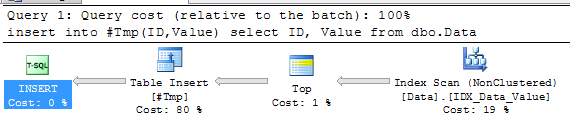
There was some time since we discussed locking and blocking in Microsoft SQL Server. One big area we did not cover is optimistic transaction isolation levels. So what exactly are those?
As you remember, standard “pessimistic” isolation levels – read uncommitted, read committed and repeatable read – all of them can have anomalies. Dirty and non-repeatable reads, ghost rows and duplicated reads. Higher isolation levels reduce anomalies in price of reduced concurrency. Most restrictive – Serializable isolation level guarantees no anomalies although with such level concurrency greatly suffers. Before SQL Server 2005 it was virtually impossible to have consistent reporting in the systems with heavy reading and writing activities.
Obviously in quite competitive market Microsoft had to do something to solve that problem. As the result, one of the features Microsoft introduced in SQL Server 2005 was new “optimistic” transaction isolation levels. With those isolation levels readers use row versions rather than locking. When you start the transaction and modify some rows, old version of the rows are copied to the version store in tempdb. Actual row holds 14 bytes pointer to the version store.
There are 2 different isolation levels – well, actually one and half. First one is called Read Committed Snapshot and not really the level but more or less the mode of Read Committed. This level implements statement level consistency – readers would not be blocked by writers but in transaction scope it could have same anomalies as regular read committed (with the exception of duplicated reads). Let’s take a look. If you don’t have test database, create it first. First, let’s enable read committed snapshot isolation level. It worth to mention that when you switch the mode, you should not have any users connected to the database.

Next, let’s create the table and populate it with some data

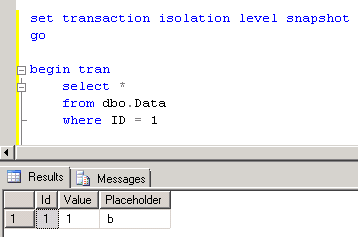
Now let’s start one session and update one of the rows. As you can see, this session starts in read committed isolation level
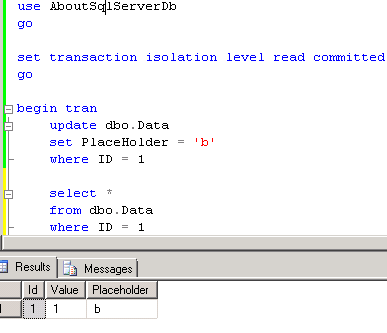
Let’s look at the locks we have in the system. As you can see, we have exclusive lock on the row. This is expected and should happen with any isolation level. Click to the image to open it in the different window

Now let’s start another session and try to select the same row.
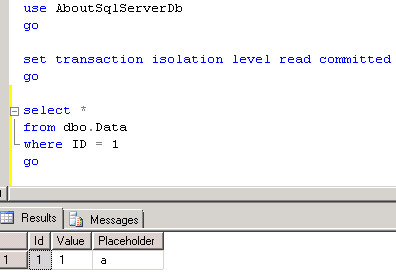
And here is the big difference with regular read committed. Instead of being blocked as when we have pessimistic isolation level, it returns old version of the row with placeholder equal ‘a’. So far, so good. Now let’s run another update.

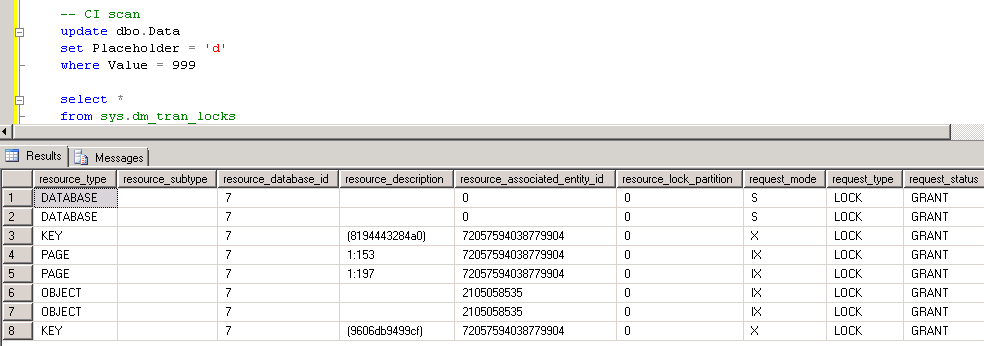
As you can see, with read committed snapshot we still have writers acquiring U and X locks – so those statements would be blocked as with regular pessimistic isolation levels. What does it really mean for us? If your system suffers because of the blocking between readers and writers, read committed snapshot helps in such situation – blocking would be reduced. This is especially good if you need to deal with 3rd party vendors databases – you can change the database option and (partially) solve the problem. Although read committed snapshot would not help if writers block each other. you’ll still have typical update and exclusive locks behavior.
One other thing I already mentioned – read committed snapshot does not provide you consistency on the transaction scope. Consistency is guaranteed only on the statement scope. Let’s check that:
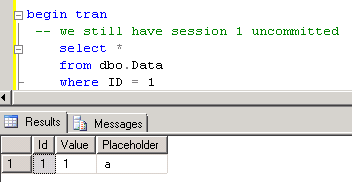
Now let’s commit the session 1 (I don’t put screen shot here) and run select statement again. We’re on the same transaction context.

As you can see, select returns new (updated) row value. Again, no transaction level consistency in such case. If you need full consistency on transaction level, you need to use SNAPSHOT isolation level. With such isolation level SQL Server stores multiple “old” versions of the row – as long as there are transactions that can reference them. When session references the row, it reads the version that was valid on the moment when transaction started. It has “snapshot” of the data for the transaction.
Let’s take a look. First, you need to enable that option on database level. Again, you need to be on single user mode in order to do so.

Next, let’s run same update statement and keep transaction uncommitted.

Now let’s go to another session, start transaction in snapshot isolation level and see what happens.
First, let’s select of the row updated by another session that holds X lock. As you can see – same behavior with read committed snapshot – it returns old value.
Now let’s try to update another row with table scan. As you can see – no blocking due U/X lock incompatibility now. Both rows have been updated, 2 X locks held
Now let’s commit transaction in the first session and run select in the second session again. It still returns the data that you had at the time when transaction was just started. Even if that row has been modified.
And now let’s delete that row in the first session.
![]()
If you run same select in the second session – it still returns that row.
As you can see, this is consistency on the transaction level. SQL Server guarantees that data within the transaction would be exactly the same during transaction lifetime. Even if it looks similar to Serializable isolation level, there is the key difference. With Serializable level you “lock” the data on the moment you access it. With Snapshot, it “locked” on the moment when transaction started. And obviously, this is the Heaven for reporting – consistent data with no blocking.
Too good to be true. Yes, there are a few things you need to keep in mind from both DBA and Development prospective. And we will talk about them next time.
Source code is available for download
Part 9 – Optimistic transaction isolation levels – TANSTAAFL!
Also take a look at Part 15 – When Transaction Starts. It gives some additional details about snapshot isolation level