We already know the structure of the clustered and non-clustered indexes. We also know what is the main criteria for SQL Server to use non-clustered index.
Today I want to talk about covering indexes technique. Let’s start with the definition.
Covering index for the query is the index that has all required values in the index leaf rows and as result does not require key/bookmark lookup of the actual table data.
Let’s see the example. First of all, let’s create the table and populate it with some data

Now let’s try to run 2 selects – one that return all columns for the customer with id = 100 and second one that returns customerid and orderid only.
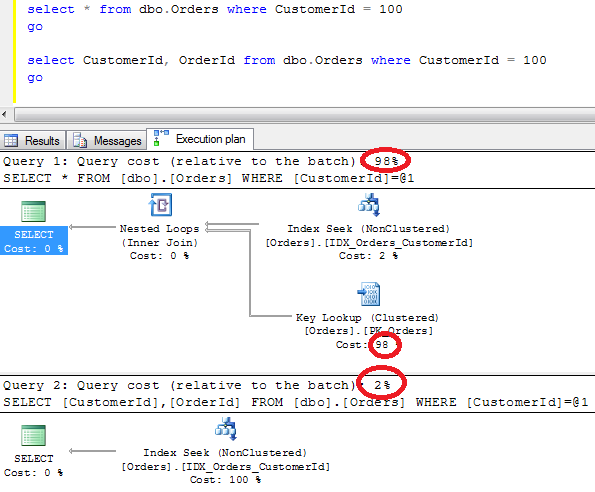
As you can see, the first select produces the plan with index seek and key lookup. The second one does not do the key lookup at all. Remember, non-clustered index has the values from the clustered index in the rows so OrderId is there. No needs for the key lookup.
2 Other things I would like to mention. First, you can see that cost of key lookup is 98% of the cost of the first select. Another thing that second select is about 50 times less expensive than the first one.
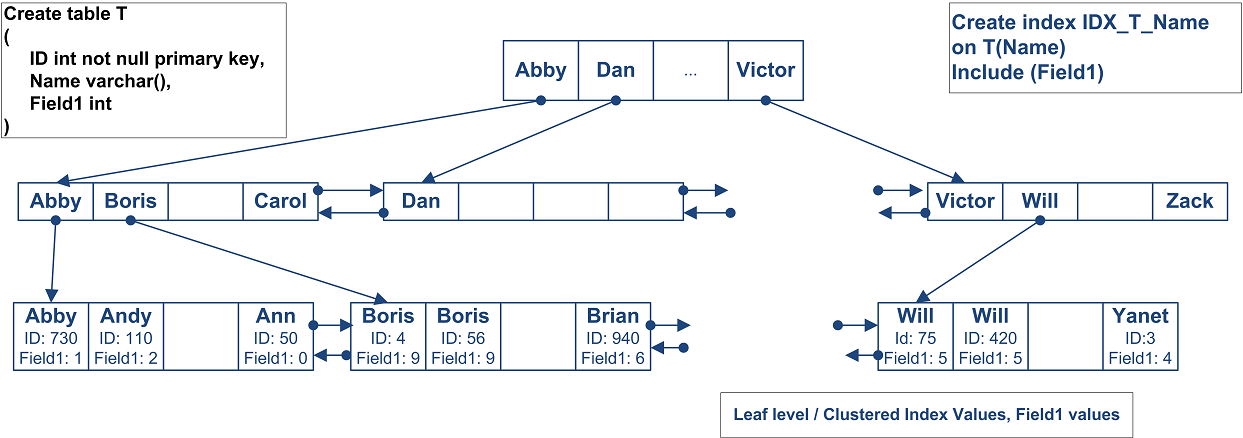
What should we do if our typical select requires to get a total amount of the orders placed by the customer grouped by date. Obviously we’re filtering (or grouping) by customerid and date in such case. We don’t really need to have amount as additional column in the index because we’re not using it in the predicated. Fortunately SQL Server has a way to add other columns and store it in the index leaf. You can do it with INCLUDE cause of the CREATE INDEX statement.
Below is the picture which show the structure of this index (on some of abstract tables). Click here to open it in the new window.
Let’s check how it works in the example with the orders table:
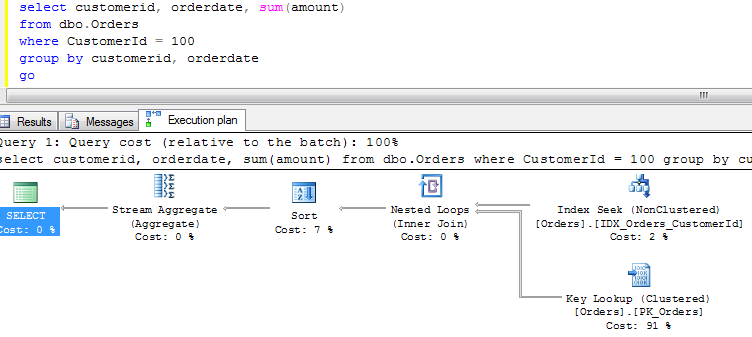

Plan is index seek, key lookup and next grouping. As you can see it produces 114 logical reads.
Now let’s create the index and run select one more time.
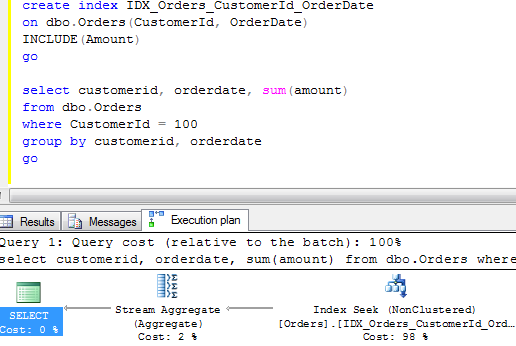
![]()
Simple index seek with 2 reads. Great improvement.
Last example I want to show you – let’s try to select max order amount.

As you can see in the first plan – it uses non-clustered index scan. SQL Server cannot use that index for seek operation – but it can scan the index. Because index leaf size is smaller than clustered index row size, it’s more efficient. Look at io statistics
![]()
This is one of the easiest optimization techniques you can use in the system – illuminating key lookup with the covering index.
One warning though – extra included columns in the index increase the leaf size, so index will require more pages and be less efficient. So don’t make it extremely wide.
You can download the code from here