What is the right answer to the question: “When does my explicit transaction start”? The answer looks obvious – when I run “begin tran” statement. Well, not exactly. Yes, BEGIN TRAN statement marks the logical point when you start the transaction in your code. But does it do anything? Let’s see.
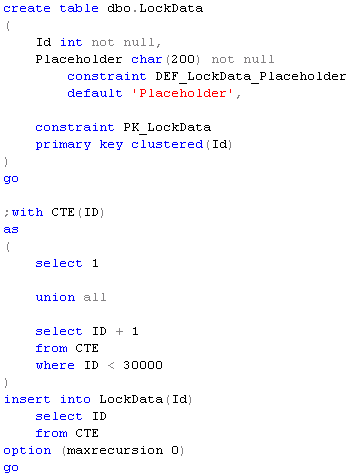
First, let’s create the test database for simplicity sake. Next, let’s create the table in this database and after that look at transaction log. We will use non-documented but well known function fn_dblog. Again, for simplicity let’s not filter any content – just see entire log there sorted by LSN in descending order together with record count.


As we can see, we have 445 records there and the last one ends on e3:000b. Now let’s open another session and run BEGIN TRAN there. Even with PRINT statement.
![]()
Now let’s look at transaction log again. We can see – nothing changes – still 445 records with the last one ends on e3:000b.
Now let’s insert one row there.
![]()
And now we finally have new entries in transaction log.

25 more records. And the first one inserted after e3:000b is LOP_BEGIN_XACT which corresponds to begin transaction. Now let’s commit the transaction and look at Books Online: Although BEGIN TRANSACTION starts a local transaction, it is not recorded in the transaction log until the application subsequently performs an action that must be recorded in the log, such as executing an INSERT, UPDATE, or DELETE statement. An application can perform actions such as acquiring locks to protect the transaction isolation level of SELECT statements, but nothing is recorded in the log until the application performs a modification action.
And that’s what we just saw. Well, that’s interesting (and documented) behavior but there is another very interesting aspect related with SNAPSHOT transactions. As we know, SNAPSHOT isolation level provides transaction level consistency. The key point – what is the starting point for consistency. Let’s take a look. First, let’s enable snapshot isolation level on database level.

Next, let’s create another table and insert 1 row there.

Now let’s start transaction and look at DMV that shows us active snapshot transactions


As we can see – nothing. Now let’s open another session and insert another row to this table
![]()
Now let’s come back to the first session where we have active transaction and select from that table.
![]()

As you see – we have 2 rows. And if we look at active snapshot transactions again, we would have our transaction listed.

Now, let’s come back to the second session and delete all data
![]()
In snapshot transaction we still see 2 rows in that table.
So that’s interesting – we have transactional level consistency in snapshot transaction but that consistency starts at the point when we access the data for the first time, not at the moment of BEGIN TRAN statement. We does not necessarily need to access the same table – just any data to have our LSN for snapshot transaction logged. Let’s see that. As we remember, TEST2 table is empty now. Again, commit transaction first.
Let’s run transaction again and read data from another table (TEST):


As we can see, transaction is enlisted already. Now let’s go to the second session and add row to TEST2 table.
![]()
And now come back to our original session and select from TEST2.
![]()
![]()
No rows. As it happened to be at the moment when we ran select against another table.
This is interesting behavior that has not been fully documented. If we need to have consistency started from the moment of BEGIN TRAN, we have to access the data immediately after we issued this statement. Keep in mind though that from that moment SQL Server keeps all old versions of the rows from all tables in the version store. So long-running snapshot transactions increase the load and size of TEMPDB.
Source code is available for download.