It’s been a while since my last blog post. Many things happened, including another great PASS Summit where I presented the session of Data Partitioning (by the way, you can download the slides and demos from my Presentation page). As usual, I ran out of time 🙂
As many of you know, Data Partitioning is very big and complex subject, which is impossible to cover even with half-day session. One of the topics I left out of scope is how it plays with columnstore indexes. Even though partitioned columnstore tables are similar to B-Tree ones, there are some differences between them.
The biggest difference resides in partition function split and merge behavior. With B-Tree indexes, you can split and merge non-empty partitions. SQL Server would split or merge the data automatically, granted with the schema-modification (Sch-M) table lock held in place. Other sessions would be unable to access the table but at least split and merge would work.
This is not the case with columnstore indexes where you would get the error when you try to split or merge non-empty partitions. There are several reasons for this limitation. Without diving very deep into columnstore index internals, I could say that the only option of doing split of merge internally is rebuilding columnstore index on affected partitions. Fortunately, you can split and merge empty columnstore partitions, which allow you to workaround the limitation and also implement Sliding Window pattern and use partitioning to purge the data.
The Sliding Window pattern stands for scenario when we want to retain the data for some period of time. Consider the situation when we need to keep last 12 months of data. In the beginning of each month, we may purge the data that is older than 12 months, basically having a window on the data that slides purging the oldest data, based on a given schedule.
Data partitioning is great in this scenario. It allows to keep the purge process on metadata- and minimally logged-levels by switching the old-data partition to staging table truncating it afterwards. This helps to avoid log-intensive DELETE operations and reduce blocking in the system.
Let’s look at implementation. First, I would create partition function and scheme considering that now is November 2017 and we would need to retain 12-month of data starting November 2016.
create partition function pfOrders(datetime2(0))
as range right for values
('2016-11-01','2016-12-01','2017-01-01','2017-02-01'
,'2017-03-01','2017-04-01','2017-05-01','2017-06-01'
,'2017-07-01','2017-08-01','2017-09-01','2017-10-01'
,'2017-11-01','2017-12-01','2018-01-01');
create partition scheme psOrders
as partition pfOrders
all to ([Primary]);
This code will create 16 partitions. The left-most partition will host the data prior 2016-11-01 and it will be empty. The two right-most partitions will host the data for December 2017 and everything starting on 2018-01-01. They also will be empty at this point.
There is the simple reason why we want to have two right-most partitions empty. Let’s assume that we will run the monthly purge process in December and December’s partition will already store some data. As part of the purge process, we would like to create the new partition for the “next month” data. It is beneficial to perform this and split partition function on empty partition. With B-Tree tables, it is nice to have implementation. It allows to avoid any data scans and movements reducing the time for schema modification lock being held. For columnstore indexes, this is actually the must have part of design – you would be unable to split non-empty partition at all.
If you ever implemented Sliding Window pattern with B-Tree indexes, you would be aware of empty right-most partition. However, you might notice that in our example, there is also empty left-most partition present. As I already mentioned, columnstore indexes would not allow you to merge non-empty partitions and you need to have an extra empty partition to perform the merge after old data is purged.
Let’s look at the process in details. As the first step, I will create two tables that will share the partition function and scheme. We will populate them with some data and create the columnstore indexes on the tables.
create table dbo.Orders ( OrderDate datetime2(0) not null, OrderId int not null, Placeholder char(100), ) on psOrders(OrderDate); create table dbo.OrderLineItems ( OrderDate datetime2(0) not null, OrderId int not null, OrderLineItemId int not null, Placeholder char(100), ) on psOrders(OrderDate); -- Left-most and right-most are empty ;with N1(C) as (select 0 union all select 0) -- 2 rows ,N2(C) as (select 0 from N1 as t1 cross join N1 as t2) -- 4 rows ,N3(C) as (select 0 from N2 as t1 cross join N2 as t2) -- 16 rows ,N4(C) as (select 0 from N3 as t1 cross join N3 as t2) -- 256 rows ,N5(C) as (select 0 from N4 as t1 cross join N4 as t2) -- 65,536 rows ,Ids(Id) as (select row_number() over (order by (select null)) from N5) insert into dbo.Orders(OrderDate, OrderId) select dateadd(day,Id % 390,'2016-11-01'), ID from Ids; insert into dbo.OrderLineItems(OrderDate,OrderId, OrderLineItemId) select OrderDate, OrderId, OrderId from dbo.Orders; create clustered columnstore index CCI_Orders on dbo.Orders on psOrders(OrderDate); create clustered columnstore index CCI_OrderLineItems on dbo.OrderLineItems on psOrders(OrderDate);
The next listing returns data distribution and allocation information for dbo.Orders table.
select t.object_id, i.index_id, i.name as [Index], p.partition_number, p.[Rows], p.data_compression_desc, fg.name as [Filegroup], sum(a.total_pages) as TotalPages, sum(a.used_pages) as UsedPages, sum(a.data_pages) as DataPages, sum(a.total_pages) * 8 as TotalSpaceKB, sum(a.used_pages) * 8 as UsedSpaceKB, sum(a.data_pages) * 8 as DataSpaceKB from sys.tables t with (nolock) join sys.indexes i with (nolock) on t.object_id = i.object_id join sys.partitions p with (nolock) on i.object_id = p.object_id AND i.index_id = p.index_id join sys.allocation_units a with (nolock) on p.partition_id = a.container_id join sys.filegroups fg with (nolock) on a.data_space_id = fg.data_space_id where t.object_id = object_id(N'dbo.Orders') group by t.object_id, i.index_id, i.name, p.partition_number, p.[Rows], p.data_compression_desc, fg.name order by i.index_id, p.partition_number;
Figure 1 illustrates the output of the listing. As you can see, data is distributed across 13 partitions with left-most and two right-most partitions empty.
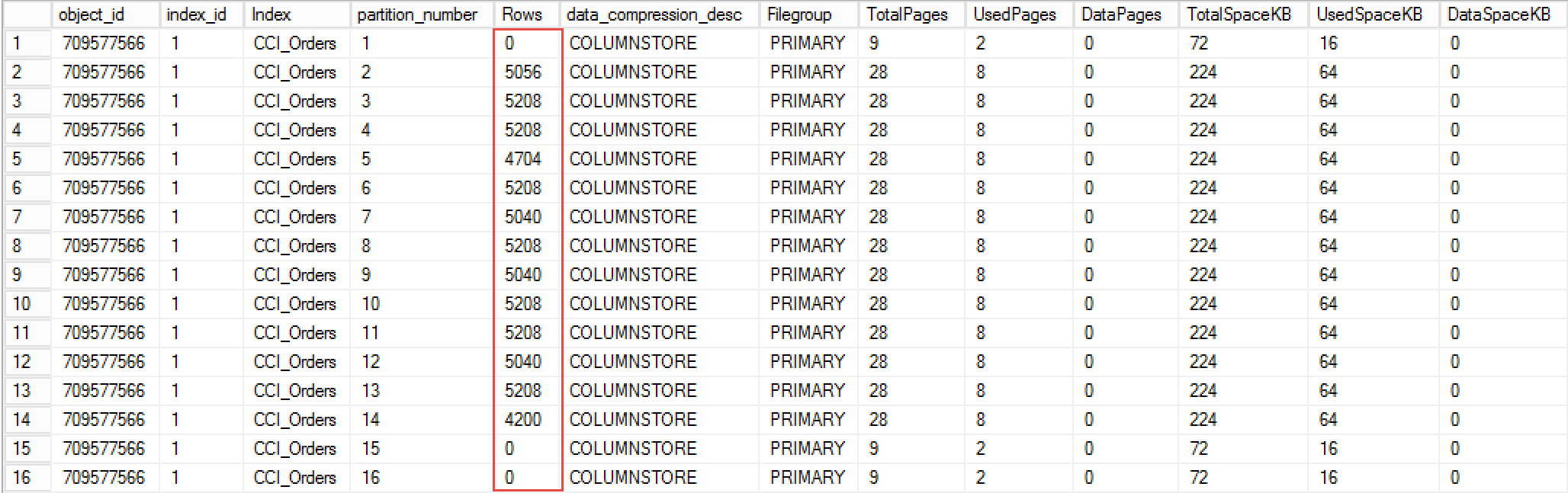
01. Data Distribution And Allocation Information
Let’s try to split non-empty partition, just for the demo purposes
alter partition scheme psOrders next used [Primary];
alter partition function pfOrders()
split range ('2017-11-15');
As expected, it would not work with the error message shown below.

02.Split Non-Empty Partition
The merge of non-empty partition would also fail.

03.Merge Non-Empty Partition
Fortunately, we can split an empty partition. Again, let’s assume that we want to start purging process in December. I would insert a couple rows to December’s partitions making them non-empty.
insert into dbo.Orders(OrderDate, OrderId) values('2017-12-02',100000);
insert into dbo.OrderLineItems(OrderDate,OrderId, OrderLineItemId) values('2017-12-02',100000,100000);
Let’s create another empty partition by splitting partition function. The right-most partition is still empty and operation would succeed. As result, we will have separate empty partitions for January, 2018 and another partition that will store all data starting 2018-02-01. We will split the right-most empty partition again during our January’s 2018 purge process.
alter partition scheme psOrders next used [Primary];
alter partition function pfOrders()
split range ('2018-02-01');
The process of purging old data would consist of several steps. First, we need to create the staging tables to which we will switch old November 2016 partitions. Those tables need to be empty, have exactly the same schema with the main tables and reside on the same filegroup.
create table dbo.OrdersTmp ( OrderDate datetime2(0) not null, OrderId int not null, Placeholder char(100), ) on [Primary]; create clustered columnstore index CCI_OrdersTmp on dbo.OrdersTmp on [Primary]; create table dbo.OrderLineItemsTmp ( OrderDate datetime2(0) not null, OrderId int not null, OrderLineItemId int not null, Placeholder char(100), ) on [Primary]; create clustered columnstore index CCI_OrderLineItemsTmp on dbo.OrderLineItemsTmp on [Primary];
After tables were created, we can switch November 2016 partitions there truncating staging tables afterwards. Remember that in the main tables, November 2016 is the second left-most partition.
alter table dbo.Orders switch partition 2 to dbo.OrdersTmp; alter table dbo.OrderLineItems switch partition 2 to dbo.OrderLineItemsTmp; truncate table dbo.OrdersTmp; truncate table dbo.OrderLineItemsTmp;
If you look at dbo.Orders allocation information again, you would see that two left-most partitions are now empty as shown in Figure 4

04. Data Distribution And Allocation Information After Purge
Now they can be merged, which will complete our implementation.
alter partition function pfOrders()
merge range('2016-11-01');
As you can see, implementation of Sliding Window pattern with columnstore indexes is very similar to B-Tree tables. The only differences are:
- You must have empty right-most partition pre-allocated to perform the split. I’d like to reiterate that even though it is not required with B-Tree indexes, such empty partition would reduce I/O overhead and table locking during split operation there.
- You must have another empty left-most partition to perform the merge. This is not required nor needed with B-Tree indexes.
I’d like to thank Ned Otter (blog) for his suggestions and feedback. They convinced me to blog on the subject.
Source code is available for download.
Next (2017-11-29): Splitting and Merging Non-Empty Partitions in Columnstore Indexes