After my last post I’ve received a couple emails asking how did I fix the problem. Just to remind – data spilled out to the right-most partition of the table and as result sliding window scenario did not work anymore. When process tried to split right-most, non-empty partition, it obtained long-time schema modification (SCH-M) lock. And then start to scan/move data while all access to the table was blocked. Today we are going to discuss how to fix that.
The most important question is if we can put the system offline during that operation. If this is not the case, well, our life becomes much more complicated. And our options for online recovery are rather limited. Let’s take a look. First, I would create partition function, scheme, table and populate it with some data with ID between 1 and 1250.
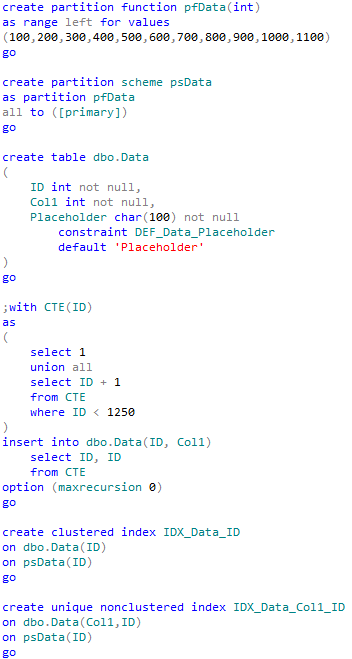
As you can see, I duplicated the case we had – we spilled out some data to the right most partition (with ID > 1100) which should be empty.
Let’s create another correct partition function and scheme:

For online recovery we can re-create our indexes online moving them to another partition. I’m doing it as part of transaction just to roll everything back to the initial “invalid” stage.

This operation would run with the minimal locking and achieve our goal. There are 3 things worth to mention though. First – online index rebuild uses row versioning and as result you will introduce quite heavy tempdb usage during that operation. Next, we are “rebuilding” much more data than actually needed – think about it – we have just one (right most) partition that needs to be recreated but we are rebuilding entire table. But more critical for us that this approach would not work if you have primary key constraint defined on the table. Unfortunately there is no way to recreate constraint moving it to another partition. Basically it means that you would not be able to resolve the issue without putting your system offline. Well, to be exact, if you have non-clustered primary key you can replace it with unique non-clustered index if this is acceptable. But still..
So what can we do with the primary key constraint? First, let’s prepare our table. As the side note – I’m disabling non-clustered index to prevent extra rebuild when we drop the clustered index.
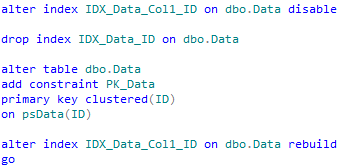
As I mentioned before, we would not be able to do the operation without putting system offline. The goal though is to reduce offline time as well as to process/move as little data as possible (our right most partition only).
First of all, let’s create another table with indexes using new (corrected) partition scheme.
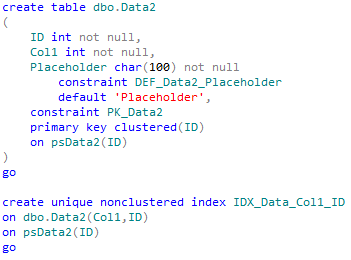
The problem here is that new table should have exactly the same physical row structure with the old one. And if you dropped or altered any column in the old table, your physical structure would not match table definition. If this is the case, you’ll need to create and alter the new table in the same way. Simplest way to compare is to run the following statement after new table is created.
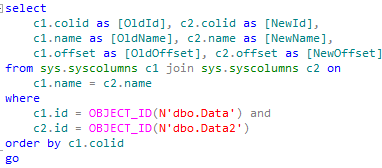
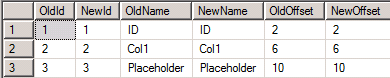
I strongly suggest to test that you did not miss anything with the latest backup. Otherwise you could end up in the nasty situation when your data spread across multiple tables.
Anyway, assuming everything is fine our action plan would be:
- Copy all data from invalid partition(s) from Data to Data2. Let’s say that step starts at time T1.
- Apply all data changes that happened between T1 and now. Assuming that step starts at time T2. This step is optional but it would reduce downtime
- Put system offline
- Apply all changes from Data that happened between T2 and now. No new changes would be done in Data during this step because system is offline
- Switch all “normal” partitions from Data to Data2
- At this point Data would have only right-most incorrect partition, Drop (or rename) the table.
- Rename Data2 to Data (including constraints)
- Bring system online
Obviously one of the questions is how to find what is changing in the table while we are running steps 1 and 2. Well, it depends, of course. If you have identity or sequence keys, you can use them to track inserts. For updates – you can log time of update – perhaps by creating the new column and populating it with the trigger. For deletions – trigger again. Let’s do our prep work. I assume in that example that we are using sequences (or identity) for inserts. First – updates.
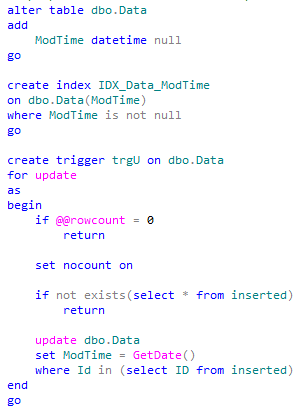
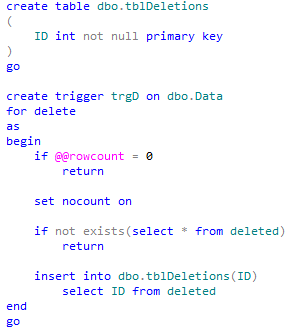
Now deletions. I’m using very simple approach here and going to apply all deletions at once during step 4.
Now we are ready to go. At the beginning of the step 1 we will log our ID and time to use it later.
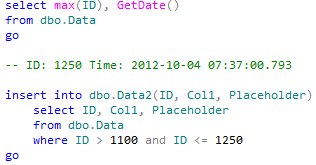
This step would be quite time consuming and depend on amount of data we are copying. I’m also going to emulate some update activity in Data.
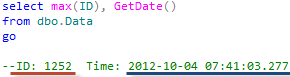
Now we need to apply changes in the original table that were made during step 1. Generally speaking, we can skip this step because we are going to do that again later when system is offline. But remember – our system is still online and this step would reduce downtime. In fact, if you have heavy activity you’d probably like to run this step again a few times.
As I mentioned before – I’m going to cut a corner here and don’t deal with deletions during that step. Again, we need to log ID and current time at the beginning of this step.
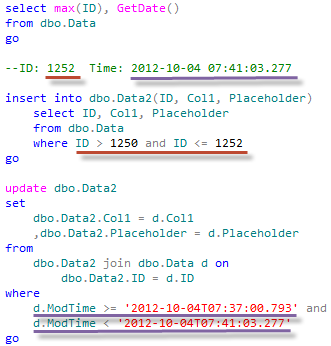
Again, I’m emulating some update activity in the system
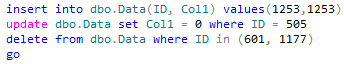
Now it’s time to put system offline. And if your system is truly offline at this point, it’s also the good idea to create database snapshot to be able to “rollback” the changes.
So let’s apply all updates again including deletion activity.

Now we are almost ready to switch partitions. Only thing we need to do before is dropping our ModTime column and index we created.
![]()
And now the key part – switch and rename.
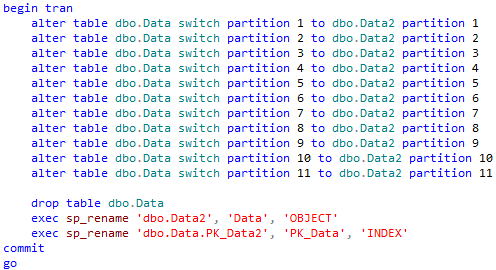
Now we can bring the system online and do the final clean up.

As you can see, the process is a bit complex. But at the end it minimizes the downtime. One thing to keep in mind – partition scheme and functions have been recreated under the new name so you need to take care of the code that references the old ones. SQL Search is your friend here.
While problem is fixed now the best way to deal with such kind of problems is don’t have them at all. As I mentioned before – all of that could be avoided if the size of partition has been re-evaluated from time to time.
The source code is available for download