Both operations utilize the indexes. But what is the difference?
Scan operator (on clustered or non-clustered indexes) scans entire index – all data pages and all rows and applies the predicate on every row.
Seek operator “process” only subset of the rows in the index (0..N) – only rows that qualifies.
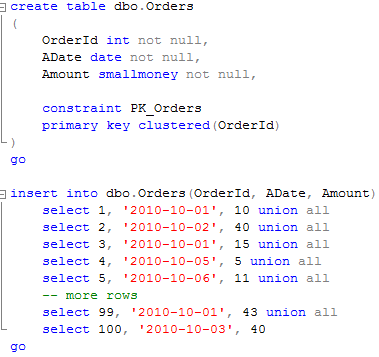
Assume you have a table:
Now let’s run the select.
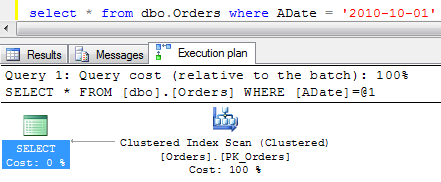
As you see, it shows clustered index scan. You can think about that in the following way:

Now let’s create the index on ADate column.
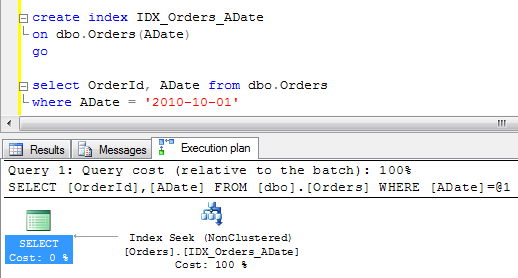
Seek operation does not require to process entire index (rows there are sorted already), so SQL Server finds the first row with ADate = ‘2010-10-01’ and processes the rows until ADate reaches ‘2010-10-02’ and stops.

Obviously index seek operation is much more efficient. But not all predicates are Seekable. What is seekable:
ADate = '2010-10-01'
ADate < '2010-10-02'
ADate between '2010-10-01' and '2010-10-05'
OrderId in (1,3,5)
VarcharField like 'A%'
Basically predicate is seekable if Query Optimizer can map it to the subset of the rows in the index.
Now let’s think about opposite example:
Abs(OrderId) = 1 – Non-seekable predicate. Fortunately you can convert it to: OrderId in (-1, 1)
OrderId + 1 = 10 – Can be converted to: OrderId = 9
DateAdd(day,7,OrderDate) > GetDate() – Can be converted to: OrderDate > DateAdd(day,-7.GetDate())
datepart(year,OrderDate) = 2010 – Can be converted to: OrderDate between '2010-01-01' and '2010-12-31'
VarcharField like '%A%' – here you’re out of luck.
So as you see, functions, calculations on the column makes predicate non-seekable. Avoid that if possible
You can download the code from here