As you know, SQL Server uses range locks to protect the range of the index keys. This usually happens in SERIALIZABLE isolation level. This level prevents phantom and non-repeatable reads phenomena and it guarantees that queries executed in transaction will always obtain the same set of data every time they were executed.
As the simple example, consider the table with ID column and two rows with ID = 1 and ID = 10. In SERIALIZABLE isolation level, the query that selects data from the table should always obtain those and only those two rows if you run it multiple times. SQL Server uses shared range lock protecting ID key range interval of (1..10), which guarantees that other transactions would not be able to update or delete existing rows nor insert any new rows into the interval.
In contrast, REPEATABLE READ isolation level uses row locks rather than range locks. They would prevent modifications of existing rows- 1 and 10- but would not prevent other transactions from inserting rows into the interval and introducing phantom read phenomena.
The range locks are usually acquired only in SERIALIZABLE isolation level; however, there is another, pretty much undocumented case, when SQL Server can use those locks. It happens even in READ UNCOMMITTED and READ COMMITTED SNAPSHOT modes when you have nonclustered indexes that have IGNORE_DUP_KEY=ON option. In that case rows with the duplicated index keys would not raise an error but rather being ignored. SQL Server would not insert then into the table.
This behavior leads to very hard to explain cases of blocking and even deadlocks in the system. Let’s look at the example and create the table with a few rows as shown below. As you see, nonclustered index on the table has IGNORE_DUP_KEY option enabled.
create table dbo.IgnoreDupKeysDeadlock
(
CICol int not null,
NCICol int not null
);
create unique clustered index IDX_IgnoreDupKeysDeadlock_CICol
on dbo.IgnoreDupKeysDeadlock(CICol);
create unique nonclustered index IDX_IgnoreDupKeysDeadlock_NCICol
on dbo.IgnoreDupKeysDeadlock(NCICol)
with (ignore_dup_key = on);
insert into dbo.IgnoreDupKeysDeadlock(CICol, NCICol)
values(0,0),(5,5),(10,10),(20,20);
Now let’s start transaction in READ UNCOMMITTED mode and insert the row into the table checking the locks session acquired.
set transaction isolation level read uncommitted
begin tran
insert into dbo.IgnoreDupKeysDeadlock(CICol,NCICol) values(1,1);
select request_session_id, resource_type, resource_description
,resource_associated_entity_id, request_mode, request_type, request_status
from sys.dm_tran_locks
where request_session_id = @SPID;
As you can see in Figure 1, INSERT statement acquired and held two exclusive (X) locks on the rows inserted into clustered and nonclustered indexes. It also obtained Range (RangeS-U) lock on nonclustered index. RangeS-U means that the key range is protected with the shared (S) lock and SQL Server uses update (U) scan within the range.

01. Locks Held by the Session
You may ask the obvious question – why the range lock is required? The reason is the way how SQL Server handles modifications of the data. The data is always inserted into or updated in the clustered index first followed by nonclustered index updates. With IGNORE_DUP_KEY=ON, SQL Server should prevent the situation when the duplicated keys were inserted into nonclustered index simultaneously after clustered index insert was done and, therefore, clustered index insert needs to be rolled back. Thus, it locks nonclustered index key range before any data modifications preventing other sessions from inserting any rows there.
You can confirm it by looking at lock_acquired xEvent events as it is show in Figure 2. As you can see, the RangeS-U lock is acquired before exclusive (X) locks on the resources.
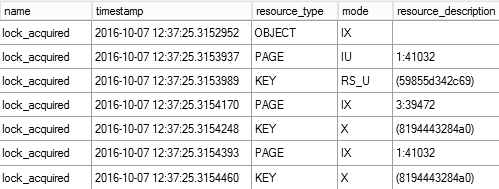
02. lock_acquired Events During Insert
The key problem here, however, is that RangeS-U lock behaves the same way as in SERIALIZABLE isolation level and it is held until the end of transaction. Moreover, RangeS-U locks are incompatible with each other. That can lead to very unpleasant and hard to understand deadlocks.
Let’s run the code shown below in another session. The first INSERT would succeed (it is in the different key range in the index). The second, however, would be blocked due to RangeS-U/RangeS-U lock incompatibility.
set transaction isolation level read uncommitted
begin tran
-- Succeed
insert into dbo.IgnoreDupKeysDeadlock(CICol,NCICol) values(12,12);
-- Blocked
insert into dbo.IgnoreDupKeysDeadlock(CICol,NCICol) values(2,2);
commit
If we checked the locks held by the both sessions now, we would see the picture shown in Figure 3. You can see that session 2 successfully acquired the first range lock but the second range lock request is blocked due to incompatible range lock on the same key interval held by the session 1.
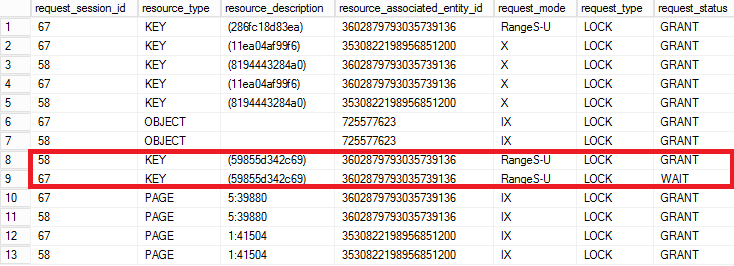
03. Locks Held by Both Sessions
Finally, if we run another INSERT in the session 1 into the range locked by the session 2, it would be also blocked with the typical deadlock condition.
insert into dbo.IgnoreDupKeysDeadlock(CICol,NCICol) values(11,11); commit
Figure 4 shows you the deadlock graph.

04. Deadlock Graph
Unfortunately, there is very little you can do about that. The only way to address the problem is removing IGNORE_DUP_KEY option from the index handling duplicates in the different ways. It may or may not work for you.
Finally, it is worth mentioning, that SQL Server does not use range locks in case of clustered indexes with IGNORE_DUP_KEY=ON option. Clustered indexes are modified first and SQL Server could detect duplicated keys at this stage without any extra range locking required.
Source code is available for download.