As we already discussed, implementing of sliding window scenario is one of the biggest benefits you can get from table partitioning. Technically this is quite simple process – when time comes, you have to do 2 different actions:
- Create the new partition for the future data
- Switch the oldest partition to the temporary table. After that you can either truncate or archive that data. Possibly even switch this temporary table as the new partition in the historical table.
There are quite a few resources that can show how you can achieve that from the technical standpoint. You can see the example in technet. I’m not going to focus on the implementation details and rather talk about a few less obvious aspects of the implementation.
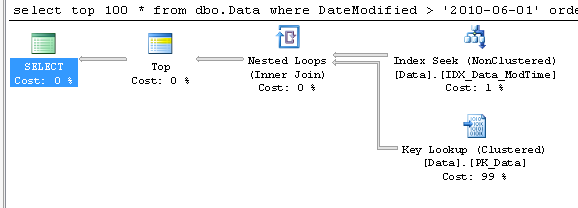
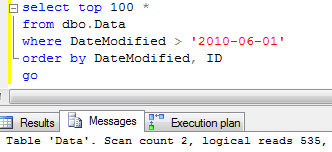
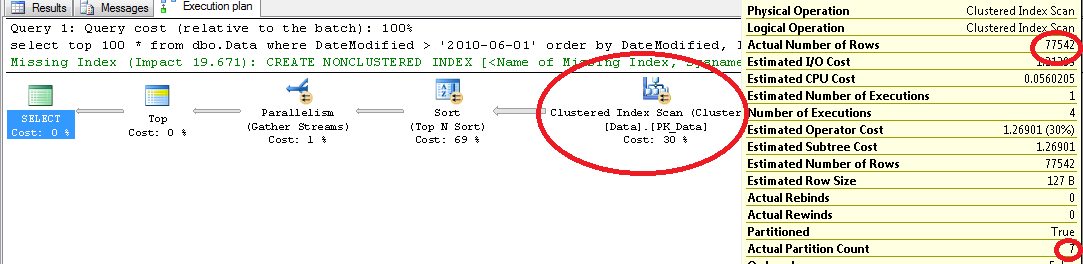
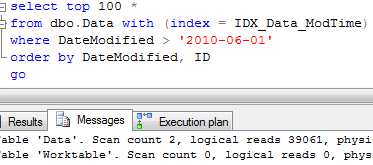
Usually, we are implementing partitions on the Date basis. We want to purge data daily, monthly or yearly. The problem with this approach is that partition column needs to be included to the clustered index (and as result every non-clustered index). It means extra 4-8 bytes per row from the storage prospective and less efficient index because of bigger row size -> more data pages -> more IO. Obviously there are some cases when nothing can be done and you have to live with it. Although, in a lot of cases, those transaction tables have autoincremented column as part of the row and CI already. In such case, there is the great chance that date column (partition column candidate) would increment the same way with autoincremented ID column. If this is the case, you can think about partitioning by ID instead. This introduces a little bit more work – most likely you’ll
need to maintain another table with (Date,ID) correlations although it would pay itself off because of less storage and better performance requirements. Of course, such assumption cannot guarantee that row always ends up on the right partition. If, for example, insert is delayed, ID could be generated after the split. But in most part of the cases you can live with it.
Second thing is creating the new partition. Let’s take a look at the example. First, let’s create the partitioned table and populate it with some data.

This table has 2 partitions – left with ID <= 100,000 and right, with ID > 100,000. Let’s assume we want to create another partition for the future data (let’s even use ID=200,000 as the split point).

At this point, SQL needs to find out if some data needs to be moved to the new partition. As you can see, it produces a lot of reads. Now let’s try to create another partition with 300,000 as the split point.

As you can see – no IO in such case. So the rule is to always have one additional empty partition reserved. If you decide to accomplish partitioning by ID like we already discussed, make sure:
- You reserved enough space on the second right-most partition for the time period
- If ID is identity, insert the dummy row with identity insert on after split in order to start placing the new data to the new partition. Obviously you’ll have holes in the sequence.
Last thing I’d like to mention is locking. Partition switch is metadata operation. Although it will require SCHEMA MODIFICATION (Sch-M) lock. This lock is not compatible with schema stability (SCH-S) lock SQL Server issues during query compilation/execution. If you have OLTP system with a lot of concurrent activity, make sure the code around partition switch/split handles lock timeouts correctly.
Source code is available here
Also – check this post – it could give you some tips how to decrease the possibility of deadlocks during partition/metadata operations.