We did not talk much about schema locks while back when we were discussing locking. Those locks are a little bit different than other locks – they are acquired on objects (and metadata) level and protecting the metadata. Think about it from the following prospective – you don’t want to have 2 sessions altering the table simultaneously. And you don’t want the table being dropped when you are selecting data from there.
There are 2 types of schema locks. SCH-S – schema stability locks. Those locks are kind of “shared” locks and acquired by DML statements and held for duration of the statement. They are compatible with each other and with other lock types (S, U, X, I*). The caveat is that those locks acquired regardless of transaction isolation level – so you’d have those locks even when your queries are running in read uncommitted or snapshot isolation levels. Let’s take a look.
First, let’s create the table and populate it with some data. You, perhaps, need to adjust number of rows in the table based on your hardware.
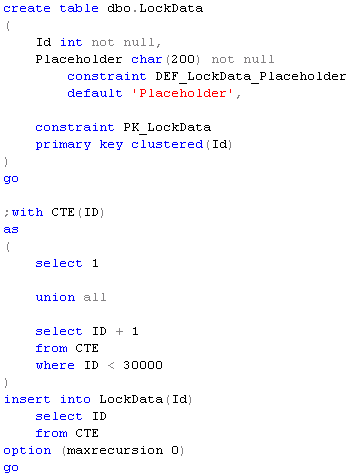
Second, let’s run long-running select in read uncommitted mode (I even use NOLOCK hint to make it a little bit more “visible”).

And while it’s running, let’s run the statement that shows currently acquired locks (click on the image to open it in the new window). That statement is basically using sys.dm_tran_locks DMV – I just added a few other things to make it easier to see/understand. You can get it in the script file (see the link below).

And here are the results:

As you can see, even if statement uses READ UNCOMMITTED transaction isolation level, we still have SCH-S acquired.
Second type of the lock is schema modification lock – SCH-M. This lock type is acquired by sessions that are altering the metadata and live for duration of transaction. This lock can be described as super-exclusive lock and it’s incompatible with any other lock types including intent locks. Let’s take a look. Let’s run the previous select again and in another session let’s try to alter the table – add new column.
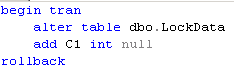
Even if adding nullable column is pure metadata operation, as we can see below it’s blocked.

I’m pretty sure you saw that behavior when you tried to update metadata in production on the live system 🙂 And interesting thing, that while you have SCH-M lock waiting, you can easily get other SCH-S locks acquired on the same object without any problems. Let’s take a look – again, let’s run first select, next alter table statement, and finally run the third select (I renamed CTE to CTE2 here):


As you see, there are 2 granted SCH-S locks and one SCH-M lock request waiting for both sessions. This is a reason why your DDL statement can wait for quite a long time on the system under heavy load.
The biggest possible issue with schema modification lock is that it’s incompatible even with intent locks. Let’s take a look – same scenario as before, but let’s run INSERT statement in the third session.
![]()
And let’s check the locks.

Insert statement is trying to place intent lock (IX) on the table and it’s incompatible with SCH-M lock. So insert is blocked. Kind of interesting situation when select in read uncommitted isolation level blocks insert. And if we think about it, there are more operations counted as metadata modifications than we think. For example, index rebuild would do exactly the same thing. And of course partitioning related operation.
If we think about SCH-M locks, they are acquired on the object level – deadlock possibilities are endless. And unfortunately, that’s extremely annoying when you’re dealing with operations related to table partitioning. Well, there is no easy way to solve that problem – good error handling could help though. I will show some examples shortly.
Source code is available for download
Next: Deadlocks during DDL operations (alteration, partition switch, etc)
Enjoyed the article.
What do you think of this:
I need to rebuild the PK index on one partition in the “middle” of partitioned table with DATA_COMPRESSION-PAGE. During REBUILD the whole table becomes unavailable due to SCH-M lock. Would it help to switch the partition out, rebuild it while it’s not part of the table and switch it back afterwards?
Thanks a lot!
Hi Alex,
Yes, it would work – see script below. You’ll still need to rebuild partition in the original table after switch to match compression settings, but it should be quick operation because it would be empty. Switching partition would also require SCH-M lock although it would be the metadata operation.
The problem, of course, is that part of your data would be unavailable while it is in the different table. If this is an issue, you can consider to create partitioned view for the time of rebuild or, if data is read-only, copy data to another table rather than switching partition at the beginning.
Sincerely,
Dmitri
use tempdb
go
create partition function pfData(date) as range right for values(‘2013-02-01′,’2013-03-01’);
create partition scheme psData as partition pfData all to ([primary]);
create table dbo.Data
(
ADate date not null,
Placeholder char(100),
constraint PK_Data
primary key clustered(ADate)
on psData(ADate)
)
go
insert into dbo.data(ADate) values(‘2013-01-01’), (‘2013-02-15’), (‘2013-03-15’);
go
create table dbo.DataTmp
(
ADate date not null,
Placeholder char(100),
constraint PK_DataTmp
primary key clustered(ADate),
constraint CHK_DataTmp
check(ADate >= ‘2013-02-01’ and ADate < '2013-03-01') ) go alter table dbo.data switch partition 2 to dbo.DataTmp go alter index PK_DataTmp on dbo.DataTmp rebuild with (data_compression = page) go alter partition scheme psData next used [primary] go alter index PK_Data on dbo.data rebuild partition = 2 with (data_compression = page) go alter table dbo.dataTmp switch to dbo.data partition 2 go select * from dbo.data go select p.partition_number ,p.data_compression_desc ,object_name(object_id) as Name ,filegroup_name(data_space_id) as FileGroup ,type_desc from sys.partitions p join sys.allocation_units a on p.partition_id = a.container_id where object_id = object_id('dbo.Data') order by p.partition_number
Great article!
Important thing to note:
The behaviour that SCH-S locks get granted even if a SCH-M lock is waiting was changed after Sql Server 2008 R2. As of Sql Server 2012, SCH-S will be blocked by the waiting SCH-M request.
See also here: http://dba.stackexchange.com/questions/73833/sch-m-wait-blocks-sch-s-in-sql-server-2014-but-not-sql-server-2008-r2
Thank you, Fabian! It is definitely the great thing to note. Completely forgot about it.
Also, need to write/add link about low priority locks in SQL Server 2014, which can reduce blocking in partition table-related scenarios.
Again, thank you for pointing it out.
Sincerely,
Dmitri
Pingback: Thanks for the Help with Deadlocks | Oh Yeah
I understand that SCH-S are “compatible” with all other locks except SCH-M.
The Lock Matrix in BOL says that the combination SCH-S and Rangexxx locks are “Illegal”.
What does this mean? Does it mean the condition cannot occur? Or does it mean there is some sort of blocking/waiting ?
Hi Ray,
It means that this condition cannot occur. Schema locks are acquired on object(table) level. Range locks are row-level locks.
Sincerely,
Dmitri
What I’d like to know is why the first query with the NOLOCKs is issuing a SCH-S lock. It’s just a read, right? No DML is being used. Am I missing something?
SCH-S is schema stability lock. It’s preventing other sessions from modifying the tables schema or dropping the tables during the query execution. It is compatible with any data-related locks and incompatible only with SCH-M schema modification locks used during schema alteration.