What could be simpler than union? Probably “union all”.
“Union” removes all duplicates from the combined row set. Union all simply concatenate the row sets. Obviously, if original row sets are unique, results would be the same. But plans are not.
Take a look here. Let’s create 2 tables with some data.

Now let’s do the union and union all and see the plans.
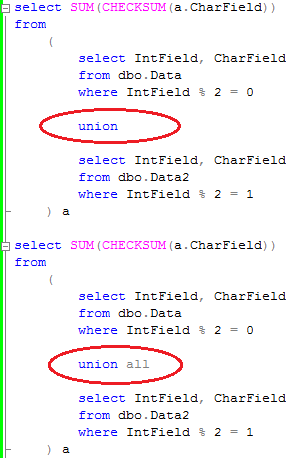
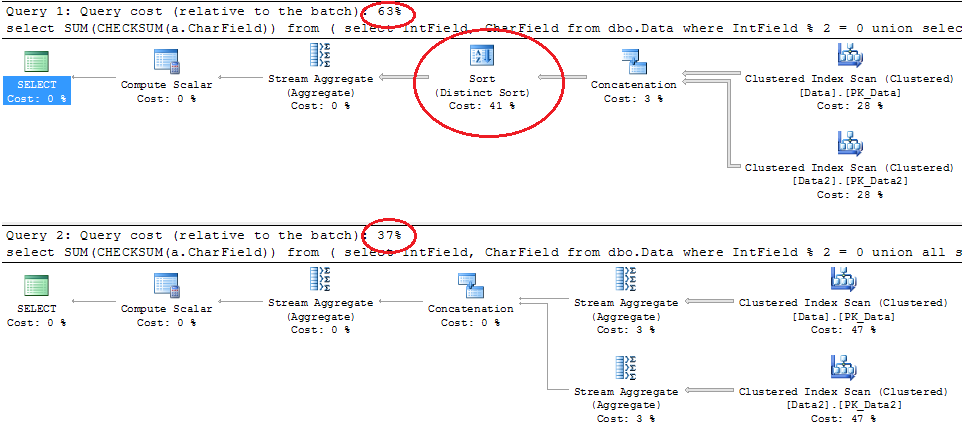
Union introduces another expensive “Distinct Sort” operator. As result the execution plan with union is almost 2 times more expensive than with union all. Of course, your mileage may vary – in the case of the large and complex queries the higher cost of “Union” operator could be hidden but in any case, it’s more expensive. So don’t use it if rowsets don’t have duplicates.
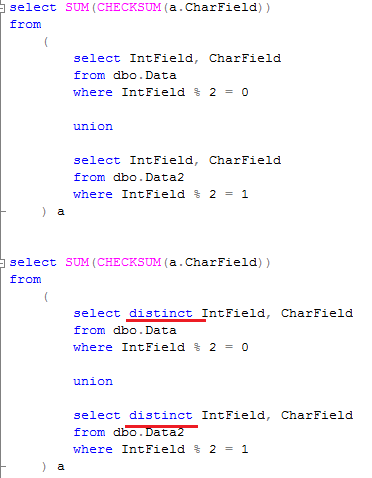
Speaking of the duplicates – there is another thing you need to keep in mind. When union removes the duplicates from combined rowsets, it does not really matter where duplicates come from. So you don’t need to use distinct as part of the selects. And it affects the plan too. Look here:

Source code is available for download from here