Last week we discussed how to implement Sliding Window pattern in the tables with columnstore indexes. As I promised, today we are going to focus on partition management in such tables.
As you will remember, SQL Server does not allow you to split and merge non-empty columnstore partitions. I personally do not consider it as the huge limitation – perhaps because I rarely have reasons to do it in columnstore tables. However, there are still some cases when it may be required.
As one of examples, think about a table, partitioned by date, which may be populated with incorrect data from the future. Perhaps due to some issues in ETL processes. Some rows may be placed to incorrect (future) partition, which would prevent its split.
The common, by the book approach recommends dropping columnstore index, splitting or merging partitions and recreating the index afterwards. As you can imagine, it would lead to extremely inefficient process with huge amount of unnecessary overhead on large tables. After all, you have to drop and recreate columnstore index, converting table to Heap, while just subset of the partitions needs to be rebuilt. Fortunately, you can minimize the overhead with simple workaround:
- Switch partition(s) to split or merge to the separate staging table
- Split or merge partition(s) in the main table. You can do that because partitions will be empty after the previous step
- Drop columnstore index in the staging table, split/merge partition(s) there and recreate the index afterwards
- Switch partition(s) back from staging to the main table.
Let’s look at the process in details. I am going to recreate the tables I used last week with the script below.
create partition function pfOrders(datetime2(0))
as range right for values
('2016-11-01','2016-12-01','2017-01-01','2017-02-01'
,'2017-03-01','2017-04-01','2017-05-01','2017-06-01'
,'2017-07-01','2017-08-01','2017-09-01','2017-10-01'
,'2017-11-01','2017-12-01','2018-01-01');
create partition scheme psOrders
as partition pfOrders
all to ([Primary]);
create table dbo.Orders
(
OrderDate datetime2(0) not null,
OrderId int not null,
Placeholder char(100),
)
on psOrders(OrderDate);
create table dbo.OrderLineItems
(
OrderDate datetime2(0) not null,
OrderId int not null,
OrderLineItemId int not null,
Placeholder char(100),
)
on psOrders(OrderDate);
go
-- Left-most and right-most are empty
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as t1 cross join N1 as t2) -- 4 rows
,N3(C) as (select 0 from N2 as t1 cross join N2 as t2) -- 16 rows
,N4(C) as (select 0 from N3 as t1 cross join N3 as t2) -- 256 rows
,N5(C) as (select 0 from N4 as t1 cross join N4 as t2) -- 65,536 rows
,Ids(Id) as (select row_number() over (order by (select null)) from N5)
insert into dbo.Orders(OrderDate, OrderId)
select dateadd(day,Id % 390,'2016-11-01'), ID
from Ids;
insert into dbo.OrderLineItems(OrderDate,OrderId, OrderLineItemId)
select OrderDate, OrderId, OrderId
from dbo.Orders;
go
create clustered columnstore index CCI_Orders on dbo.Orders
on psOrders(OrderDate);
create clustered columnstore index CCI_OrderLineItems on dbo.OrderLineItems
on psOrders(OrderDate);
go
select
t.object_id, i.index_id, i.name as [Index], p.partition_number,
p.[Rows], p.data_compression_desc,
fg.name as [Filegroup],
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
sum(a.total_pages) * 8 as TotalSpaceKB,
sum(a.used_pages) * 8 as UsedSpaceKB,
sum(a.data_pages) * 8 as DataSpaceKB
from
sys.tables t with (nolock) join sys.indexes i with (nolock) on
t.object_id = i.object_id
join sys.partitions p with (nolock) on
i.object_id = p.object_id AND i.index_id = p.index_id
join sys.allocation_units a with (nolock) on
p.partition_id = a.container_id
join sys.filegroups fg with (nolock) on
a.data_space_id = fg.data_space_id
where
t.object_id = object_id(N'dbo.Orders')
group by
t.object_id, i.index_id, i.name, p.partition_number,
p.[Rows], p.data_compression_desc, fg.name
order by
i.index_id, p.partition_number;
Figure 1 demonstrates data distribution across partitions in the dbo.Orders table. As you can see, we have 13 non-empty partitions started from November 2016 up to end of November 2017.
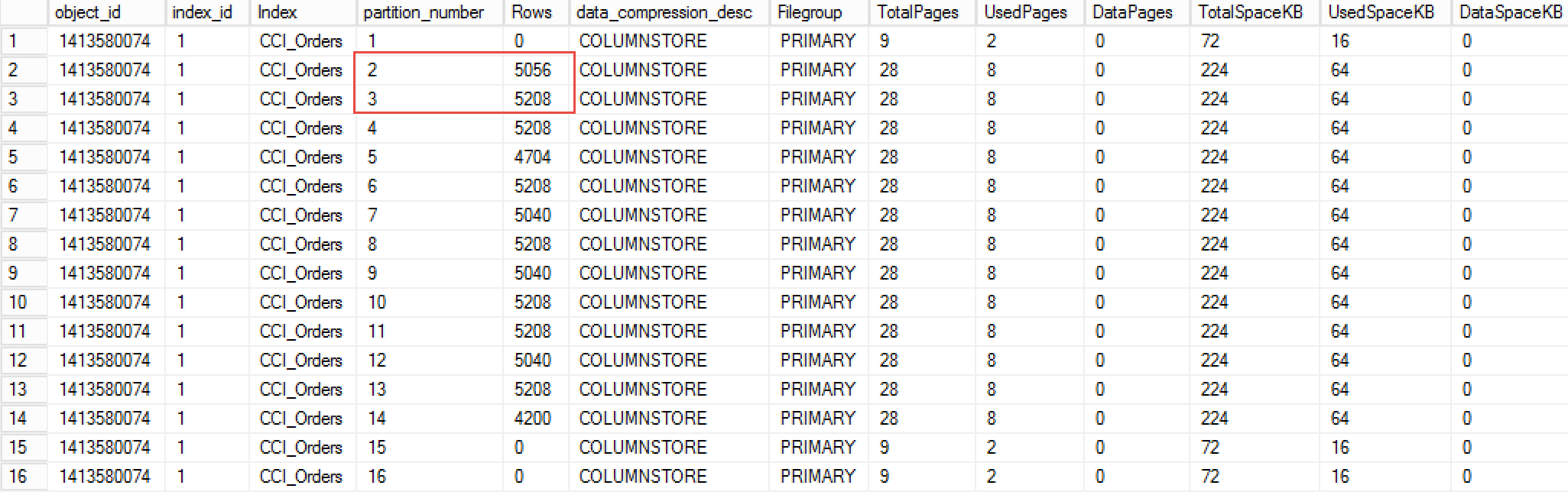
01.Initial Data Distribution
Let’s assume that we would like to merge November and December 2016 together, which are partitions 2 and 3 in the tables.
As the first step, we will create the staging tables. They need to be partitioned in the same way as the main tables. It is better to use separate partition function to decouple merge and split operations in main and staging tables from each other. Remember that SQL Server would hold schema modification (Sch-M) lock on all tables that use partition function for the duration of merge and split operations.
Partition function on the staging tables does not need to include all partitions from the main tables. It just need to include partition(s) you are about it split or merge and two adjacent partitions on the left and right sides. This will guarantee that partitions in the main and staging tables are aligned before and after the operation. It would also support partition switch without requirement of creating extra CHECK constraints on the staging tables. As you can see in the code below, pfOrdersStaging function consists of four partitions:
- Everything prior November 2016. Will be empty.
- November 2016
- December 2016
- Everything on or after January 1st 2017. Will be empty
create partition function pfOrdersStaging(datetime2(0))
as range right for values
('2016-11-01','2016-12-01','2017-01-01');
create partition scheme psOrdersStaging
as partition pfOrdersStaging
all to ([Primary]);
create table dbo.OrdersStaging
(
OrderDate datetime2(0) not null,
OrderId int not null,
Placeholder char(100),
)
on psOrdersStaging(OrderDate);
create clustered columnstore index CCI_OrdersStaging on dbo.OrdersStaging
on psOrdersStaging(OrderDate);
create table dbo.OrderLineItemsStaging
(
OrderDate datetime2(0) not null,
OrderId int not null,
OrderLineItemId int not null,
Placeholder char(100),
)
on psOrdersStaging(OrderDate);
create clustered columnstore index CCI_OrderLineItemsStaging on dbo.OrderLineItemsStaging
on psOrdersStaging(OrderDate);
After the staging tables are created, we can switch two partitions from the main tables there.
alter table dbo.Orders switch partition 2 to dbo.OrdersStaging partition 2; alter table dbo.OrderLineItems switch partition 2 to dbo.OrderLineItemsStaging partition 2; alter table dbo.Orders switch partition 3 to dbo.OrdersStaging partition 3; alter table dbo.OrderLineItems switch partition 3 to dbo.OrderLineItemsStaging partition 3;
Now we can merge the partitions in the main tables. SQL Server will allow us to proceed because they are empty after the switch.
alter partition function pfOrders() merge range ('2016-12-01');
Finally, we can merge partitions in our staging tables and switch them back to the main tables as shown below.
drop index CCI_OrdersStaging on dbo.OrdersStaging;
drop index CCI_OrderLineItemsStaging on dbo.OrderLineItemsStaging;
go
-- Offline with Sch-M
alter partition function pfOrdersStaging()
merge range ('2016-12-01');
go
create clustered columnstore index CCI_OrdersStaging on dbo.OrdersStaging
on psOrdersStaging(OrderDate);
create clustered columnstore index CCI_OrderLineItemsStaging on dbo.OrderLineItemsStaging
on psOrdersStaging(OrderDate);
go
-- Switching partitions back
alter table dbo.OrdersStaging switch partition 2
to dbo.Orders partition 2;
alter table dbo.OrderLineItemsStaging switch partition 2
to dbo.OrderLineItems partition 2;
As you can see in Figure 2, now partition 2 stores the data for both November and December of 2016.
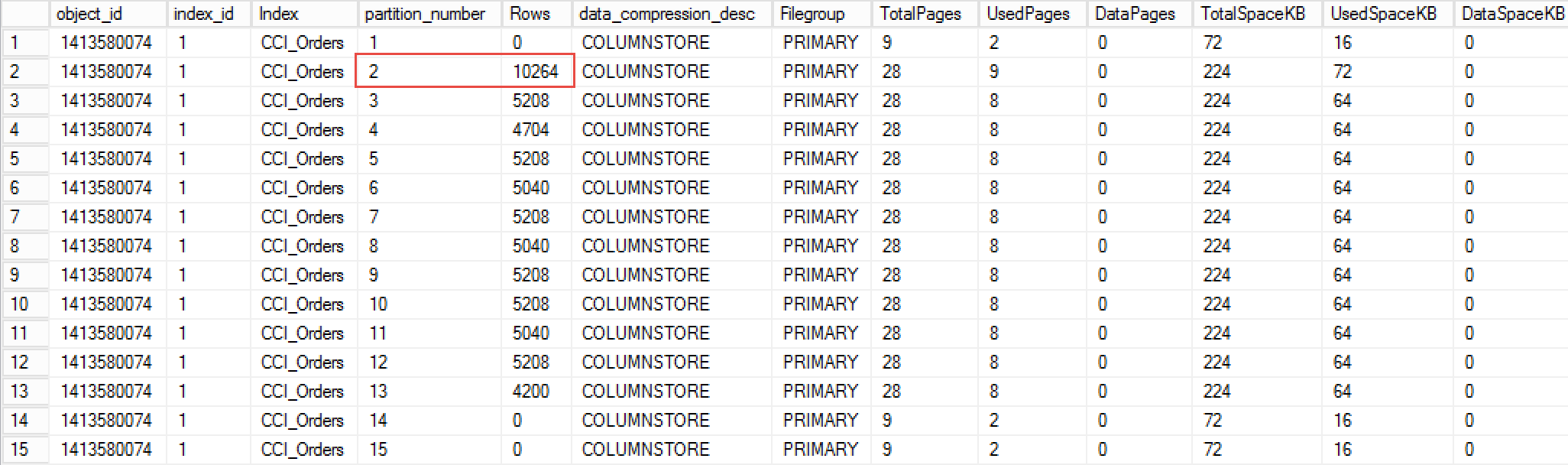
02.Data Distribution After Merge
We can use the same approach for partition split. Code below demonstrates how to split November 2017 partition using 2017-11-15 as the new range value.
-- Spliting November 2017 partition (#13)
-- Recreating Staging objects first
drop table if exists dbo.OrdersStaging;
drop table if exists dbo.OrderLineItemsStaging;
if exists(select * from sys.partition_schemes where name = 'psOrdersStaging') drop partition scheme psOrdersStaging;
if exists(select * from sys.partition_functions where name = 'pfOrdersStaging') drop partition function pfOrdersStaging;
go
create partition function pfOrdersStaging(datetime2(0))
as range right for values
('2017-11-01','2017-12-01');
create partition scheme psOrdersStaging
as partition pfOrdersStaging
all to ([Primary]);
create table dbo.OrdersStaging
(
OrderDate datetime2(0) not null,
OrderId int not null,
Placeholder char(100),
)
on psOrdersStaging(OrderDate);
create clustered columnstore index CCI_OrdersStaging on dbo.OrdersStaging
on psOrdersStaging(OrderDate);
create table dbo.OrderLineItemsStaging
(
OrderDate datetime2(0) not null,
OrderId int not null,
OrderLineItemId int not null,
Placeholder char(100),
)
on psOrdersStaging(OrderDate);
create clustered columnstore index CCI_OrderLineItemsStaging on dbo.OrderLineItemsStaging
on psOrdersStaging(OrderDate);
-- Switching partitions to the staging table
alter table dbo.Orders switch partition 13
to dbo.OrdersStaging partition 2;
alter table dbo.OrderLineItems switch partition 13
to dbo.OrderLineItemsStaging partition 2;
go
-- Splitting partition in the main table
alter partition scheme psOrders
next used [PRIMARY];
alter partition function pfOrders()
split range ('2017-11-15');
go
-- Now spllitting partition in the Staging table
drop index CCI_OrdersStaging on dbo.OrdersStaging;
drop index CCI_OrderLineItemsStaging on dbo.OrderLineItemsStaging;
go
-- Offline with Sch-M
alter partition scheme psOrdersStaging
next used [PRIMARY];
alter partition function pfOrdersStaging()
split range ('2017-11-15');
go
create clustered columnstore index CCI_OrdersStaging on dbo.OrdersStaging
on psOrdersStaging(OrderDate);
create clustered columnstore index CCI_OrderLineItemsStaging on dbo.OrderLineItemsStaging
on psOrdersStaging(OrderDate);
-- Switching partitions back
alter table dbo.OrdersStaging switch partition 2
to dbo.Orders partition 13;
alter table dbo.OrdersStaging switch partition 3
to dbo.Orders partition 14;
alter table dbo.OrderLineItemsStaging switch partition 2
to dbo.OrderLineItems partition 13;
alter table dbo.OrderLineItemsStaging switch partition 3
to dbo.OrderLineItems partition 14;
As you can see, with just a few extra operators, we were able to remove the overhead of rebuilding columnstore index on entire table.
Unfortunately, this is offline approach. The data in the main tables would become inconsistent as soon as you switch partitions to the staging tables. Fortunately, if data is static, you can address it with some coding.
Instead of switching partitions to the staging tables, you can copy the data there. After split or merge is done in the staging tables, you can empty source partitions by switching them to another, temporary tables, and switch data back from the staging tables.
The code below illustrates this approach.
-- If data in the table is static
-- Let's merge November-December 2016 and January 2017
drop table if exists dbo.OrdersStaging;
drop table if exists dbo.OrderLineItemsStaging;
if exists(select * from sys.partition_schemes where name = 'psOrdersStaging') drop partition scheme psOrdersStaging;
if exists(select * from sys.partition_functions where name = 'pfOrdersStaging') drop partition function pfOrdersStaging;
go
create partition function pfOrdersStaging(datetime2(0))
as range right for values
('2016-11-01','2017-01-01','2017-02-01');
create partition scheme psOrdersStaging
as partition pfOrdersStaging
all to ([Primary]);
create table dbo.OrdersStaging
(
OrderDate datetime2(0) not null,
OrderId int not null,
Placeholder char(100),
)
on psOrdersStaging(OrderDate);
create clustered columnstore index CCI_OrdersStaging on dbo.OrdersStaging
on psOrdersStaging(OrderDate);
create table dbo.OrderLineItemsStaging
(
OrderDate datetime2(0) not null,
OrderId int not null,
OrderLineItemId int not null,
Placeholder char(100),
)
on psOrdersStaging(OrderDate);
create clustered columnstore index CCI_OrderLineItemsStaging on dbo.OrderLineItemsStaging
on psOrdersStaging(OrderDate);
-- Copying data from Main to Staging tables
insert into dbo.OrdersStaging(OrderDate,OrderId,Placeholder)
select OrderDate, OrderId, Placeholder
from dbo.Orders
where $Partition.pfOrders(OrderDate) in (2,3);
insert into dbo.OrderLineItemsStaging(OrderDate,OrderId,OrderLineItemId,Placeholder)
select OrderDate, OrderId, OrderLineItemId, Placeholder
from dbo.OrderLineItems
where $Partition.pfOrders(OrderDate) in (2,3);
go
-- Merging partitions in Staging tables
drop index CCI_OrdersStaging on dbo.OrdersStaging;
drop index CCI_OrderLineItemsStaging on dbo.OrderLineItemsStaging;
go
alter partition function pfOrdersStaging()
merge range ('2017-01-01');
go
create clustered columnstore index CCI_OrdersStaging on dbo.OrdersStaging
on psOrdersStaging(OrderDate);
create clustered columnstore index CCI_OrderLineItemsStaging on dbo.OrderLineItemsStaging
on psOrdersStaging(OrderDate);
go
-- Creating temporary table to switch original
-- partitions from the main table
create partition function pfOrdersTmp(datetime2(0))
as range right for values
('2016-11-01','2017-01-01','2017-02-01');
create partition scheme psOrdersTmp
as partition pfOrdersTmp
all to ([Primary]);
create table dbo.OrdersTmp
(
OrderDate datetime2(0) not null,
OrderId int not null,
Placeholder char(100),
)
on psOrdersTmp(OrderDate);
create clustered columnstore index CCI_OrdersTmp on dbo.OrdersTmp
on psOrdersTmp(OrderDate);
create table dbo.OrderLineItemsTmp
(
OrderDate datetime2(0) not null,
OrderId int not null,
OrderLineItemId int not null,
Placeholder char(100),
)
on psOrdersTmp(OrderDate);
create clustered columnstore index CCI_OrderLineItemsTmp on dbo.OrderLineItemsTmp
on psOrdersTmp(OrderDate);
-- Final steps. Let's do it in transaction
-- All operations are on metadata level
set xact_abort on
begin tran
-- Switching original partitions out
alter table dbo.Orders switch partition 2
to dbo.OrdersTmp partition 2;
alter table dbo.OrderLineItems switch partition 2
to dbo.OrderLineItemsTmp partition 2;
alter table dbo.Orders switch partition 3
to dbo.OrdersTmp partition 3;
alter table dbo.OrderLineItems switch partition 3
to dbo.OrderLineItemsTmp partition 3;
-- Merge
alter partition function pfOrders()
merge range ('2017-01-01');
-- Switching partitions from the staging table
alter table dbo.OrdersStaging switch partition 2
to dbo.Orders partition 2;
alter table dbo.OrderLineItemsStaging switch partition 2
to dbo.OrderLineItems partition 2;
commit;
go
-- Dropping temporary tables
drop table dbo.OrderLineItemsTmp;
drop table dbo.OrdersTmp;
drop partition scheme psOrdersTmp;
drop partition function pfOrdersTmp;
As you can see, this implementation is relatively simple and considering that data in columnstore indexes is often static, you may be able to utilize it to perform partition maintenance transparently to the users.
Source code is available for download.