It’s been a while since I posted any Sunday T-SQL Tips. Well, let’s do it today even if it’s Thursday :). I feel a little bit guilty stopping to blog about locking and blocking. I promise, I will blog about optimistic isolation levels in 2 weeks.
Today I want to talk about 2 very similar operators: SET and SELECT. If you ask T-SQL Developer what to use, in most part of cases she/he answers that it does not really matter. Well, it’s correct – up to degree. Those operators work in the same way unless they work differently. Let’s take a look.
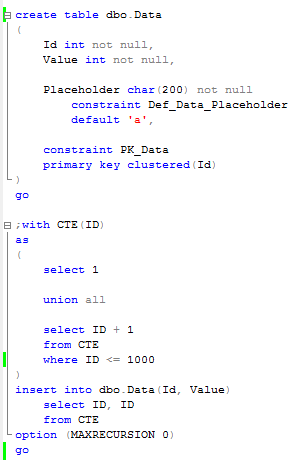
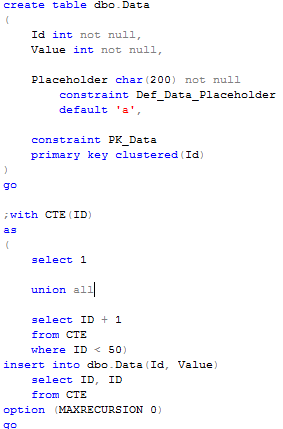
First, let’s create a table and populate it with 50 rows.
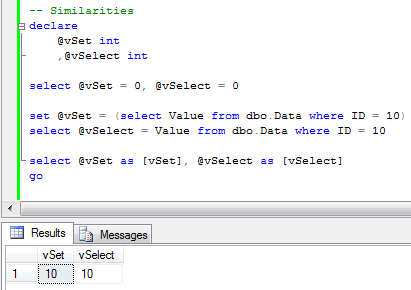
Now, let’s look at the similarities. Let’s query the row. As you can see, both operators work the same way. Plain and perfect.
Now let’s change the query and try to select the row that does not exist in the table.
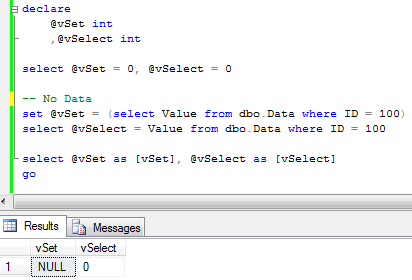
And here is the first major difference – SET operator “sets” variable to null. SELECT kept old value. It makes sense, if you think about it – SET assignes result from subquery that did not return any data. But more interesting behavior is when query tries to select multiple rows. Let’s run select first.

As you can see, it processes 9 rows and at the end variable has the value from the last one. Let’s check SET operator:

As you can see – it failed. Again, makes sense if you think about it from subquery standpoint.
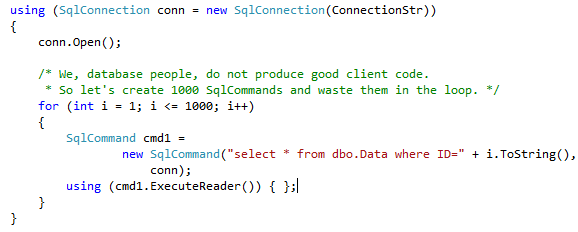
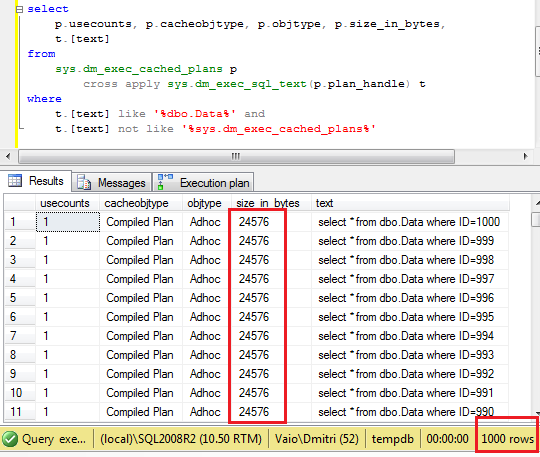
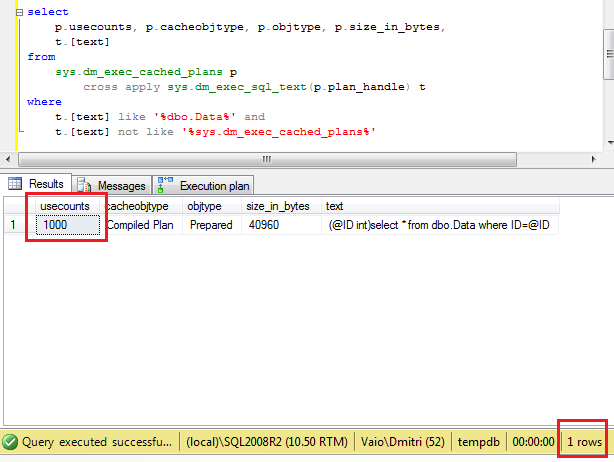
Let’s think about it from the practical angle. Assuming you need to query some row from Users table based on Name. If today Name is unique (and has unique constraint/index on it) it does not really matter what to use SET or SELECT. Although, what will happen with the code that uses SELECT if in one day, name stops to be unique? Obviously it introduces hard-to-find bugs/side effects – system just picks up one of the rows. Using SET in such case helps – code simply fails. Obviously it will require troubleshooting but at the end it will take much less time to pinpoint the problem. Of course, you can check @@RowCount (and it’s the only choice if you need to select/assign more than 1 variable as part of the query), but with 1 variable SET is more elegant (based on my opinion).
Same time, when I need to assign constants to the multiple variables, I prefer to use select. Less typing and probably a couple microseconds of performance improvement due less operators.
Code can be downloaded here