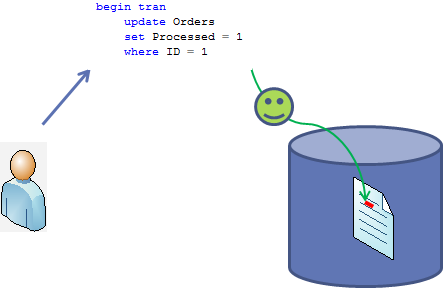
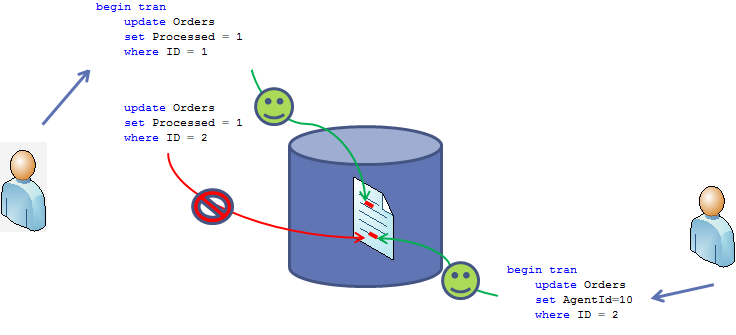
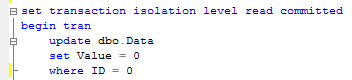
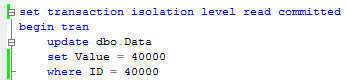
As we already saw, the reasons why we have blocking issues and deadlocks in the system are pretty much the same. They occur because of non-optimized queries. So, not surprisingly, troubleshooting techniques are very similar. Let’s have a quick look. We’ll use the same scripts I used last time.
The simplest approach is to use SQL Profiler. There is “Deadlock graph” event in the “Locks” event group you can use. Click on the picture to open it in the different window.
Let’s start the trace and trigger deadlock.
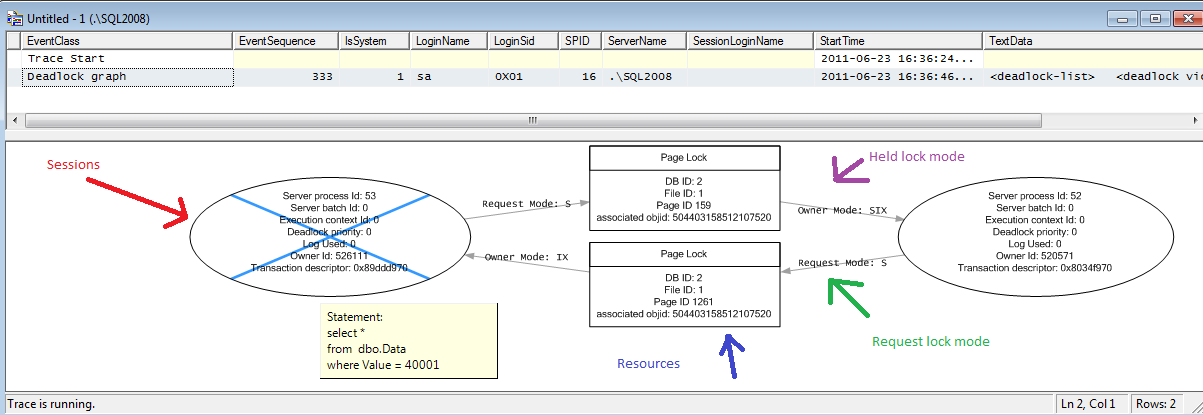
As you can see, it shows you very nice picture. There are 2 sessions (ovals) involved. Those sessions compete for the page locks (squares). You can see what locks each session held and you can even track it down to the resources (but that rarely needed). You can even see the statements when you move the mouse over the session oval and wait for the tool tip.
In context menu for “deadlock graph” line in the grid above, you have “Extract event data” menu command that can save this information as the file.
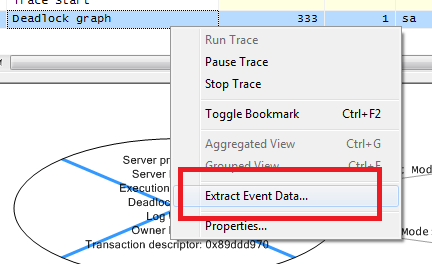
You can open it as the graph in management studio or, technically, simply look at XML which is extremely familiar:
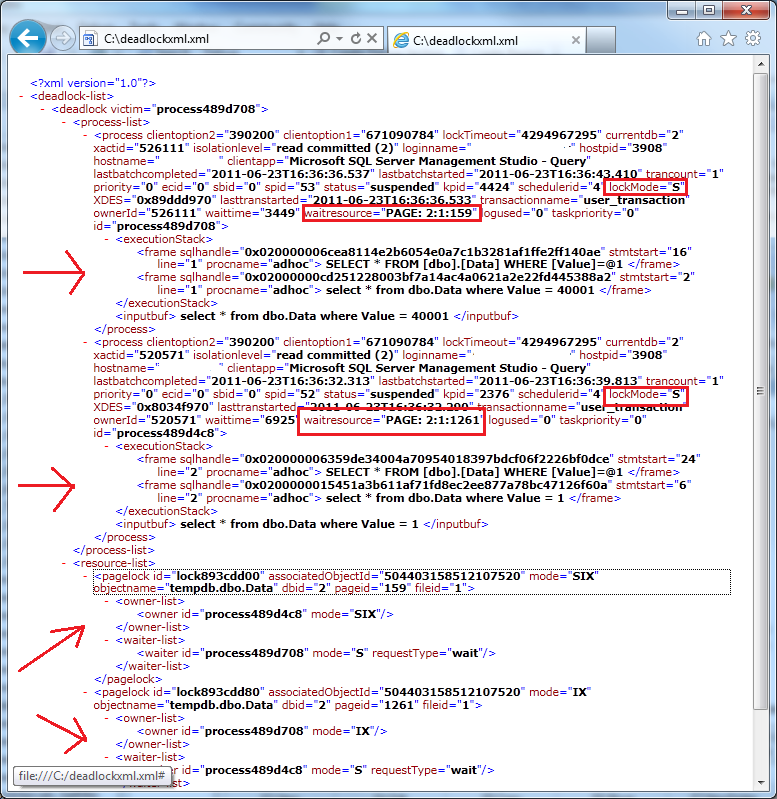
As you can see it’s way more detailed in compare with graphical representation. It’s also extremely familiar with blocking process report – and you can use same technique and query sys.dm_exec_sql_text if you need to obtain sql text from handle. I demonstrated how to do that in post related with blocking troubleshooting.
In case, if you don’t want to use SQL Profiler, there are 2 options you can use. The first one is enabling trace flag 1222 with DBCC TRACEON(1222,-1) command. When you have it enabled, SQL Server put deadlock graph XML to SQL Server log.
Another option is using extended events (SQL Server 2008/2008R2). Again, it’s very powerful method although requires some initial work to set it up. As with the blocking, I’m leaving it out of scope for now.
How to deal with deadlocks? Of course, the best thing is not to have deadlocks at the first place. Again, golden rule is to optimize the queries. Meanwhile, if you need to control (up to degree) what session will be terminated, you can use SET DEADLOCK PRIORITY option. There are 21 priority levels available. When 2 sessions deadlocked, the session with the lower deadlock priority level would be chosen as the victim. In case of the same priority level (default case), SQL Server chooses the session that is less expensive to rollback.
If session is chosen as the victim, it would be aborted with error code 1205. In such case client (or T-SQL code) can catch the exception and re-run the query. But again, the best way is avoiding deadlocks at the first place.