Today I’d like us to talk about statement level recompilation and how it could help us in a few particular scenarios. Such as parameter sniffing, search with optional parameters and filtered indexes. But first of all, let’s talk why do we need to worry about that at all.
Let’s look at extremely oversimplified picture. When we submit the query to SQL Server, one of the first things SQL Server is doing is compiling the query. Compilation itself is not cheap, especially in case of complex queries. As result, SQL Server tries to cache execution plan and reuse it when the same query runs again. The interesting thing happens in case if query has parameters. SQL Server is looking at actual parameter values during compilation/recompilation stage and using them for cardinality estimations. This called parameter sniffing. As result, the plan (which will be cached) would be optimal for specific set of parameters provided during compilation stage. Next time, when SQL Server reuses the cached plan, there is the chance that plan would not be good for another set of values.
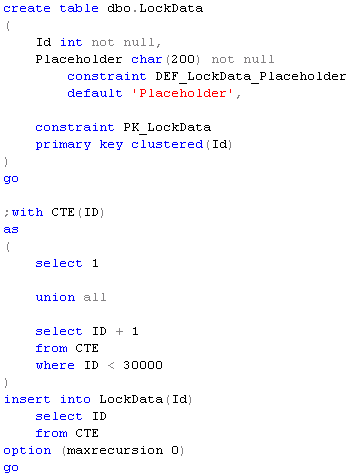
Let’s look at specific example. Let’s think about company that is doing some business internationally although most part of the customers are in USA. Let’s create the table and populate it with some data with ~99% of the customers in US. In addition to that let’s create an index on Country column. Images below are clickable.


Now let’s execute the query that selects customers for particular country. Most part of the client libraries would generate code like that.

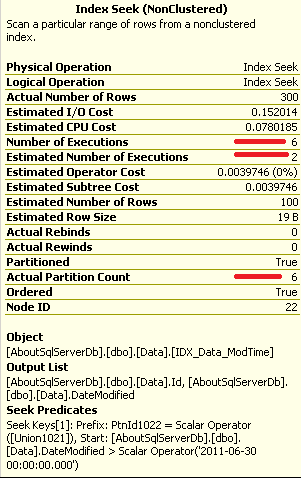
When we run the first statement with @Country = ‘Canada’, SQL Server chooses to use non-clustered index on Country and perform key lookup. This makes sense – we have only ~1% of canadian customers – value is selective enough. But the problem is that plan has been cached. And when we run select for @Country = ‘USA’, it re-uses the same plan which is extremely inefficient. Don’t be confused by query cost – let’s look at Statistics IO:
![]()
Just to prove inefficiency – let’s run the query again but use constant instead of parameter. You can see that SQL Server chooses clustered index scan which introduces ~50 times less logical reads in compare with original non-clustered index seek.

![]()
The same thing happens if we use stored procedures.

Now we can see the opposite effect – when we run this SP with @Country = ‘USA’, it generates clustered index scan. And reuses the same plan for Canadian customers. And this is real problem if we have data that distributed unevenly. Something forces recompilation and if we are “lucky enough” to have first call with untypical set of parameters – the inefficient plan would be cached and used for all queries.
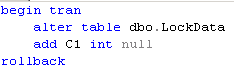
One of the ways to solve the problem is to use statement level recompile. If we add OPTION (RECOMPILE) to our code, SQL Server would not bother to cache the plan – it would recompile it every time optimizing it for the current set of parameters. Let’s take a look:


Obviously the downside of that particular method would be recompilation cost. Recompilation would happen every time the query executes.
Another area when statement level recompilation could be quite useful is the case when we need to select data based on optional (or dynamic) parameter set. I’ve already blogged about it a long time ago and today want to show you another way of doing that with statement level recompilation. But let’s first take a look at the problem:

As we can see, because plan is cached SQL Server is unable to generate the plan that would be valid regardless of parameter value. So clustered index scan is the option here. Now, if we add OPTION (RECOMPILE) to the statement, it would change the picture – as you see, it generates optimal plan in every case.

Is it better than the method with dynamic SQL I demonstrated in the old post – it depends. One of the downsides I have with recompilation is that plan would not be cached (which is, of course, expected) and would not be present in results of sys.dm_exec_query_stats DMV. I’m using this view all the time during performance tuning to find most expensive queries. Of course, I can catch those statements with other tools but that is less convinient for me.
Last example I’d like to show you related to filtered indexes. Let’s assume that our table hosts Customer data for both, Businesses and Consumers. We can have specific columns that belong only to specific category – granted this is questionable design but I saw it more than a few times. Systems like that could have different reports for different types of the customers and one of the ways to optimize those reports is to create covered filtered indexes based on customer type. Something like that:

But what if we want to have the shared code – assuming we would like to create SP that returns us customer by type and by name:

If we look at the filtered indexes we have – those are would be the perfect match for index seek. The problem is that SQL Server cannot generate and cache plan that relies on the filtered index. Choice of the index would depend on the @CustomerType parameter. And recompilation could help us here:

It’s questionable if OPTION (RECOMPILE) here is better than IF statement. But the point I want to make is if you’re using filtered indexes and filter value is provided as parameter, you should avoid plan caching if you want filtered indexes to be used.
Source code is available for download