Last week we discussed a few things we have to keep in mind implementing sliding window scenario. Unfortunately table partitioning available in SQL Server Enterprise edition only. How should we purge the transactional data with other editions of SQL Server? Obviously there is no such thing as the golden bullet. Same time there is one particular scenario a lot of the systems have – transactional table with clustered index on identity column. Let’s see how we can optimize the purge process in such case.
Assuming we have a table with identity ID column and DateCreated datetime column. Assuming you need to purge the data based on that DateCreated column. It could happen daily, monthly – i.e. with some time interval. So let’s create such table and populate it with 1M rows. Let’s create an index on DateCreated column.

Now let’s try to purge data a few times and see the results. Please ignore begin tran/rolback – only purpose of those is to preserve the data between the test runs.


As you can see, purging about 40% of the rows takes about 3.5 seconds. There are 2 possible execution plans based on the number of the rows we need to delete – either using clustered index scan (our 40% case) or non-clustered index seek (if % of the row is smaller).


In any case, let’s think about it in more details. In both cases, SQL Server needs to process a lot of data and acquire/hold U/X locks for the duration of the execution. Not really good in terms of concurrency.
What can we do in order to improve it? In the table design like that our DateCreated column is increasing/populating same way with identity. So instead of deleting data based on DateCreated column (that most likely uses non-clustered index seek), let’s get ID of the row we want to keep (i.e min(ID) where DateCreated > @). Next step, instead of deleting everything at once, we can delete data in batches (10-100K rows each) in the individual transactions. In such case locks would be kept only within the batch deletion.
Let’s take a look. Again, please ignore outer begin tran/rollback.
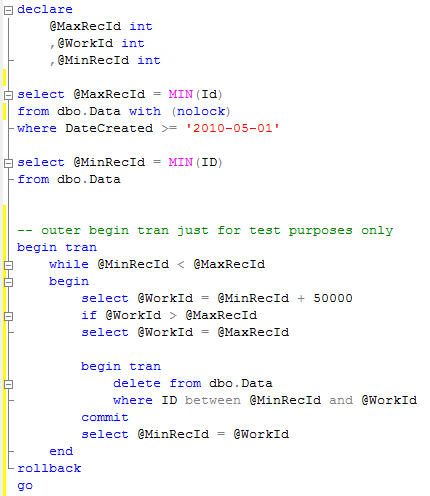

As you can see, it runs about 10% faster but more importantly, it reduces the blocking in the table. Let’s take a look at the plan.
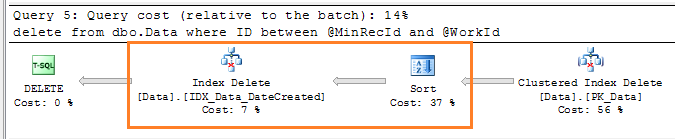
Non-surprisingly it uses clustered index seek/delete. But as you see – a lot of time wasted on NCI maintenance. And here is the interesting point. Does system really need to have the index on DateCreated for any other purpose than purge? If this is the case, we can safely drop it. Yes, it would take more time to find initial @MaxRecId but on other hand this would be either (S) locks or even no-locks at all if read uncommitted is acceptable. And in those cases we more concern about the locking instead of the execution time.
So let’s give it a try without the index.


As you can see, it runs more than 2 times faster. This solution and design are not always good. First of all, making CI on identity column on the large transactional table is bad idea by itself. But I saw a lot of systems and designs like that. In such case, this solution could benefit the purge process.
Code is available here.