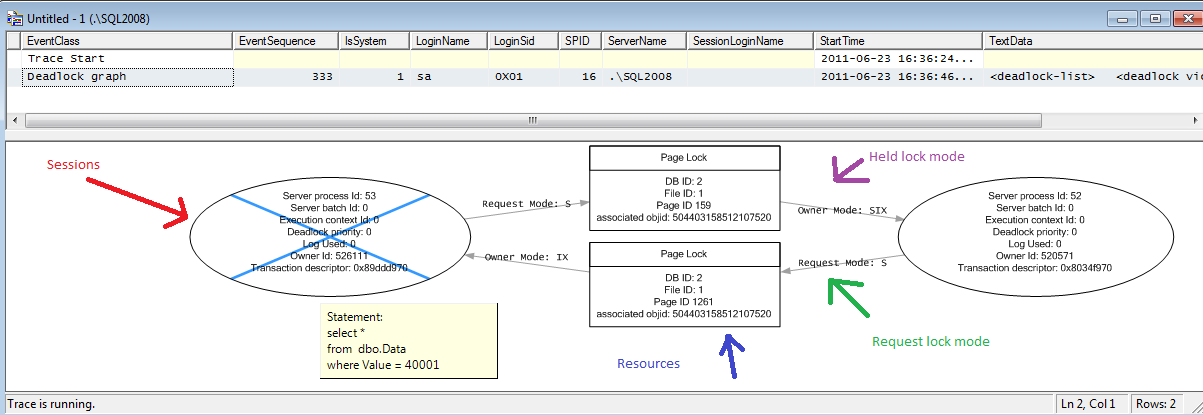
As you can see, it shows you very nice picture. There are 2 sessions (ovals) involved. Those sessions compete for the page locks (squares). You can see what locks each session held and you can even track it down to the resources (but that rarely needed). You can even see the statements when you move the mouse over the session oval and wait for the tool tip.
In context menu for “deadlock graph” line in the grid above, you have “Extract event data” menu command that can save this information as the file.
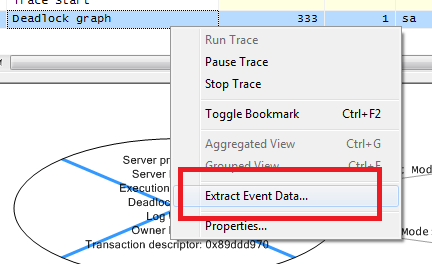
You can open it as the graph in management studio or, technically, simply look at XML which is extremely familiar:
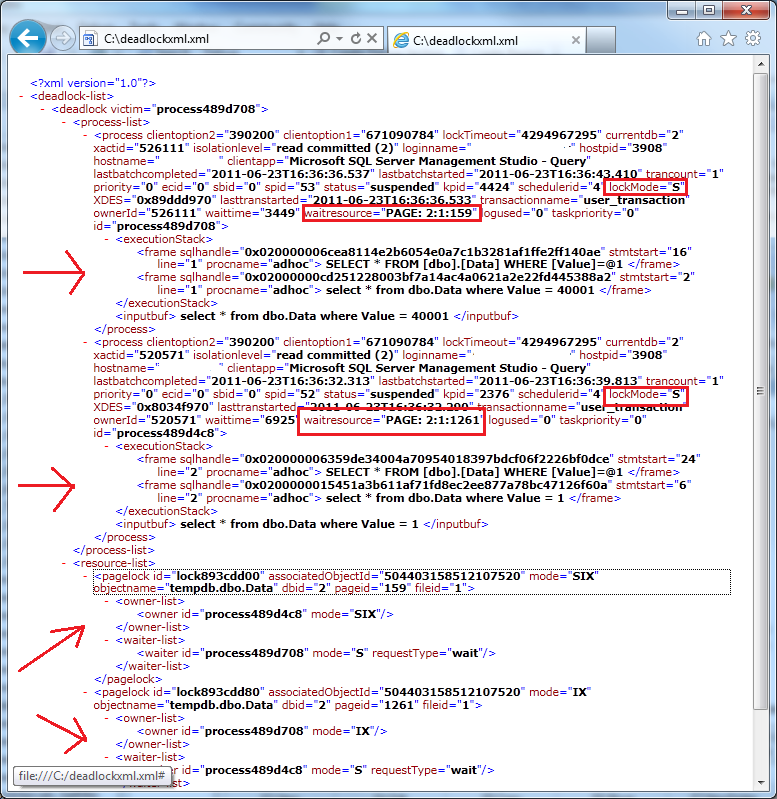
As you can see it’s way more detailed in compare with graphical representation. It’s also extremely familiar with blocking process report – and you can use same technique and query sys.dm_exec_sql_text if you need to obtain sql text from handle. I demonstrated how to do that in post related with blocking troubleshooting.
In case, if you don’t want to use SQL Profiler, there are 2 options you can use. The first one is enabling trace flag 1222 with DBCC TRACEON(1222,-1) command. When you have it enabled, SQL Server put deadlock graph XML to SQL Server log.
Another option is using extended events (SQL Server 2008/2008R2). Again, it’s very powerful method although requires some initial work to set it up. As with the blocking, I’m leaving it out of scope for now.
How to deal with deadlocks? Of course, the best thing is not to have deadlocks at the first place. Again, golden rule is to optimize the queries. Meanwhile, if you need to control (up to degree) what session will be terminated, you can use SET DEADLOCK PRIORITY option. There are 21 priority levels available. When 2 sessions deadlocked, the session with the lower deadlock priority level would be chosen as the victim. In case of the same priority level (default case), SQL Server chooses the session that is less expensive to rollback.
If session is chosen as the victim, it would be aborted with error code 1205. In such case client (or T-SQL code) can catch the exception and re-run the query. But again, the best way is avoiding deadlocks at the first place.
We already know why blocking occurs in the system and how to detect and troubleshoot the blocking issues. Today I’d like us to focus on the deadlocks.First, what is the deadlock? Classic deadlock occurs when 2 processes compete for the resources and waiting on each other. Let’s take a look on that. Click on each picture below to open them in the different window. Let’s assume that Orders table has the clustered index on ID column.Let we have the session 1 that starts transaction and updates the row from the Order table. We already know that Session 1 acquires X lock on this row (ID=1) and hold it till end of transaction
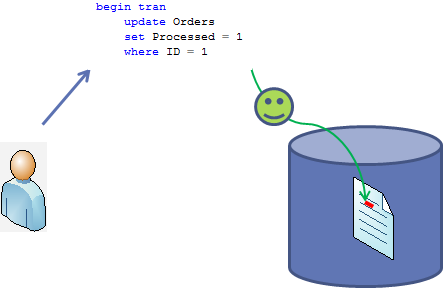
Now let’s start session 2 and have it update another row in the Orders table. Same situation – session acquires and holds X lock on the row with (ID = 2).

Now if session 1 tries to acquire X lock on the row with ID = 2 , it cannot do that because Session 2 already held X lock there. So, Session 1 is going to be blocked till Session 2 rollback or commit the transaction
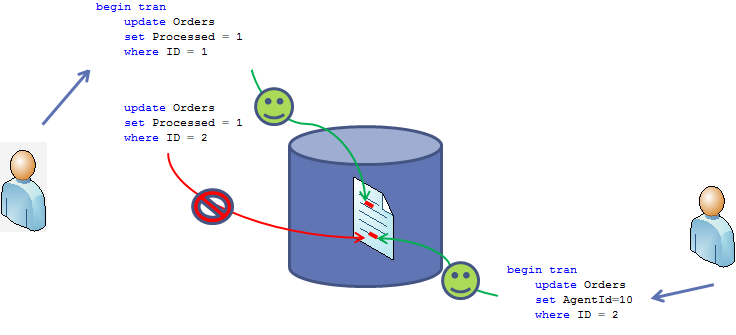
It worth to mention that it would happen in any transaction isolation level except SNAPSHOT that handles such conditions differently. So read uncommitted does not help with the deadlocks at all.

Simple enough. Unfortunately it rarely happens in the real life. Let’s see it in the small example using the same dbo.Data table like before. Let’s start 2 sessions and update 2 separate rows in the table (acquire X locks).Session 1:
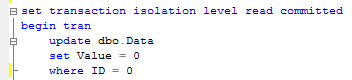
Session 2:
Now let’s run 2 selects.Session 1:

Session 2:

Well, as you can see, it introduces deadlock.

To understand why it happens, let’s take a look at the execution plan of the select statement:
As you can see – there is the table scan. So let’s think what happened
So this is the classic deadlock even if there are no data updates involved. It worth to mention that read uncommitted transaction isolation level would not introduce deadlock – readers in this isolation level do not acquire S locks. Although you’ll have deadlock in the case if you change select to update even in read uncommitted level. Otimistic isolation levels also behave differently and we will talk about it later.So as you can see, in the real life as other blocking issues deadlocks happen due non-optimized queries.
Next week we will talk how to detect and deal with deadlocks. Source code is available for download
As we already know, usually blocking happens due non-optimized queries. But how to detect queries that need to be optimized? Of course, in case of severe issues, we can analyze the queries that timeouts on the client side, but it gives us only the worst cases – with default settings it would show the queries that ran for more than 30 seconds.
So, what can we do? Keeping various monitoring software out of scope, there are 2 simple methods to do the troubleshooting. First one is Blocking Process Report and second one is DMV. Let’s start with the first one.
Blocking process report provides you nice XML with information about sessions involved in the blocking. But first, you have to set Blocked Process Threshold with the following commands:
EXECUTE sp_configure 'show advanced options', 1
GO
RECONFIGURE
GO
EXECUTE sp_configure 'blocked process threshold', 5 -- in seconds.
GO
RECONFIGURE
GO
EXECUTE sp_configure 'show advanced options', 0
GO
RECONFIGURE
GO
Of course, you should think what threshold you want to use and balance between a lot or very few events reported. I’d suggest to start with threshold of 5 seconds – if you have processes that are blocked for more than 5 seconds there is the good chance that deadlock monitor is constantly running. There are 2 things to keep in mind. First – SQL does the good job trying to monitor the blocking and generate blocked processes report, but it does not guarantee that it will do it all the time. E.g. it does the check when it has available resources to do so. Secondary, if you have process blocked for a long time, SQL generates report on every try. I.e. if you have threshold equal to 5 seconds, you will get the different reports for the same blocked condition after 5 seconds, 10 seconds and so on.
After you set that threshold, the next step is to run SQL Server Profiler and setup the trace with only 1 event: “Blocked process report”. You can do it in UI:

But the better way to run server side trace. You can export trace definition and run the script to do that.

I’m not going to focus on the details how to set it up – you can find information in Books Online. So let’s see what information that trace produces. Let’s run the blocking script from my previous post. In one session let’s run the update in uncommitted transaction (X lock on the row):

In another session let’s run select that introduces table scan:
![]()
Blocked process trace generates the report with following XML.

It has 2 elements: blocked-process and blocking-process. Simple case has just 2 processes involved but in real life it could be more complicated – Process A can block Process B and same time be blocked by Process C. That leads to the multiple events in the trace.
Let’s take a quick look at the details. First of all, you can see the status (red lines). Blocked process has the status of “Suspended”. Blocking process status is more interesting. “Sleeping” status indicates that process is waiting for the next command. Most likely it’s the sign of incorrect transaction handling on the client. Think about situation when client starts transaction when user opens the form, update data when user does some changes and commit or rollback it when user clicks on SAVE or CANCEL button.
Next, blocking report shows quite a few details about processes itself (Green lines). SPID, login, host, client app, etc. It also includes the information (Blue lines) about transaction isolation level, lock mode requested as well as point to resource that is locked. If you need, you can trace it down to specific row although I found that it’s rarely needed.
But most interesting are execution stacks and buffers (Pink blocks). For Ad-hoc sql you can see actual SQL involved in the locking. The situation is a little bit more complicated when stored procedures are involved. Let’s take a look. First, let’s create the simple procedure that replaces this update statement:
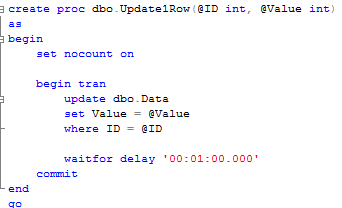
Next, let’s run this SP and select statement again. Make sure you commit or rollback transaction from the previous example first. Here is the blocking report:

As you can see in the blocking report, it does not show you what statement caused the blocking. In order to get it, you can use SQLHandle from the top statement in the execution stack and sys.dm_exec_sql_text data management function. Let’s see that:
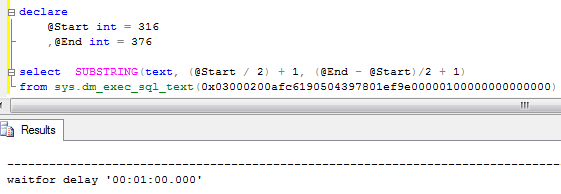
You can either count the line based on the trace value or find the actual statement based on offsets. It worth to mention that this could return different statement that the one that acquired the lock.
That method has one major drawback – statement needs to be in the cache in order at the time when you call sys.dm_exec_sql_text function. Alternative and better method to obtain blocked process report is using extended events (SQL Server 2008+). While it returns the same data, event is triggered at the time of the blocking, so you can analyze/query the system at the time of the blocking. But it’s far more complex to setup and out of the scope for now.
After you find the statements involved in the blocking, you can analyze while blocking occurs. As I mentioned before, the chance is that there are scans involved. You can use management studio and see execution plan there. Alternatively I found that those queries are quite often become one of the biggest IO consumers in the system, so you’ll see them if you analyze sys.dm_query_exec_stats data management view. You can use the script below. If query is there – just click on the plan and you’re all set.
SELECT TOP 50
SUBSTRING(qt.TEXT, (qs.statement_start_offset/2)+1,
((
CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.TEXT)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2)+1),
qp.query_plan,
qs.execution_count,
(qs.total_logical_reads + qs.total_logical_writes) / qs.execution_count as [Avg IO],
qs.total_logical_reads, qs.last_logical_reads,
qs.total_logical_writes, qs.last_logical_writes,
qs.total_worker_time,
qs.last_worker_time,
qs.total_elapsed_time/1000 total_elapsed_time_in_ms,
qs.last_elapsed_time/1000 last_elapsed_time_in_ms,
qs.last_execution_time
FROM
sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
ORDER BY
[Avg IO] DESC
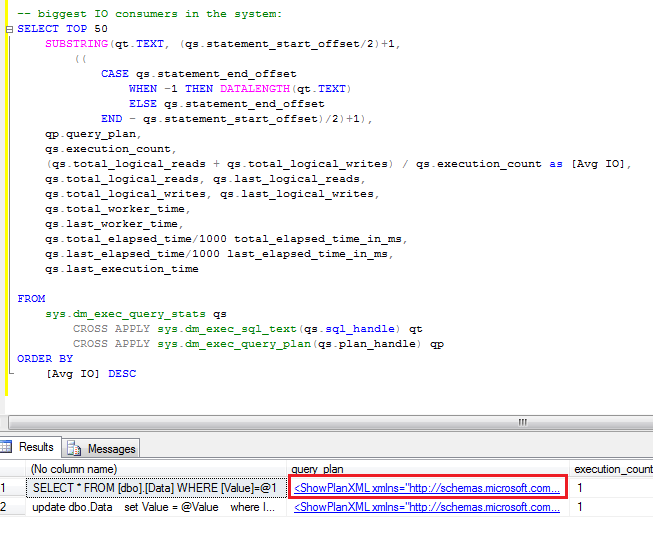
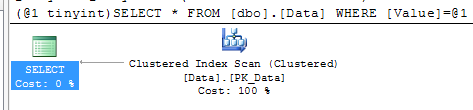
Blocking process report is extremely useful when you need to collect information about blocking. Although, if you need to look what happens in the system right now, you can use sys.dm_tran_locks data management view. I’ll show you 2 scripts below.
The first one gives you the list of the locks system has right now:
select
TL1.resource_type
,DB_NAME(TL1.resource_database_id) as [DB Name]
,CASE TL1.resource_type
WHEN 'OBJECT' THEN OBJECT_NAME(TL1.resource_associated_entity_id, TL1.resource_database_id)
WHEN 'DATABASE' THEN 'DB'
ELSE
CASE
WHEN TL1.resource_database_id = DB_ID()
THEN
(
select OBJECT_NAME(object_id, TL1.resource_database_id)
from sys.partitions
where hobt_id = TL1.resource_associated_entity_id
)
ELSE
'(Run under DB context)'
END
END as ObjectName
,TL1.resource_description
,TL1.request_session_id
,TL1.request_mode
,TL1.request_status
,WT.wait_duration_ms as [Wait Duration (ms)]
,(
select
SUBSTRING(
S.Text,
(ER.statement_start_offset / 2) + 1,
((
CASE
ER.statement_end_offset
WHEN -1
THEN DATALENGTH(S.text)
ELSE ER.statement_end_offset
END - ER.statement_start_offset) / 2) + 1)
from
sys.dm_exec_requests ER
cross apply sys.dm_exec_sql_text(ER.sql_handle) S
where
TL1.request_session_id = ER.session_id
) as [Query]
from
sys.dm_tran_locks as TL1 left outer join sys.dm_os_waiting_tasks WT on
TL1.lock_owner_address = WT.resource_address and TL1.request_status = 'WAIT'
where
TL1.request_session_id <> @@SPID
order by
TL1.request_session_id

The second one is slightly modified version that shows you only blocking and blocked processes.
/*
Shows blocked and blocking processes. Even if it works across all database, ObjectName
populates for current database only. Could be modified with dynamic SQL if needed
Be careful with Query text for BLOCKING session. This represents currently active
request for this specific session id which could be different than query which produced locks
It also could be NULL if there are no active requests for this session
*/
select
TL1.resource_type
,DB_NAME(TL1.resource_database_id) as [DB Name]
,CASE TL1.resource_type
WHEN 'OBJECT' THEN OBJECT_NAME(TL1.resource_associated_entity_id, TL1.resource_database_id)
WHEN 'DATABASE' THEN 'DB'
ELSE
CASE
WHEN TL1.resource_database_id = DB_ID()
THEN
(
select OBJECT_NAME(object_id, TL1.resource_database_id)
from sys.partitions
where hobt_id = TL1.resource_associated_entity_id
)
ELSE
'(Run under DB context)'
END
END as ObjectName
,TL1.resource_description
,TL1.request_session_id
,TL1.request_mode
,TL1.request_status
,WT.wait_duration_ms as [Wait Duration (ms)]
,(
select
SUBSTRING(
S.Text,
(ER.statement_start_offset / 2) + 1,
((
CASE
ER.statement_end_offset
WHEN -1
THEN DATALENGTH(S.text)
ELSE ER.statement_end_offset
END - ER.statement_start_offset) / 2) + 1)
from
sys.dm_exec_requests ER
cross apply sys.dm_exec_sql_text(ER.sql_handle) S
where
TL1.request_session_id = ER.session_id
) as [Query]
from
sys.dm_tran_locks as TL1 join sys.dm_tran_locks TL2 on
TL1.resource_associated_entity_id = TL2.resource_associated_entity_id
left outer join sys.dm_os_waiting_tasks WT on
TL1.lock_owner_address = WT.resource_address and TL1.request_status = 'WAIT'
where
TL1.request_status <> TL2.request_status and
(
TL1.resource_description = TL2.resource_description OR
(TL1.resource_description is null and TL2.resource_description is null)
)

So those are 2 techniques that can help you with the troubleshooting. Again, I think it’s not as powerful as extended events approach but same time those are much simpler to accomplish.
Source code is available for download
Also check Part 16: Monitoring Blocked Processes with Event Notifications that shows how to automate the process.
We already know what are the most important lock types and how transaction isolation levels affect locking behavior. Enough theory – today I’d like to show you simple example why blocking typically occurs in the system.
First, let’s create the table and populate it with the data.
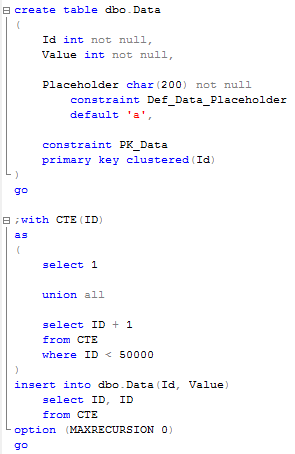
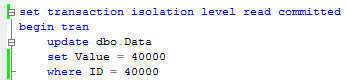
As you can see, this table has 50,000 rows now and 1 clustered index on ID column. Now let’s start another session and run update statement that acquires the lock (update row with ID = Value = 40000). I’m using read committed isolation level but that behavior occurs in any pessimistic isolation level (read uncommitted, read committed, repeatable read and serializable).
Next, let’s take a look at the list of the locks in the system with sys.dm_tran_locks DMV. I don’t have any other activity in the system but in your case, you can filter results by request_session_id if needed.


So we can see 3 active locks: exclusive lock on key (row) level and 2 intent-exclusive locks on the page and table levels.
Now let’s open another session and run select with filter on ID column in the read committed isolation level (you’ll experience the same behavior in repeatable read and serializable isolation levels). This select executes just fine with clustered index seek in the plan.


Now let’s change select and replace filter on ID column with filter on Value column. This select should return the same 1 row but it you run it, it would be blocked.
![]()
If we query sys.dm_tran_locks again, we can see that the second session is waiting to acquire shared lock.

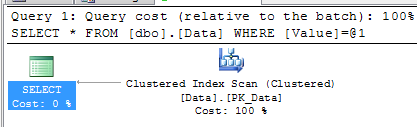
Let’s terminate the select and take a look at estimated execution plan.

As you can see, the plan changes to clustered index scan. We know that this select returns only 1 row from the table but in order to process the request, SQL Server has to read every row from the table. When it tries to read updated row that held exclusive lock, the process would be blocked (S lock is incompatible with X/IX locks). That’s it – blocking occurs not because multiple sessions are trying to update the same data, but because of non-optimized query that needs to process/acquire lock on the data it does not really need.
Now let’s try to run the same select in read uncommitted mode.

As you can see – select runs just fine even with scan. As I already mentioned, in read uncommitted mode, readers don’t acquire shared locks. But let’s run update statement.
![]()
It would be blocked. If you take a look at the lock list, you’ll see that there is the wait on update lock (SQL Server acquires update locks when searches for the data for update)

And this is the typical source of confusions – read uncommitted mode does not eliminate blocking – shared locks are not acquired, but update and exclusive locks are still in the game. So if you downgraded transaction isolation level to read uncommitted, you would not completely solve the blocking issues. In addition to that, you would introduce the bunch of consistency issues. The right way to achieve the goal is to illuminate the source of the problem – non-optimized queries.
Next time we will talk how to detect such queries.
Source code is available here
You can download it from the Presentations page. Thank you very much for attending!