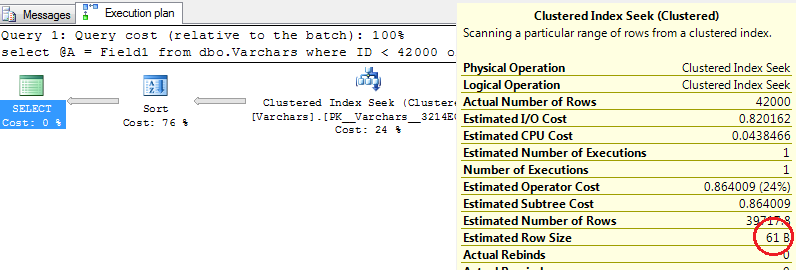
Last time we saw that TVP is the clear winner in compare with separate insert calls. Obviously this is not an option with SQL 2005. So let’s see what can we do there.
We’re trying to accomplish 2 things:
- Make save process faster
- Minimize transaction duration
XQuery
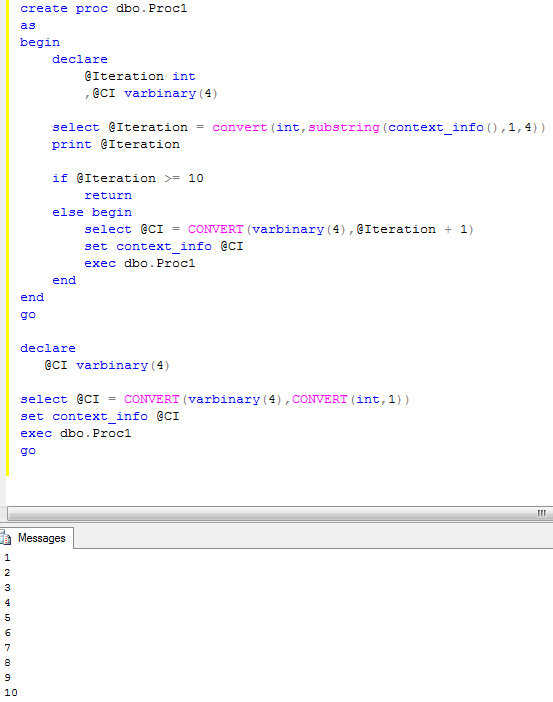
Let’s start with element-centric xml. Let’s create the following procedure:

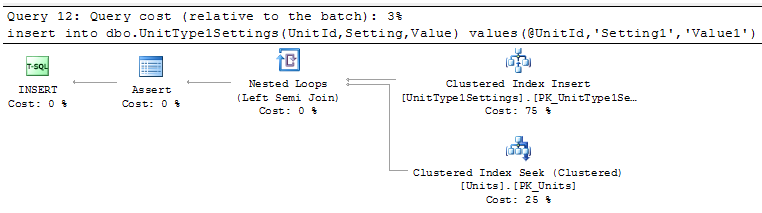
Now let’s run our tests again. For 5,000 records avg. time is about 8 seconds. For 50,000 records avg time is about 82-84 seconds. Quite surprising results. Let’s take a look at the execution plan.
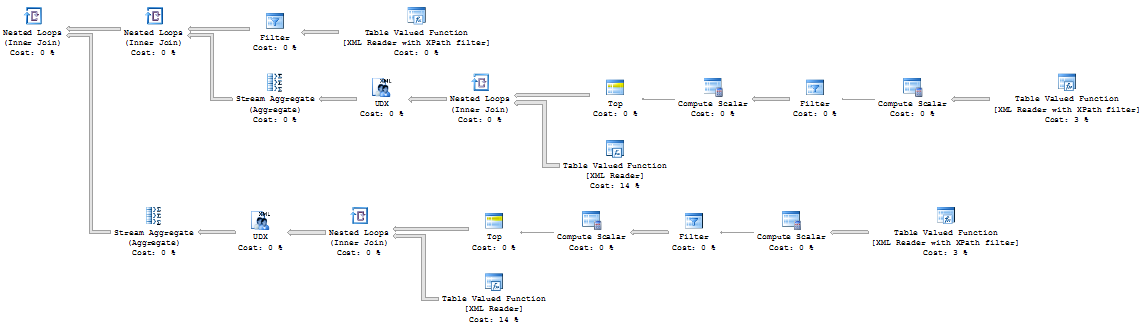
As you can see, SQL Server basically does the join for every element/column in the XML packet. Obviously – more elements/columns you have – more joins it would produce and slower performance would be.
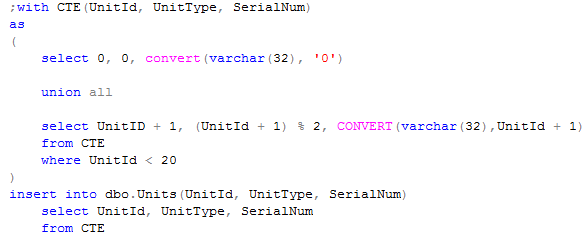
Let’s check attribute-centric XML. Procedure would look almost the same:

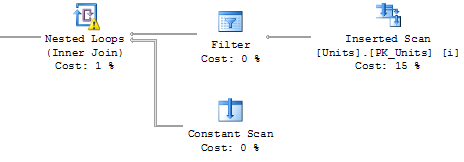
For 5,000 records avg. time is about 2,7 seconds. For 50,000 records avg time is about 27-28 seconds. Better, but still slower than classical inserts. Plan also looks slightly better, but still, it uses the same approach with joins.
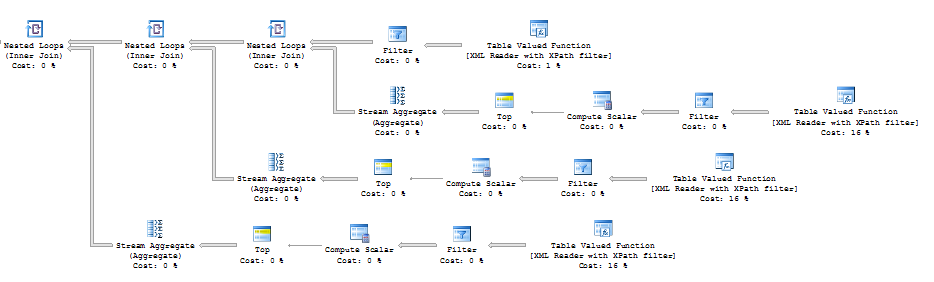
So as we can see, XQUERY performance greatly depends on the number of columns/joins.
OpenXML
Well. Only other option left with XML is OpenXML. Let’s modify our procedure and run our tests

For 5,000 records avg. time is about 1,4 seconds. For 50,000 records avg time is about 14-15 seconds. As you can see, results are much better – even better than classical approach. Only minor problem with this approach – memory. MSXML parser uses one-eights of the total memory available for SQL Server. Huh?
Temporary table approach
So looks like we’re out of luck. Only option which is faster than classical inserts is OpenXML and we cannot use it unless memory is completely not an issue.
Although let’s think what can be done if our main problem is not the performance but concurrency. With classical approach and multiple inserts in the one transaction, we will place first exclusive lock on the new row with the first insert. In some cases we cannot simply afford to keep locks on the rows for a few seconds.
If this is the main issue, we can insert data to the temporary table first and just move it to the main table in one short transaction. If we update our attribute-centric insert stored procedure and insert data to the temporary table variable first, it would increase execution time for 200-300 milliseconds (for 5000 records) although transaction duration would be just 30-40 milliseconds. I’m not posting the code here but it’s available for download.
If we have a lot of columns and xquery is not an option, we can use temporary table created on the connection level. Temporary tables are available through the execution stack – so if you create temporary table on connection level (After SqlConnection.Open() call, for example), you should have access to the table from any stored procedure called in the same connection context. As result, implementation could include 2 steps:
- Save data to the temporary table with separate insert statements
- Move data from the temporary to permanent tables in one transaction
Script and sources are available for download – “Refactoring for Performance” presentation from SQL Saturday #62