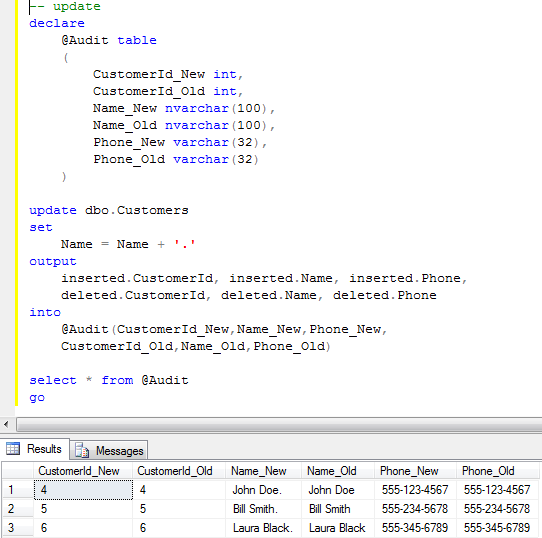
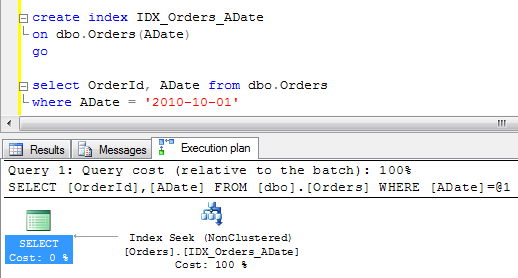
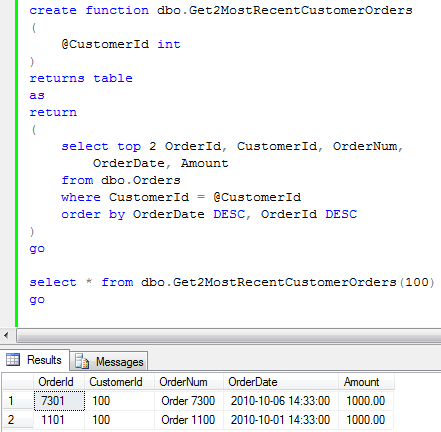
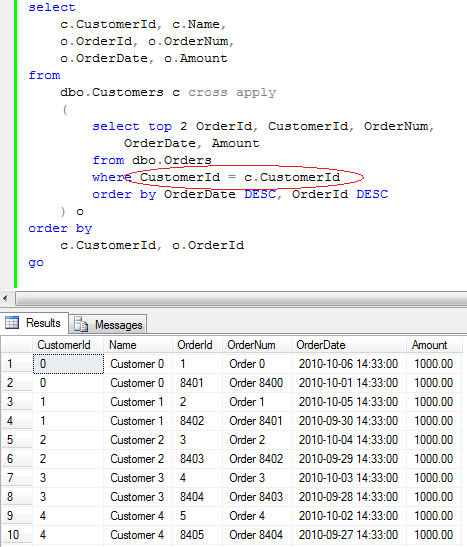
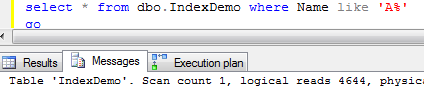
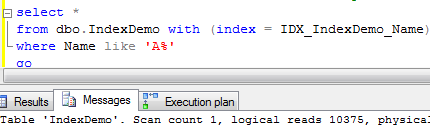
Ok, enough about tables for now. Let’s talk about indexes. As all of us know, there are 2 types of the indexes in SQL Server:
1st – Clustered indexes. This is one index per table and basically specifies the order how data is stored in the table. For example, if the table has the clustered key index on the integer field, it means data will be actually sorted by that integer field. Please don’t be confused – there is still no such thing like default sorting order for the queries – the order of the rows SQL Server returns would depend on the execution plan which could be different than clustered index scan.
SQL Server does not require you to create the clustered indexes – tables without such indexes called heap tables. We will talk about such tables later.
2nd type of the indexes are non-clustered indexes. SQL Server allows to have up to 249 non-clustered indexes per table in SQL 2005 and 999 non-clustered indexes in SQL 2008 (thanks to Chirag for pointing this out). This is “just an index”.
If you think about the book, page number is the clustered index. Alphabetical annotation at the end of the book – is the non-clustered index.
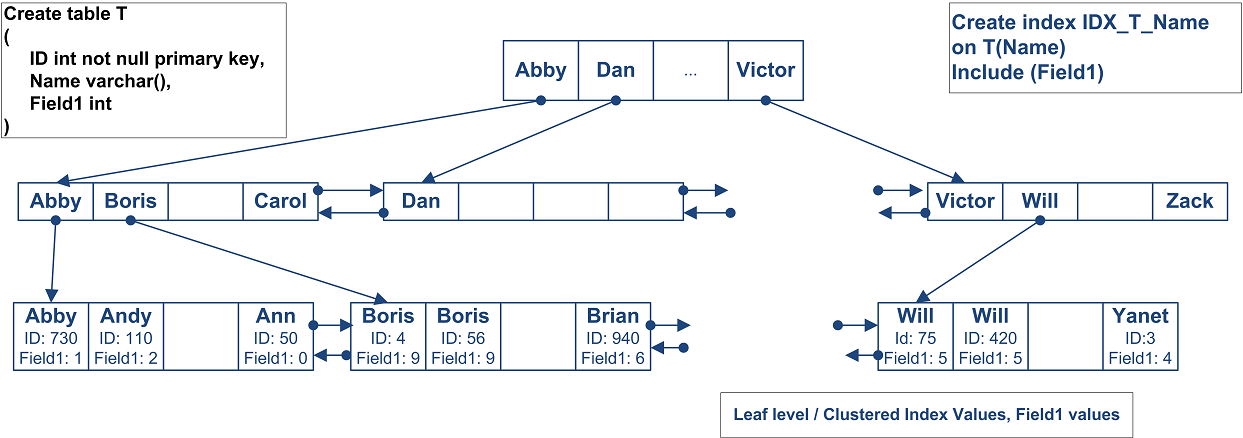
So what exactly is the index? This is B-tree. Let’s see what is that.

The image above shows a small table with ID as the primary key (and clustered index). As the side note, SQL Server creates clustered index on the primary key field by default.
Leaf level (the bottom one) contains actual table data sorted by ID. As you can see, the data pages are linked into the double-linked list so SQL Server can scan the index in both directions.
Levels above the leaf level called “intermediate levels”. Every index row on those levels points to the separate data pages in the level below. At the top level (root level) there is only one page. There could be several intermedite levels based on the table size. But the top root level of the index always has 1 data page.
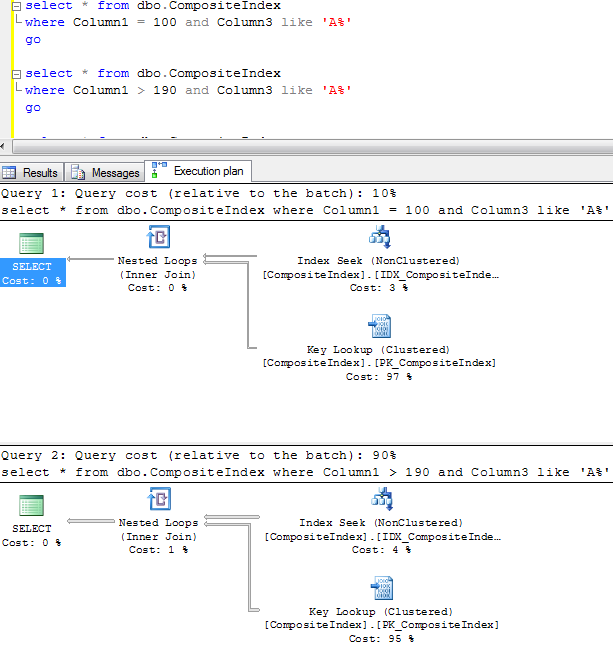
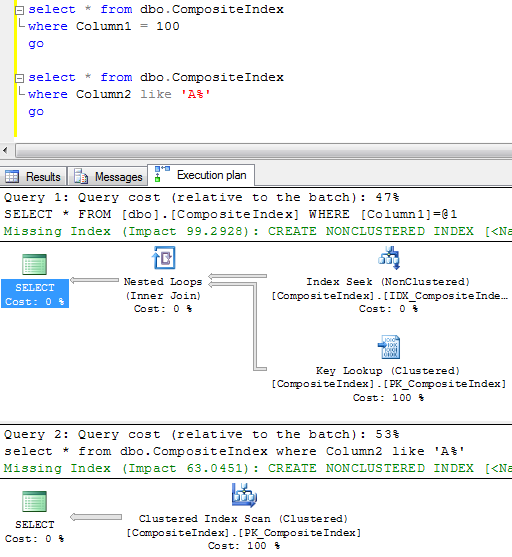
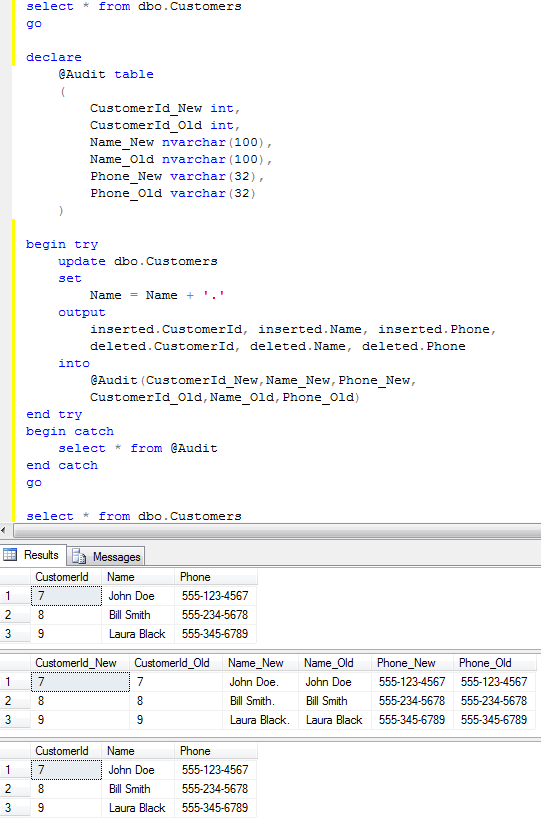
So let’s see how it actually works: Assuming you want to select the record with ID = 50. SQL Server start from the root level and find that first row contains ID=1 and the second row contains ID=57. It means that the row with ID=50 would be located on the data page started with ID=1 on the next level of the index. So the next step is analyzing the first data page on the intermediate level which contains IDs from 1 to 50. So SQL Server finds the row with ID=50 and jump on the leaf level page with the actual data.
Now let’s look at the non-clustered index. Assuming we have the index by Name field.

The structure of the index is exactly the same with the exception that leaf level does not contain table data but values for the clustered index. It does not really matter if you specify ID in the index definition, it would be there. For the heap tables, leaf level contains actual RID – Row id which consists of FileId:PageNumber:RowNumber. Annotation at the end of the book is a good example. It does not include the actual paragraph from the book but the page # (clustered index)
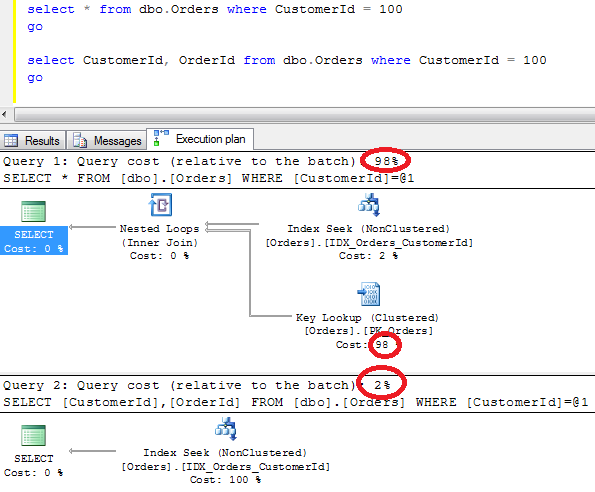
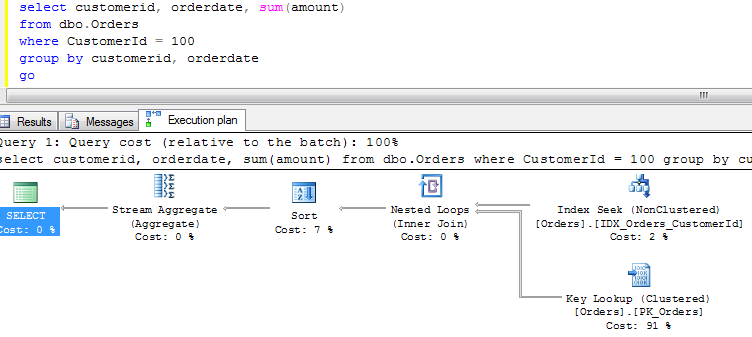
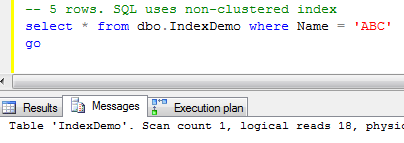
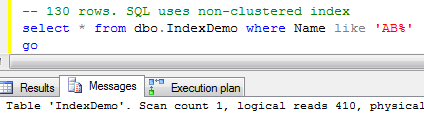
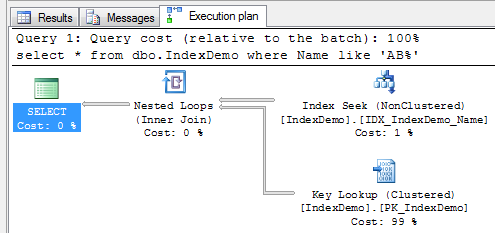
Let’s see how SQL Server works when it uses non-clustered index for the lookups on the tables with clustered index. As you can see, first it needs to find ID of the row(s) and next perform clustered index lookup in order to obtain the actual table data. This operation called “Key lookup” or “Bookmark lookup” on the previous editions of SQL Server.
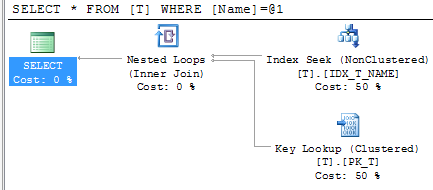
2 things I would like us to remember:
1. Non clustered index has the value of the clustered index on the leaf level
2. As result when SQL Server use non-clustered index for lookup, it needs to traverse clustered index to get the value for the actual data row.
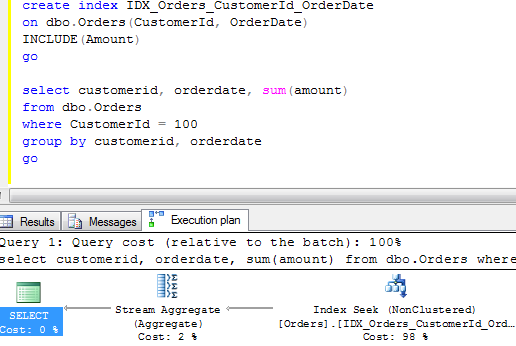
This introduce interesting performance implications we will talk about next time.